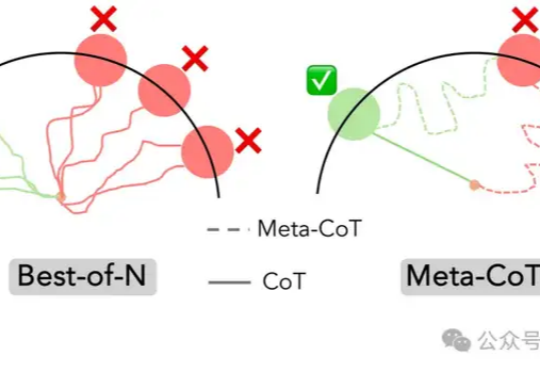
o1推理框架最新成果:斯坦福&伯克利提出元链式思维,升级模型推理能力
o1推理框架最新成果:斯坦福&伯克利提出元链式思维,升级模型推理能力o1背后的推理原理,斯坦福和伯克利帮我们总结好了!
来自主题: AI资讯
8047 点击 2025-01-20 15:18
 搜索
搜索
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!

意图识别及其在智能设计中的应用
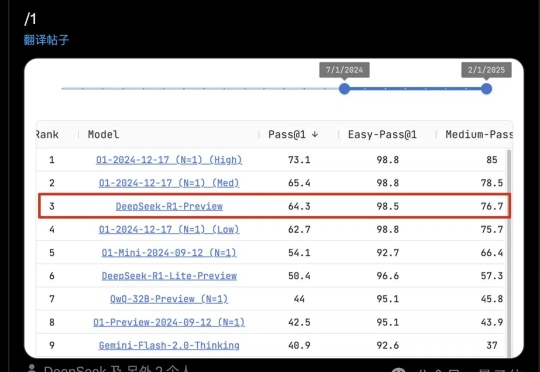
DeepSeek版o1,有消息了。还未正式发布,已在代码基准测试LiveCodeBench霸榜前三,表现与OpenAI o1的中档推理设置相当。