
新晋诺奖得主曾警告:别做梦了,AI难有「经济奇点」!
新晋诺奖得主曾警告:别做梦了,AI难有「经济奇点」!从蒸汽机到AI,自动化进程已持续两百年。在2017年,新晋诺奖得主Philippe Aghion就剖析AI对就业与增长的影响,强调它并非奇点催化剂,而是受「鲍莫尔成本病」制约的工具。
来自主题: AI资讯
7613 点击 2025-10-17 15:49
 搜索
搜索
从蒸汽机到AI,自动化进程已持续两百年。在2017年,新晋诺奖得主Philippe Aghion就剖析AI对就业与增长的影响,强调它并非奇点催化剂,而是受「鲍莫尔成本病」制约的工具。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。
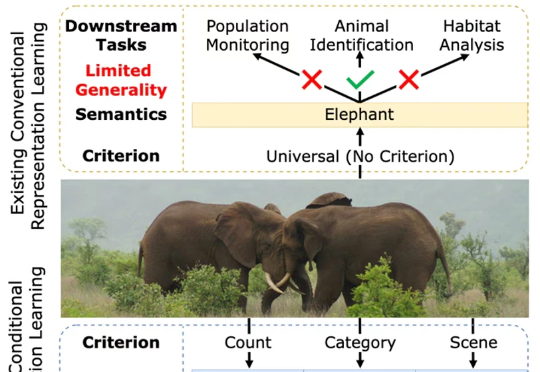
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。
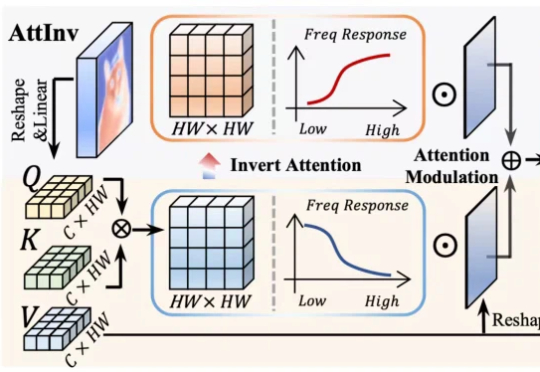
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。
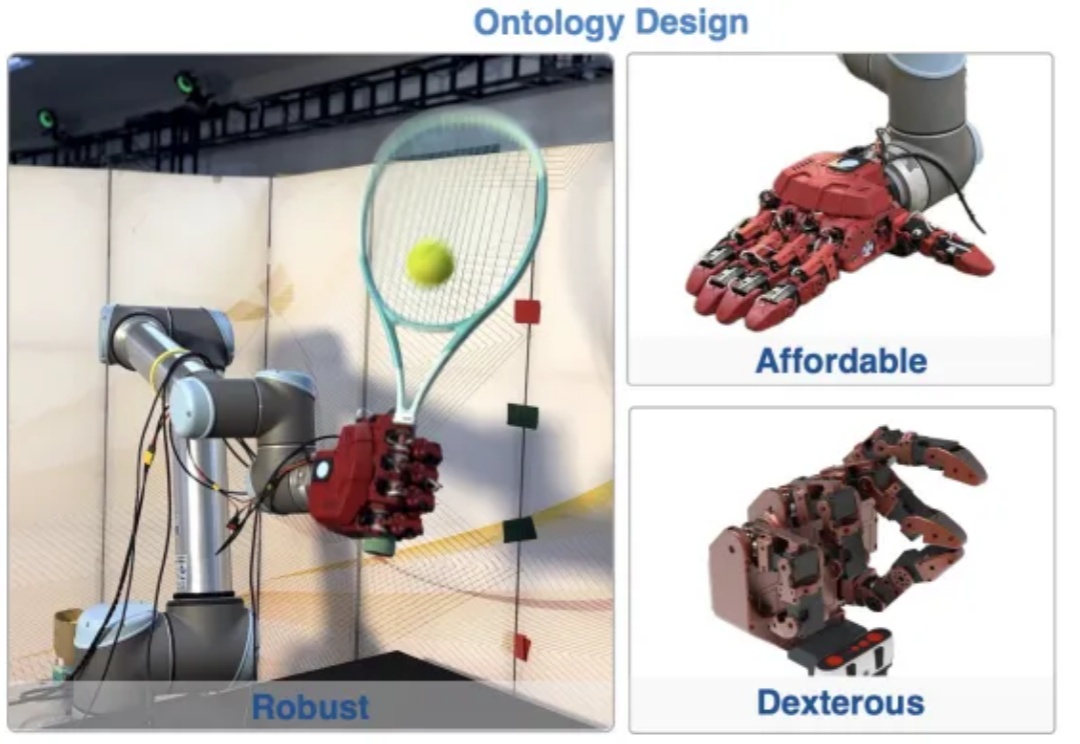
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。

