上交大o1复现新突破:蒸馏超越原版,警示AI研发"捷径陷阱"
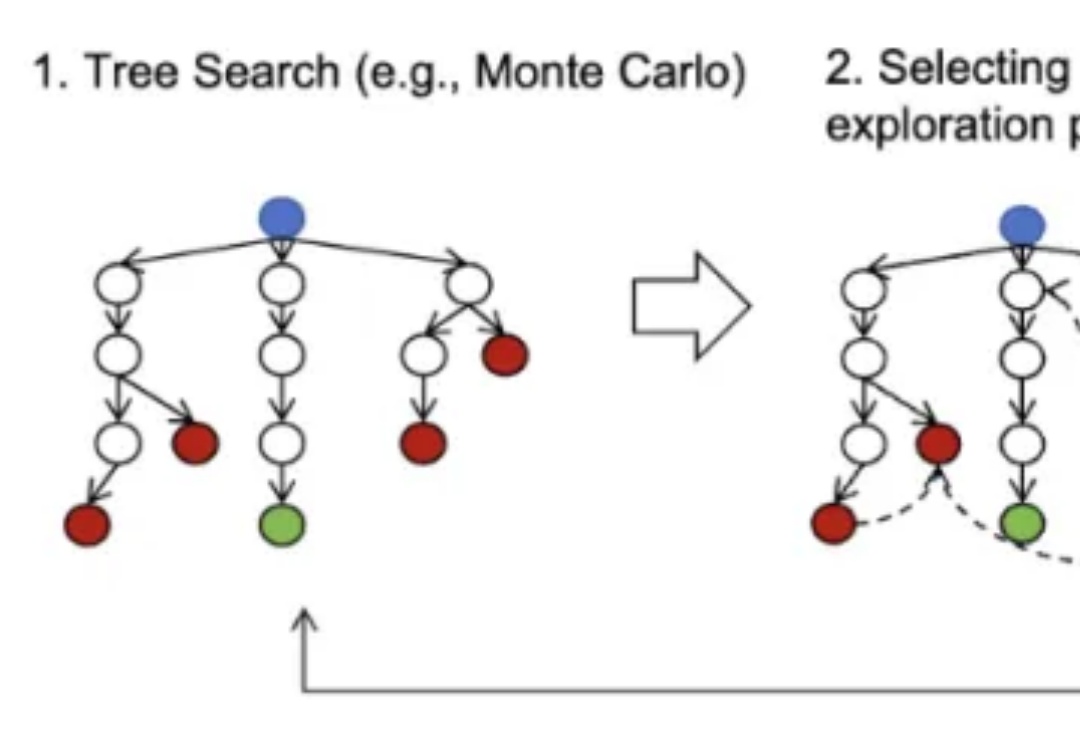
上交大o1复现新突破:蒸馏超越原版,警示AI研发"捷径陷阱"自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
来自主题: AI技术研报
7506 点击 2024-11-22 16:46
 搜索
搜索
自从 OpenAI 发布展现出前所未有复杂推理能力的 o1 系列模型以来,全球掀起了一场 AI 能力 “复现” 竞赛。