注意了,这不是在DeepSeek官方App已经能试玩的DeepSeek-R1-Lite-Preview(轻量预览版)。
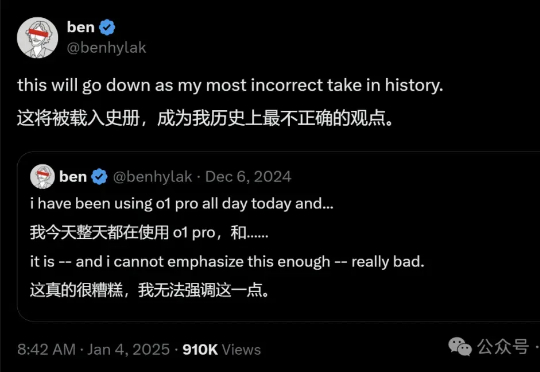
Ben Hylak从最初对o1不满到逐渐掌握使用技巧,成功将其转化为解决重要问题的得力工具。本文探讨了如何正确使用o1,解锁其强大的报告生成和推理分析能力。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。
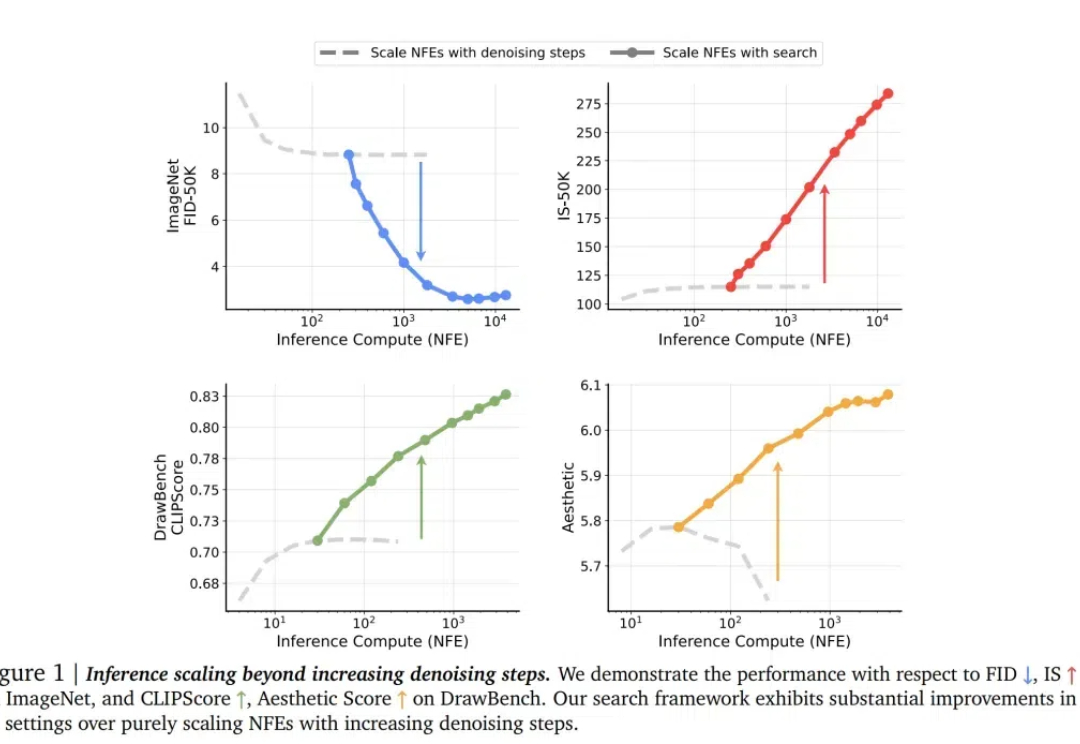
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
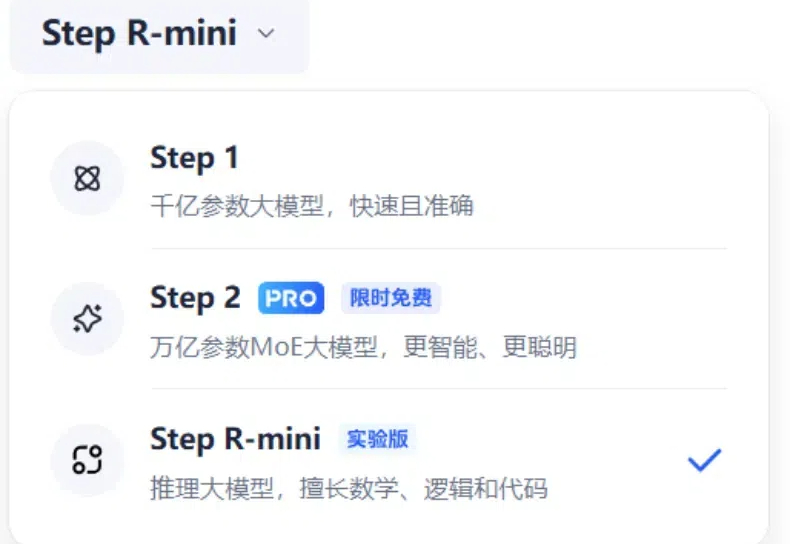
