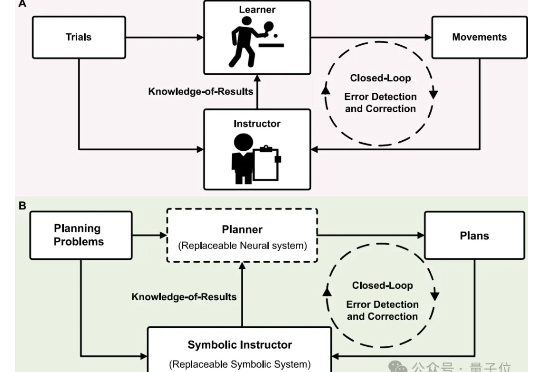
“神经-符号”融合规划器性能显著超越o1:借鉴人类运动学习机制|中国科学院磐石研发团队
“神经-符号”融合规划器性能显著超越o1:借鉴人类运动学习机制|中国科学院磐石研发团队科研er看过来!还在反复尝试材料组合方案,耗时又耗力? 新型“神经-符号”融合规划器直接帮你一键锁定高效又精准的科研智能规划。
来自主题: AI技术研报
9289 点击 2025-08-06 16:01
 搜索
搜索
科研er看过来!还在反复尝试材料组合方案,耗时又耗力? 新型“神经-符号”融合规划器直接帮你一键锁定高效又精准的科研智能规划。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。

小时候完成月考测试后,老师会通过讲解考试卷中吃错题让同学们在未来取得好成绩。

又一位离职OpenAI的核心研究员发声! 刚刚被曝加入Meta的Hyung Won Chung,分享了他对AI未来的深刻思考:人工智能正在成为有史以来最强大的杠杆机制。

这次是真真真挖到OpenAI大动脉了。 Jason Wei,思维链的提出者、o1系列模型的关键人物,被曝也被扎克伯格请走,即将入职Meta。

大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。

从撒谎到勒索,再到暗中自我复制,AI 的「危险进化」已不仅仅是科幻桥段,而是实验室里的可复现现象。
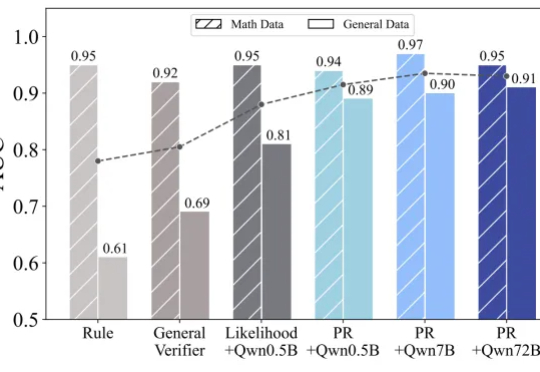
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
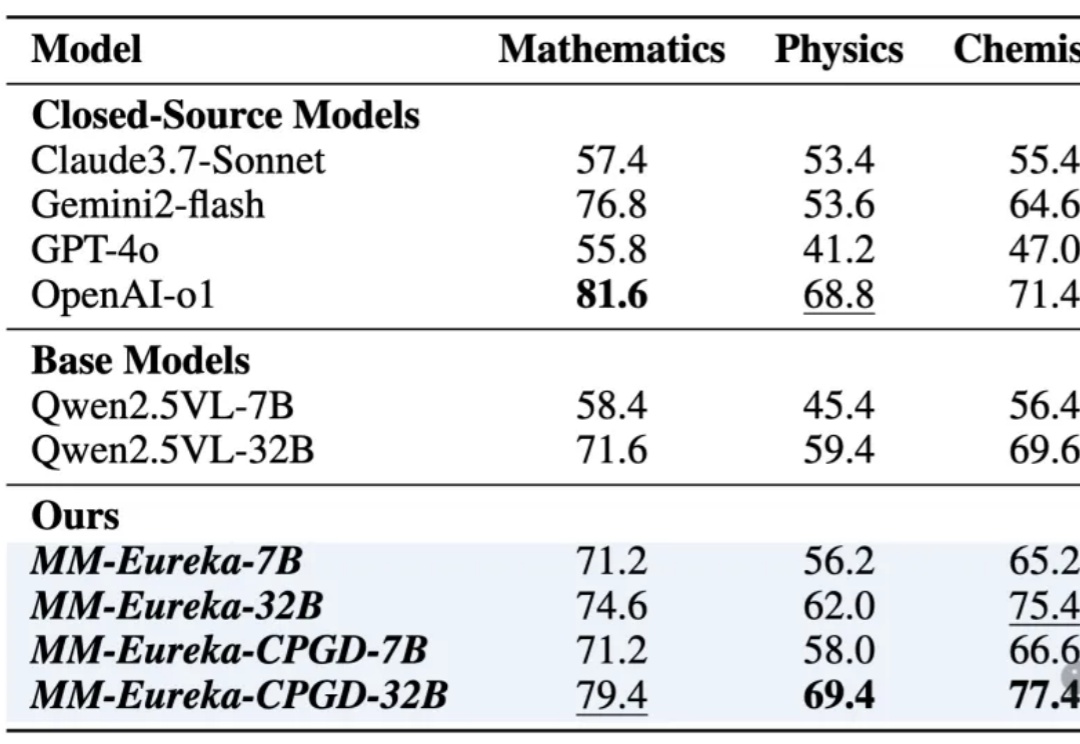
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。