近日,上海交通大学 GAIR 研究团队在 o1 模型复现过程中取得新的突破,通过简单的知识蒸馏方法,团队成功使基础模型在数学推理能力上超越 o1-preview。
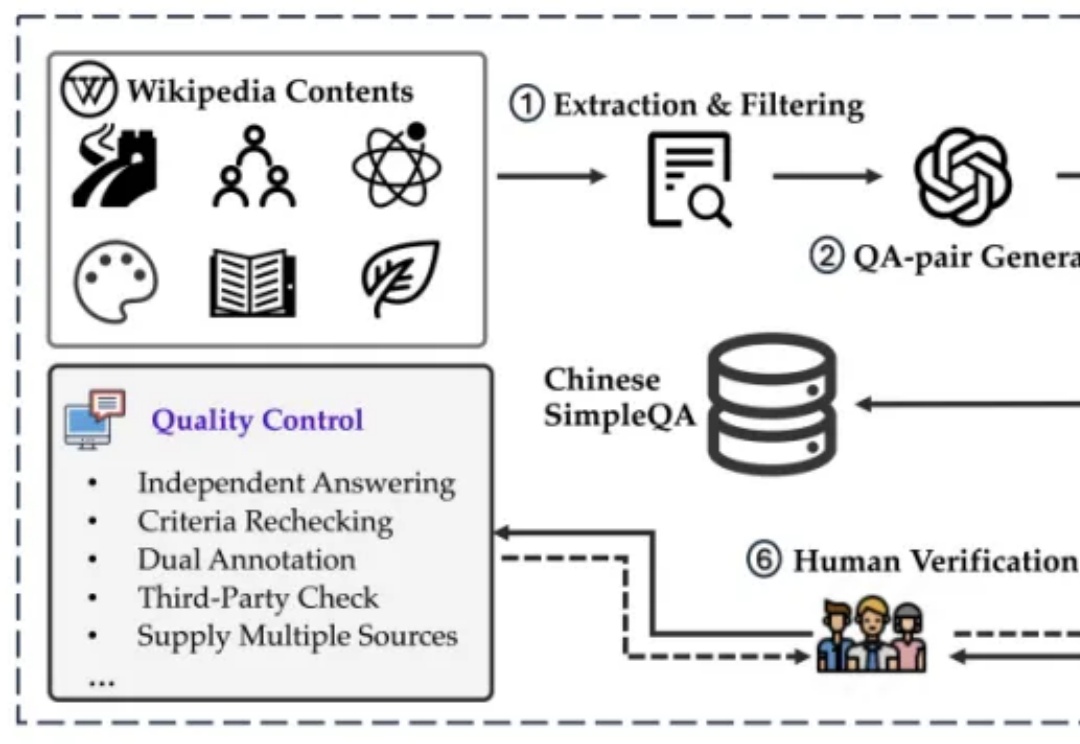
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
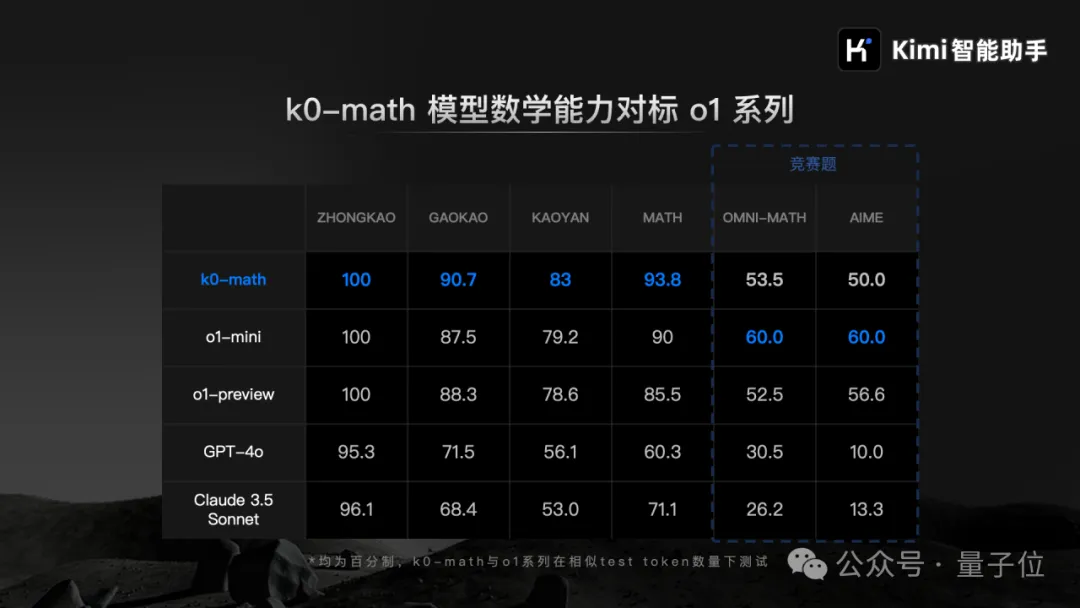
kimi全面开放一周年之际,创始人杨植麟亲自发布新模型—— 数学模型k0-math,对标OpenAI o1系列,主打深入思考。 在MATH、中考、高考、考研4个数学基准测试中,k0-math成绩超过o1-mini和o1-preview。
