罗福莉首秀前,小米突然发布!代码全球最强,总体媲美DeepSeek-V3.2【附实测】
罗福莉首秀前,小米突然发布!代码全球最强,总体媲美DeepSeek-V3.2【附实测】今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。
来自主题: AI资讯
9686 点击 2025-12-17 09:41
 搜索
搜索
今天,小米发布并开源了最新MoE大模型MiMo-V2-Flash,总参数309B,激活参数15B。今日上午,小米2025小米人车家全生态合作伙伴大会上,Xiaomi MiMO大模型负责人罗福莉将首秀并发布主题演讲。

破解AI胡说八道的关键,居然是给大模型砍断99.9%的连接线?
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
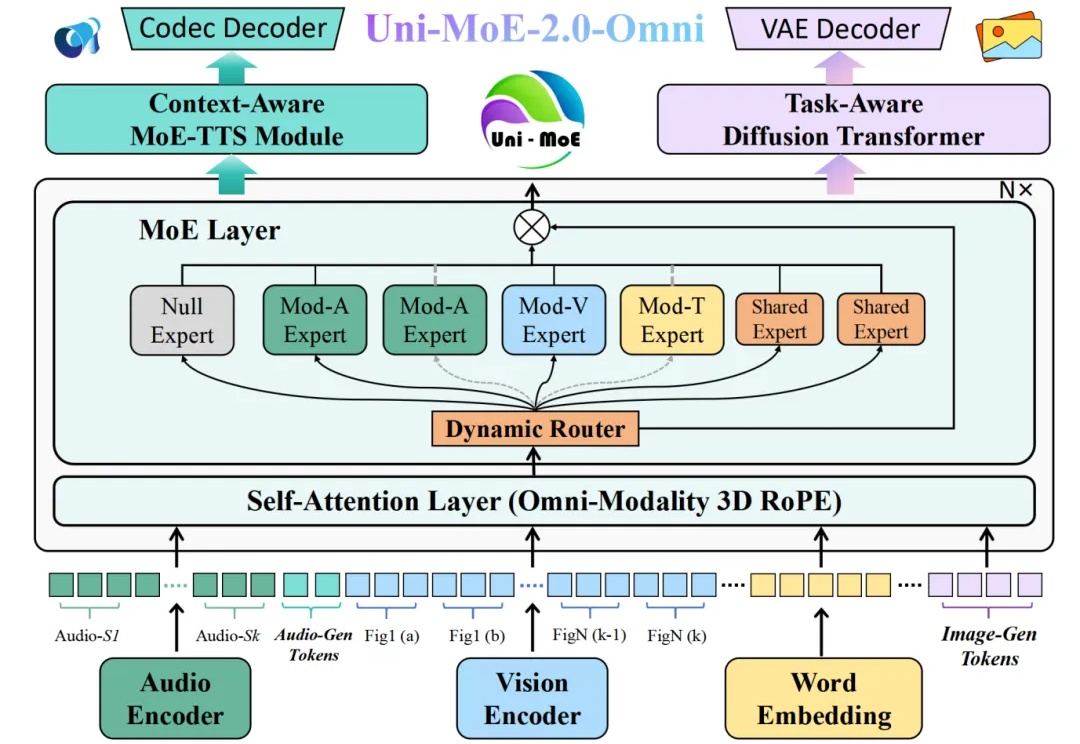
全模态大模型(Omnimodal Large Models, OLMs)能够理解、生成、处理并关联真实世界多种数据类型,从而实现更丰富的理解以及与复杂世界的深度交互。人工智能向全模态大模型的演进,标志着其从「专才」走向「通才」,从「工具」走向「伙伴」的关键点。
昨天,DeepSeek 在 GitHub 上线了一个新的代码库:LPLB。

继轻量级强化学习(RL)框架 slime 在社区中悄然流行并支持了包括 GLM-4.6 在内的大量 Post-training 流水线与 MoE 训练任务之后,LMSYS 团队正式推出 Miles——一个专为企业级大规模 MoE 训练及生产环境工作负载设计的强化学习框架。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。
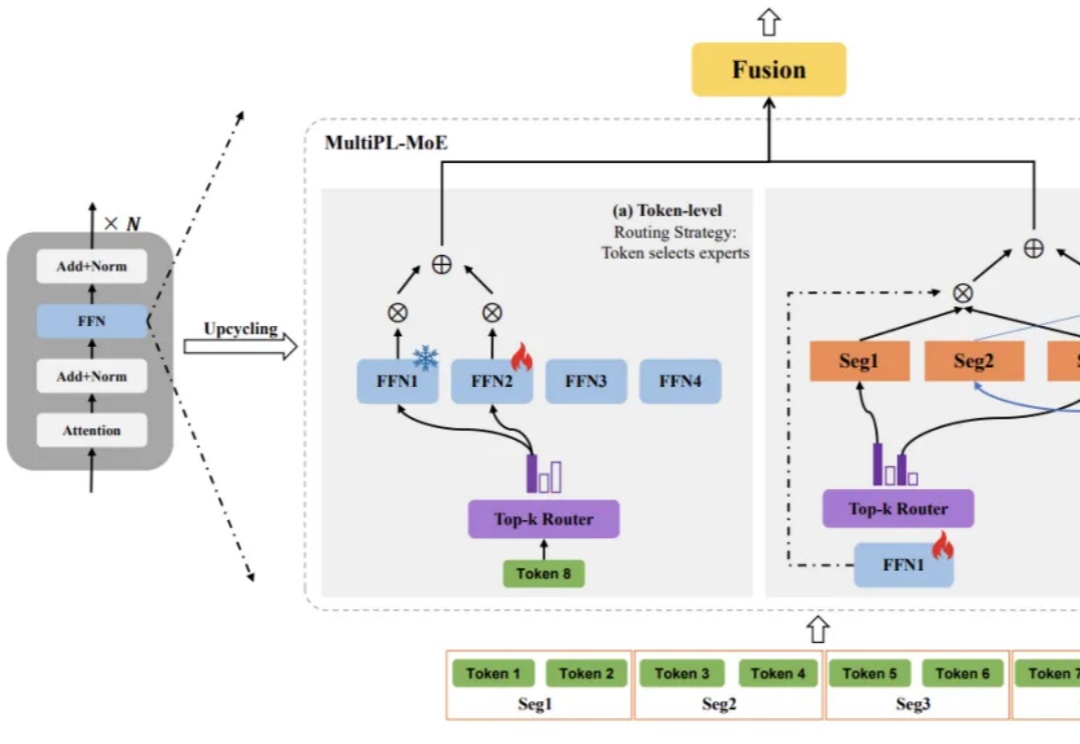
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%