这是阶跃星辰 Step 系列模型家族的首个推理模型。 类似 OpenAI o1 的推理模型在国内终于卷起来了。
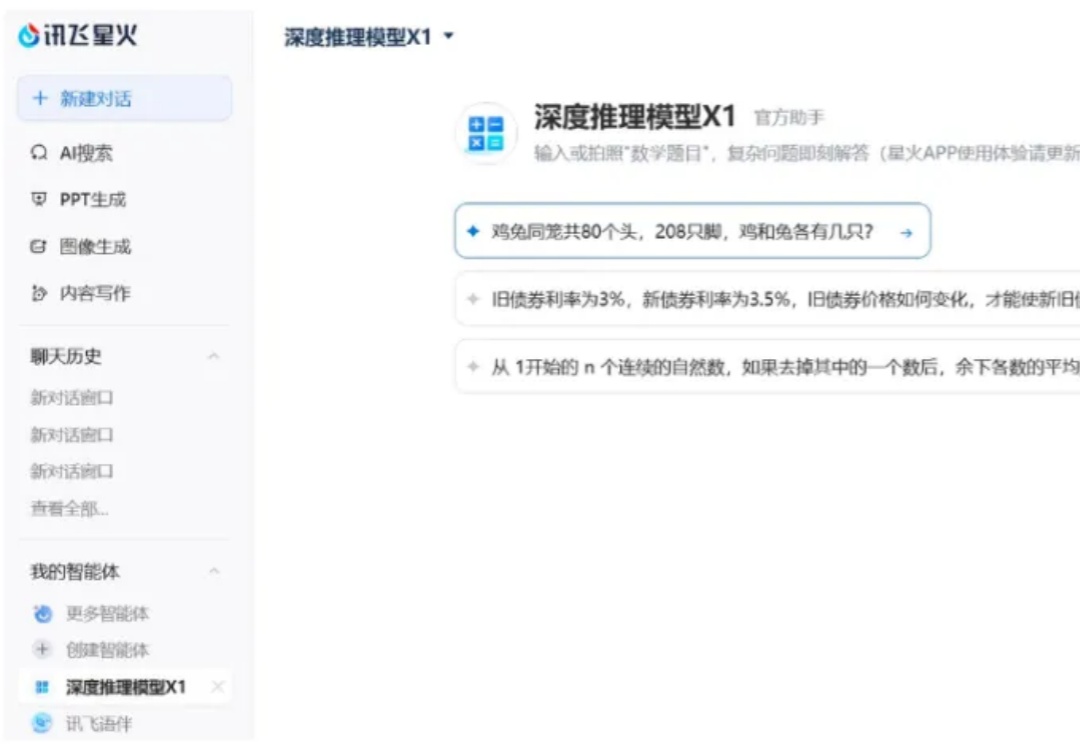
唯一一个在全国产算力上训练的深度推理模型来了!今天,讯飞星火深度推理大模型X1发布,发布会上现场摇数学题开做,答案全部正确。强强pk全国产胜,中文数学能力远超国内外「o1」级推理模型?
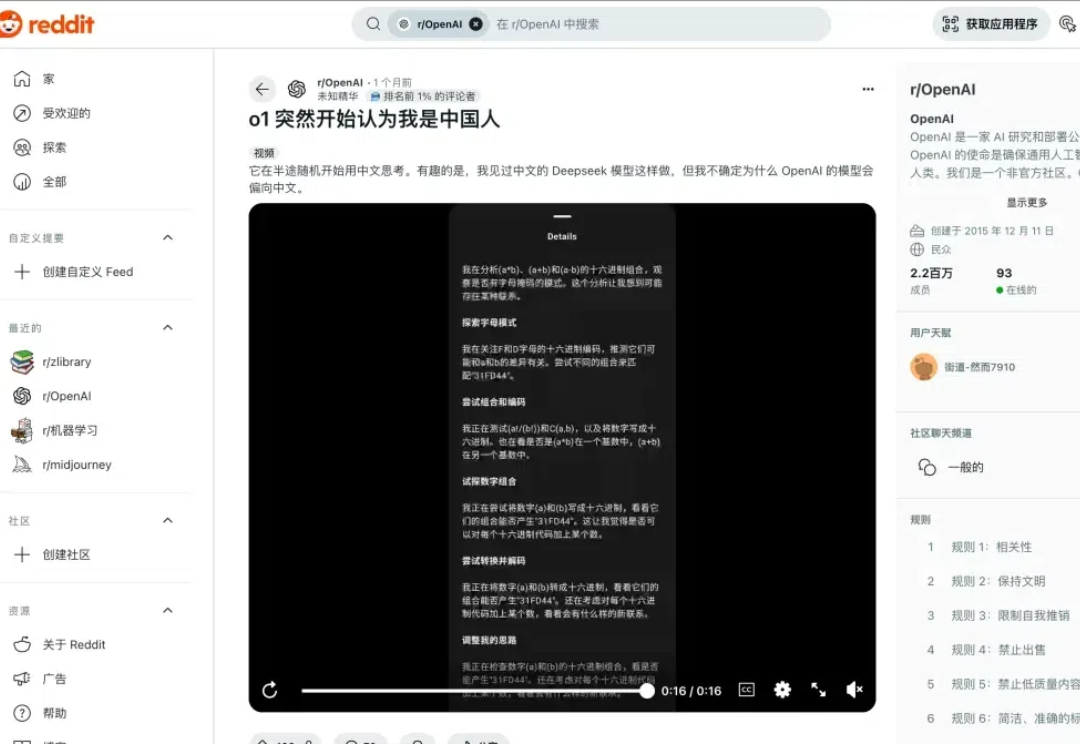
让我们说中文! OpenAI o1 在推理时有个特点,就像有人考试会把关键解题步骤写在演草纸上,它会把推理时的内心 os 分点列出来。 然而,最近 o1 的内心 os 是越来越不对劲了,明明是用英语提问的,但 o1 开始在演草纸上用中文「碎碎念」了。