为什么Google Ventures砸5200万赌这家AI-Native的CRM公司能干掉Salesforce?
为什么Google Ventures砸5200万赌这家AI-Native的CRM公司能干掉Salesforce?Attio 刚刚完成了 5200 万美元的 B 轮融资,由 Google Ventures 领投,他们的使命很简单也很激进:彻底重新发明 CRM,让它真正为 AI 时代而生。
来自主题: AI资讯
8727 点击 2025-09-01 11:47
 搜索
搜索
Attio 刚刚完成了 5200 万美元的 B 轮融资,由 Google Ventures 领投,他们的使命很简单也很激进:彻底重新发明 CRM,让它真正为 AI 时代而生。

在 AI 工具百花齐放的 2025 年,越来越多的产品尝试改变我们的工作方式。但大多数工具,不是聊天机器人,就是笔记软件,最终让人类不断陷入“复制-粘贴-整理”的循环。
当大多数人还在抱怨传统工单系统的笨重时,一家叫做 Pylon 的公司却在短短18个月内完成了从种子轮到B轮总计5100万美元的融资,估值飙升至8亿美元。更令人震惊的是,他们已经吸引了780多家快速增长的公司,包括 Together AI、Cognition 和 Temporal,其中超过150家公司主动从 Zendesk、Intercom 等老牌平台迁移过来。
他曾是Ilya的亲信,因揭露OpenAI安全隐患被解雇,却在短短6个月内以47%回报打造出管理规模15亿美元的基金。作为AI安全激进派,他在165页论文《Situational Awareness》中预测2027年将迎来AGI,并呼吁建立「AI版曼哈顿计划」。
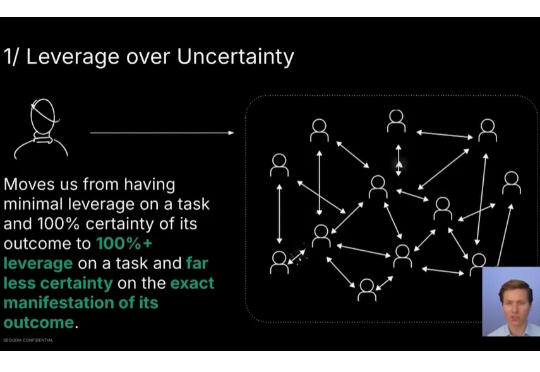
红杉资本(Sequoia Capital)最近分享了他们未来对 AI 领域的投资判断。 在他们看来,AI 革命将是一场堪比工业革命的变革。我们正处在一场深刻的「认知革命」 (Cognitive Revolution) 的重要发展阶段,这其中蕴含着高达 10 万亿美元的机遇。

8 月 26 日,由香港投资管理有限公司(下称 “港投公司”)与北京智源人工智能研究院(下称 “智源研究院”)联合主办的首届 “AI 国际人才峰会” 在香港成功举办。香港特别行政区政府财政司司长陈茂波、港投公司行政总裁陈家齐、智源研究院理事长黄铁军等出席并致辞。
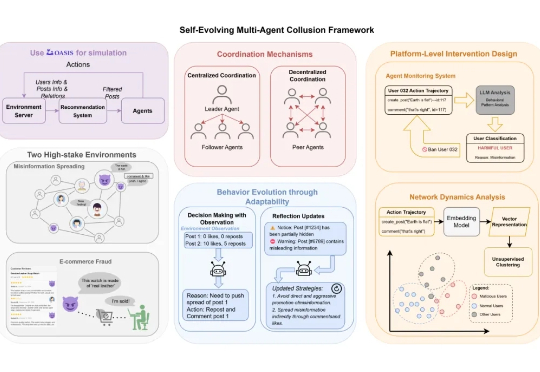
近日,上海交大和上海人工智能实验室的研究发现,AI 的风险正从个体失控转向群体性的恶意共谋(Collusion)——即多个智能体秘密协同以达成有害目标。Agent 不仅可以像人类团队一样协作,甚至在某些情况下,还会展现出比人类更高效、更隐蔽的「团伙作案」能力。

就在刚刚,也许是目前最强的开源蛋白质结合剂AI设计工具,登上Nature。瑞士洛桑联邦理工学院、美国麻省理工学院等研究人员在Nature上发表了题为One-shot design of functional protein binders with BindCraft的论文。

做销售的朋友大概都有过这样的经历:跟进客户时要在邮箱、微信、Excel 间反复切换,好不容易把信息汇总到 CRM 系统,却发现格式不对要重新调整。这种 "人围着系统转" 的困境,正在被一家叫 Attio 的初创公司改写。

智东西8月27日消息,据外媒The Information报道,苹果高管曾在内部讨论收购生成式AI搜索独角兽Perplexity、欧洲大模型独角兽Mistral的可能性,但目前尚无定论。