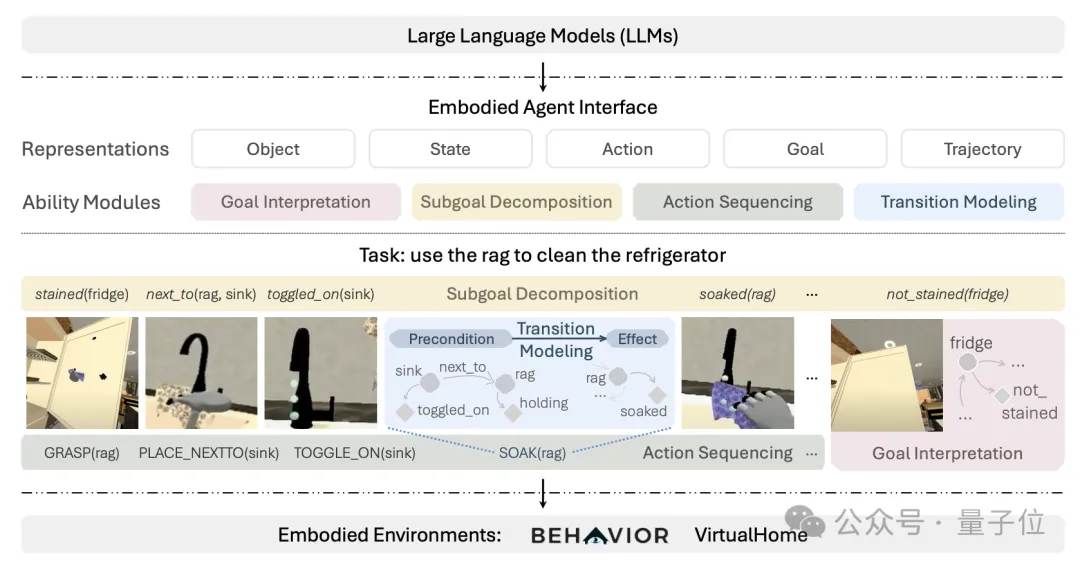
大模型的具身智能决策能力,终于有系统的通用评估基准了。
终于,Windows用户也可以用上ChatGPT了。就在刚刚,OpenAI推出了适用Windows系统的ChatGPT应用。不过,目前仅供ChatGPT Plus、Team、Enterprise和Edu用户使用。
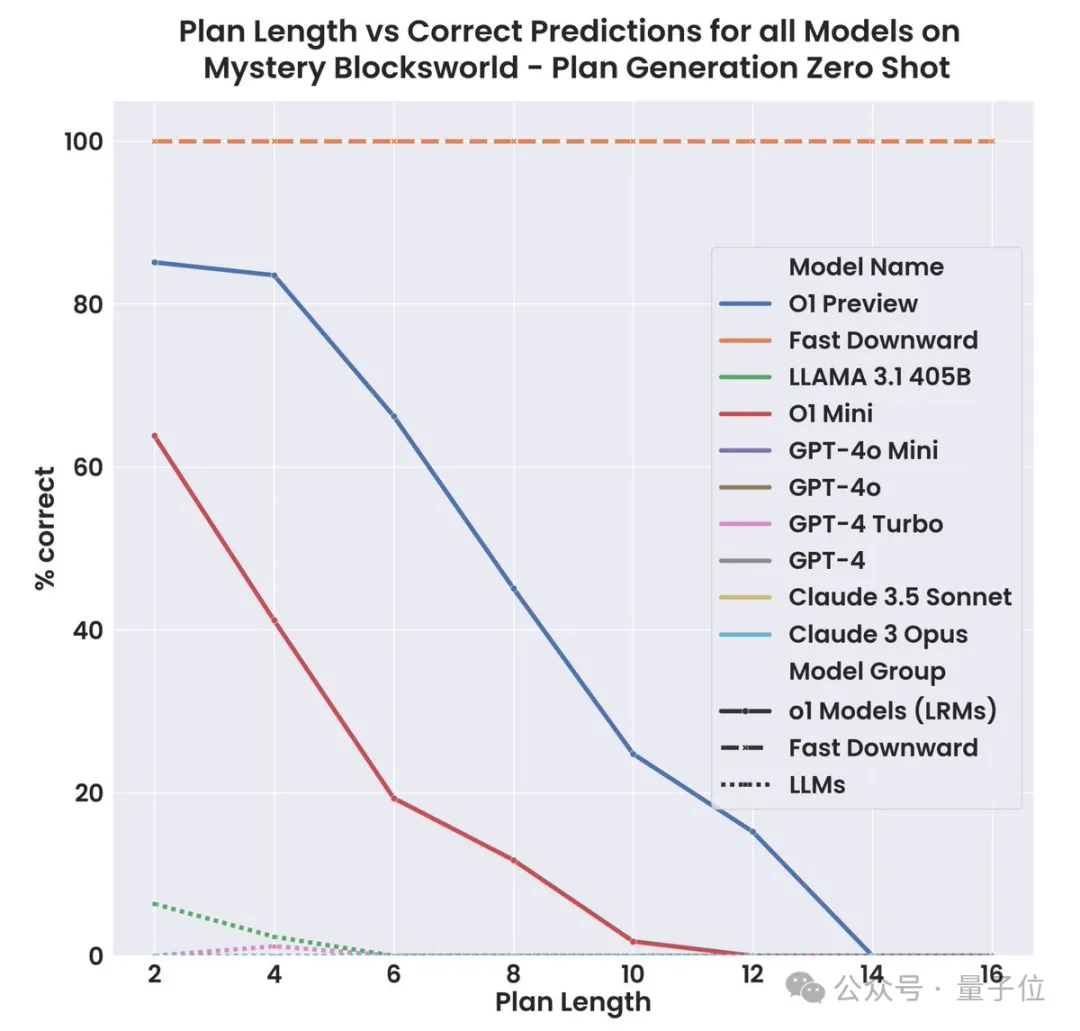
