
国内最早的AI大模型公司已经开始亏损了
国内最早的AI大模型公司已经开始亏损了4月25日,昆仑万维发布最新财报,2024年营收56.62亿元,同比增长15.2%,净利润亏损15.95亿元,同比下跌226.8%。这也是上市十年,昆仑万维首度亏损的一年。
来自主题: AI资讯
6679 点击 2025-04-28 09:55
 搜索
搜索
4月25日,昆仑万维发布最新财报,2024年营收56.62亿元,同比增长15.2%,净利润亏损15.95亿元,同比下跌226.8%。这也是上市十年,昆仑万维首度亏损的一年。
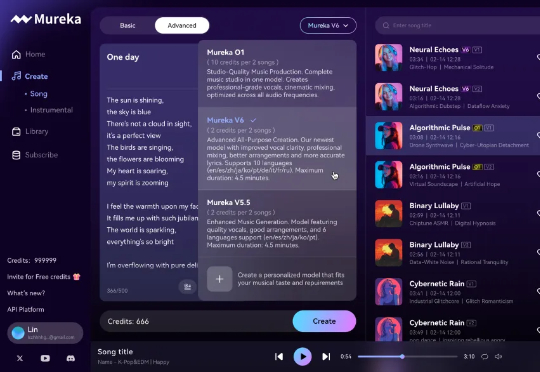
2025 年第一款现象级的 AI 音乐爆品,就这么华丽丽地来了!3 月 26 日,国内「All in AGI 与 AIGC」的科技公司 —— 昆仑万维,发布了最新音乐大模型 Mureka V6 和 O1,给全球音乐圈带来了不小的震撼。
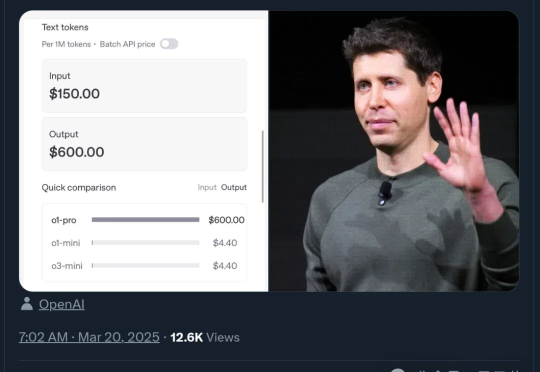
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了!
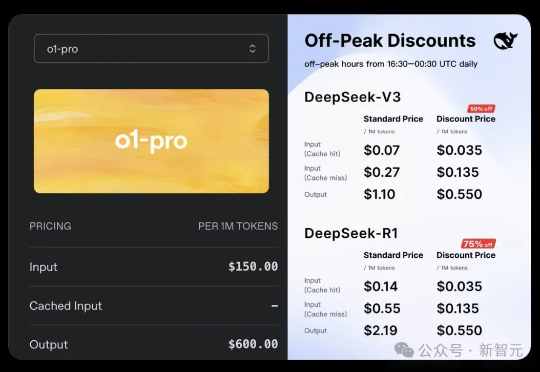
刚刚,OpenAI正式上线史上最贵API——o1-pro,输入/输出价格贵到离谱,最高可达DeepSeek-R1的千倍。OpenAI研究员戏称,大模型界的劳斯莱斯。

今天一大早,ChatGPT突然更新——基于Python的数据分析功能,在o1和o3-mini当中也可以使用了。OpenAI介绍,现在可以通过两款模型调用Python,完成数据分析、可视化、基于场景的模拟等任务。
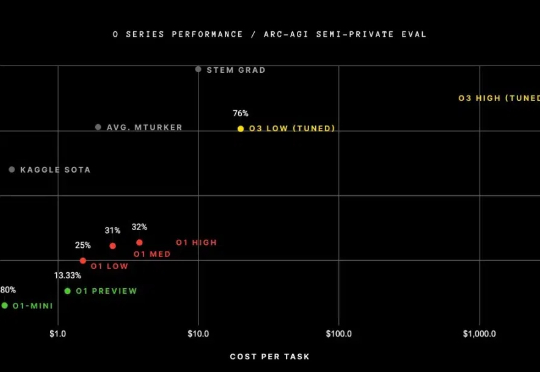
自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。
又是一个文理兼修的优等生,能薅一点是一点。堆了 20 万张 GPU、号称「地表最强」大模型 Grok-3 已经可用啦。「 Grok 3 + Thinking 感觉与 OpenAI 最强商用模型(o1-pro,200 美元/月)的顶尖水平相差无几,
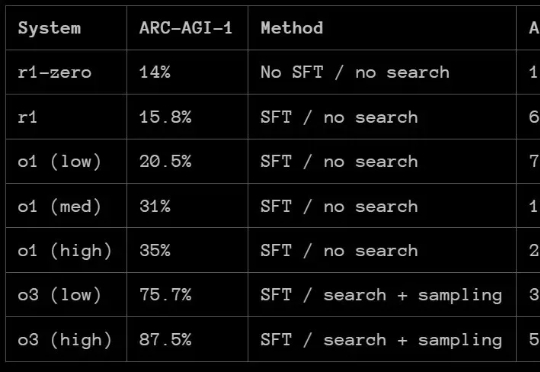
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。

只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
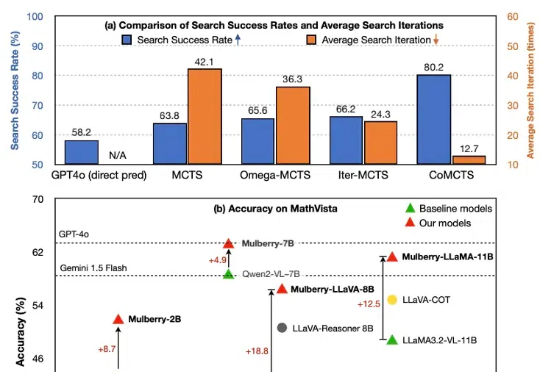
尽管多模态大语言模型(MLLM)在简单任务上最近取得了显著进展,但在复杂推理任务中表现仍然不佳。费曼的格言可能是这种现象的完美隐喻:只有掌握推理过程的每一步,才能真正解决问题。然而,当前的 MLLM 更擅长直接生成简短的最终答案,缺乏中间推理能力。本篇文章旨在开发一种通过学习创造推理过程中每个中间步骤直至最终答案的 MLLM,以实现问题的深入理解与解决。