数据显示,仅2025年开年以来,美国已有超过一万个岗位因为引入AI而被裁撤。Anthropic CEO Dario Amodei认为AI技术的扩散对就业和社会的冲击,已经到了必须向全世界预警的地步。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。

OPPO新一代AIOS来了!ColorOS 16当中,“一键闪记”和“一键问屏”两项功能有了新玩法。你点餐时产生的取餐码和账单,只要按下按钮就能帮你记住,不用再忘记之后反复查找。

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
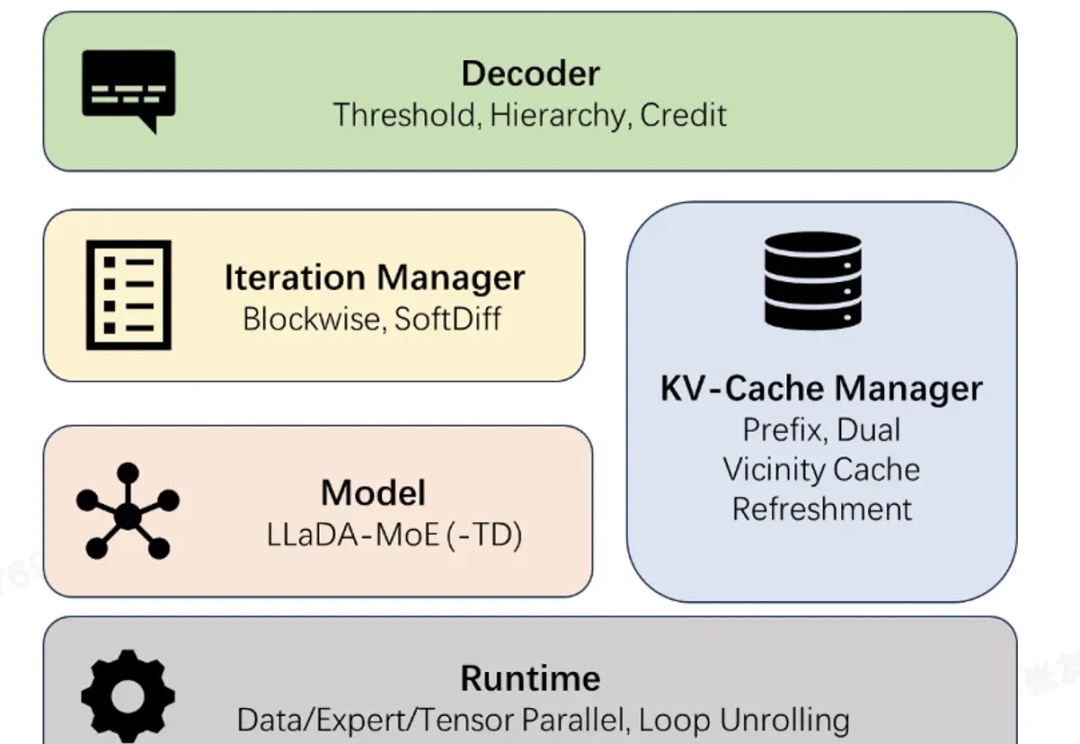
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。