o1-preview终于赢过了mini一次! 亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。
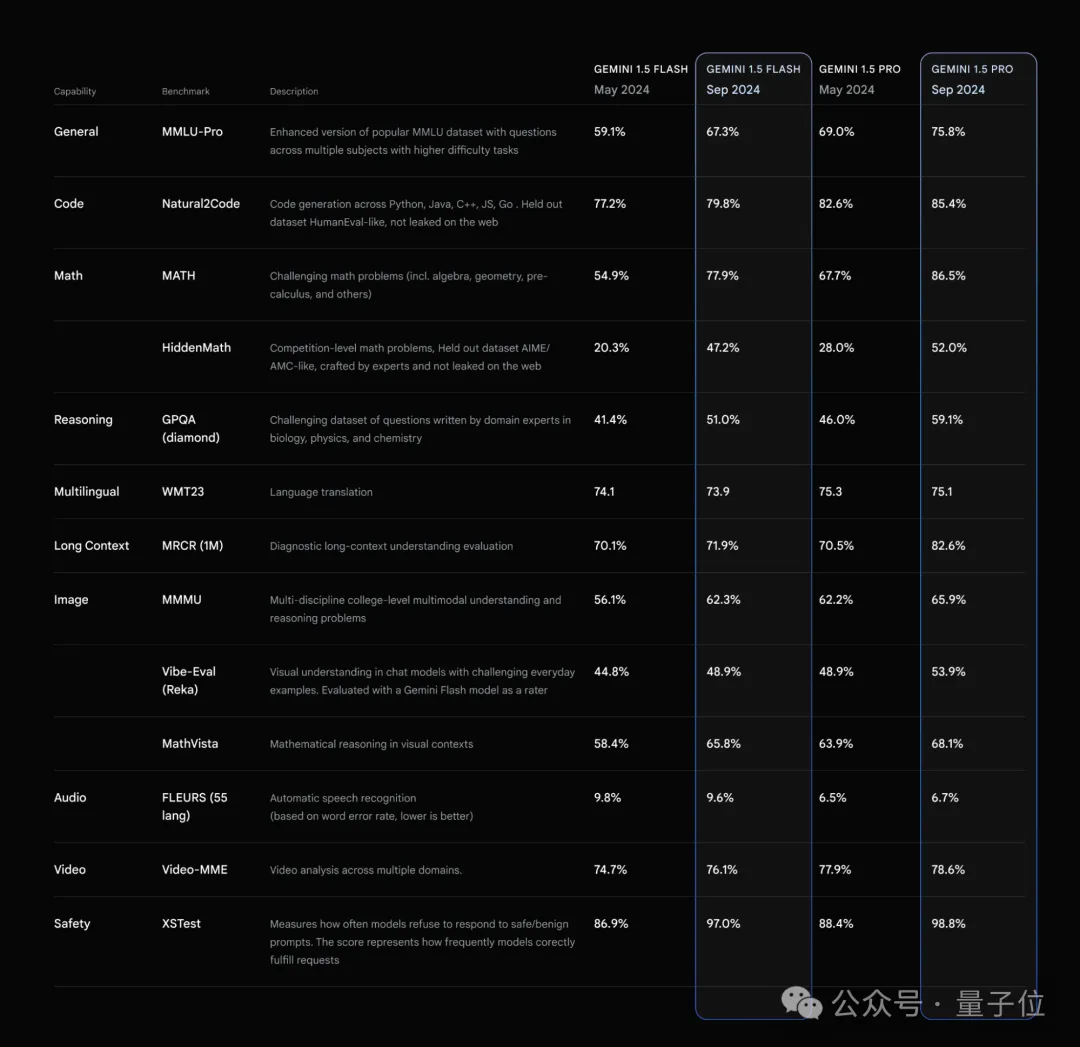
数学击败o1-preview,成本仅为十分之一,并且几乎没有思考延迟!

OpenAI的o1系列一发布,传统数学评测基准都显得不够用了。
随着AI模型的水平不断提高,现有的基准测试也被逐一攻破。CAIS和Scale AI共同发起了属于人类的最后一搏,悬赏50万美元,把最高难度、只有最顶尖的人才能回答出的问题收集起来作为基准,是否能挡住AI模型的攻势?

AI编程技术竞赛加剧