
o3/o4-mini幻觉暴增2-3倍!OpenAI官方承认暂无法解释原因
o3/o4-mini幻觉暴增2-3倍!OpenAI官方承认暂无法解释原因OpenAI新模型发布后,大家体感都幻觉更多了。甚至有人测试后发出预警:使用它辅助编程会很危险。当大家带着疑问仔细阅读System Card,发现OpenAI官方也承认了这个问题,与o1相比o3幻觉率是两倍,o4-mini更是达到3倍。
来自主题: AI资讯
10154 点击 2025-04-21 13:42
 搜索
搜索
OpenAI新模型发布后,大家体感都幻觉更多了。甚至有人测试后发出预警:使用它辅助编程会很危险。当大家带着疑问仔细阅读System Card,发现OpenAI官方也承认了这个问题,与o1相比o3幻觉率是两倍,o4-mini更是达到3倍。
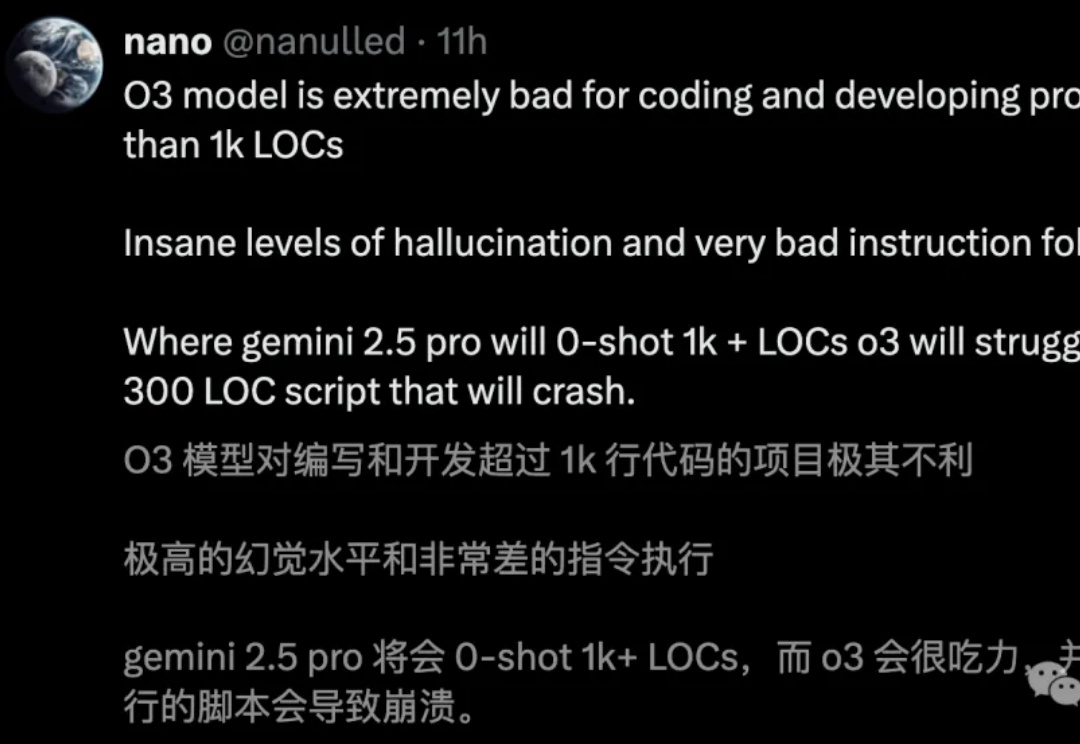
o3编码直逼全球TOP 200人类选手,却存在一个致命问题:幻觉率高达33%,是o1的两倍。Ai2科学家直指,RL过度优化成硬伤。

AI智商再创新高!OpenAI o3以惊人的136分刷新门萨智商测试纪录,超越不久前登顶的Gemini 2.5 Pro。更令人瞩目的是其强大的图像理解能力:仅凭一张无EXIF信息的菜单或风景照,o3就能精准推理并反向定位拍摄地点,引发了用AI玩「照片寻址(GeoGuessr)」的新热潮。
知道大模型接下来要卷视觉推理,但没想到这么卷——数学试卷都快要不够用了。

今天,字节发布了一整套 AI 全家桶,深度思考模型、视觉推理、文生图、AI Agent……几乎涵盖了最近 AI 圈关注度最高的产品。字节发布的产品和亮点有哪些:1. 豆包 1.5 · 深度思考模型,2. 文生图 3.0
OpenAI新模型全网实测惊艳来袭!o3缩放图像被玩疯,o4-mini速解Project Euler,碾压人类。AI初创CEO说,OpenAI凭此一役已经重回榜首,甚至有经济学家直言AGI已经来临!
仅隔一天,OpenAI再次突然放大招: 一口气,o3和o4 mini同步上线。

满血版o3和o4-mini深夜登场,首次将图像推理融入思维链,还会自主调用工具,60秒内破解复杂难题。尤其是,o3以十倍o1算力刷新编程、数学、视觉推理SOTA,接近「天才水平」。此外,OpenAI还开源了编程神器Codex CLI,一夜爆火。

AI辅助人类,完成了首个非平凡研究数学证明,破解了50年未解的数学难题!在南大校友的研究中,这个难题中q=3的情况,由o3-mini-high给出了精确解。

代码截图泄露,满血版o3、o4-mini锁定下周!更劲爆的是,一款据称是OpenAI的神秘模型一夜爆红,每日处理高达260亿token,是Claude用量4倍。奥特曼在TED放话:将推超强开源模型,直面DeepSeek挑战。