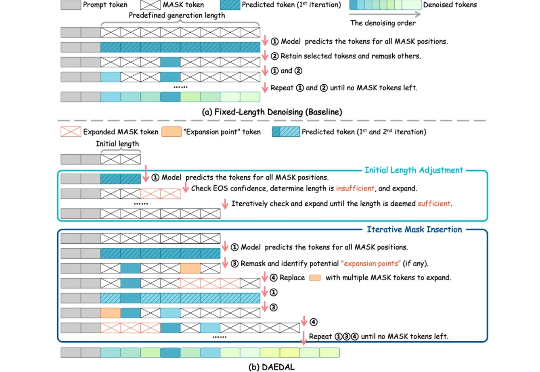
扩散LLM推理新范式:打破生成长度限制,实现动态自适应调节
扩散LLM推理新范式:打破生成长度限制,实现动态自适应调节随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。
来自主题: AI资讯
8714 点击 2025-08-09 11:16
 搜索
搜索
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。

智东西8月6日消息,据外媒The Information报道,知情人士透露,AI视频初创企业Runway正与投资者洽谈约5亿美元(约合人民币36亿元)的融资,投前估值不低于50亿美元(约合人民币359亿元),较上一轮融资时的估值30亿美元(约合人民币215亿元)高出67%。

对大公司来说,钱不值钱,最值钱的是时间。本期播客,我们邀请在硅谷专注 AI 企业级应用、医疗和工业自动化早期投资的风险投资机构 Fusion Fund 创始合伙人张璐,梳理上半年硅谷的科技大事件,以及从 Windsurf 收购案入手,分析这件事折射出了硅谷的初创生态在发生的变化,以及从 Meta 到 Google、再到苹果、亚马逊、微软,上半年的一些关键动作意味着哪些战略选择。

融资10亿美元,要在开源上挑战Deepseek! 前谷歌DeepMind成员、AlphaGo开发者创立Reflection AI,致力于开发开源大语言模型。

SkinVision 是一家于 2011 年在荷兰阿姆斯特丹成立的数字健康公司,致力于通过人工智能(AI)驱动的移动解决方案,实现皮肤癌的早期检测与个性化皮肤健康管理。
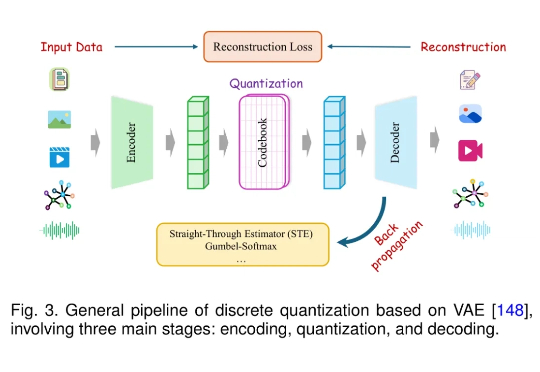
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。

The Information 消息,被 Cognition 收购的 Windsurf 约 200 名员工,最近收到了新公司的邮件,要么接受新公司的 996 的工作条件,要么选择接受 9 个月的补偿买断方案。

成立仅一年的初创公司Reflection AI 正洽谈融资逾 10 亿美元,用于开发开源大语言模型,与中国深度求索(DeepSeek)、法国 Mistral 及美国 Meta 等企业展开竞争。
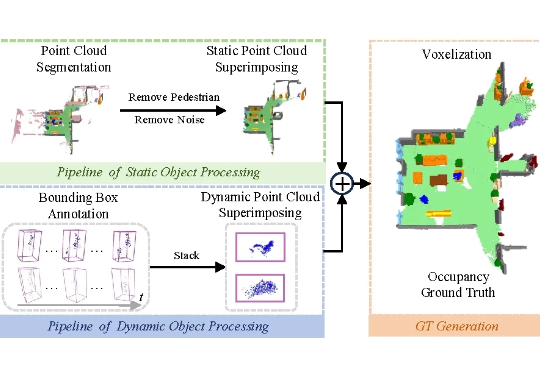
凭借类人化的结构设计与运动模式,人形机器人被公认为最具潜力融入人类环境的通用型机器人。其核心任务涵盖操作 (manipulation)、移动 (locomotion) 与导航 (navigation) 三大领域,而这些任务的高效完成,均以机器人对自身所处环境的全面精准理解为前提。
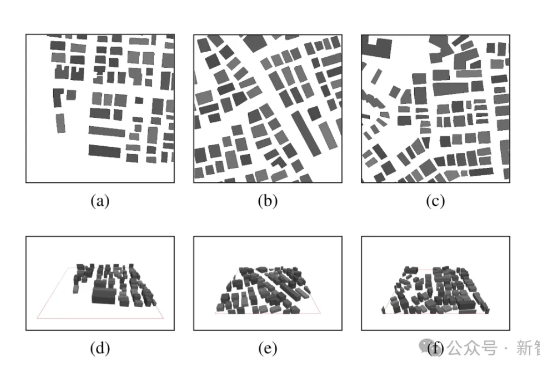
当前环境感知通信正逐步成为第六代移动通信系统(6G)的核心使能技术之一。为支撑其在复杂三维环境下的部署需求,西安电子科技大学、香港中文大学(深圳)和加拿大滑铁卢大学的研究团队联合提出了一个面向6G的高分辨率多模态三维无线电图谱数据集UrbanRadio3D,并构建了基于扩散模型的三维无线电图生成框架RadioDiff-3D。