
GPT-5七月上线?内部爆料+奥特曼疯狂暗示,自曝前方时刻「令人恐惧」
GPT-5七月上线?内部爆料+奥特曼疯狂暗示,自曝前方时刻「令人恐惧」GPT-5,将于7月发布?刚刚,这个消息已经传疯了!跟奥特曼、OpenAI来往密集的几位人士,已经在留言区纷纷爆料了。而奥特曼本人确认,o3 pro也快来了。
来自主题: AI资讯
8922 点击 2025-06-04 12:07
 搜索
搜索
GPT-5,将于7月发布?刚刚,这个消息已经传疯了!跟奥特曼、OpenAI来往密集的几位人士,已经在留言区纷纷爆料了。而奥特曼本人确认,o3 pro也快来了。
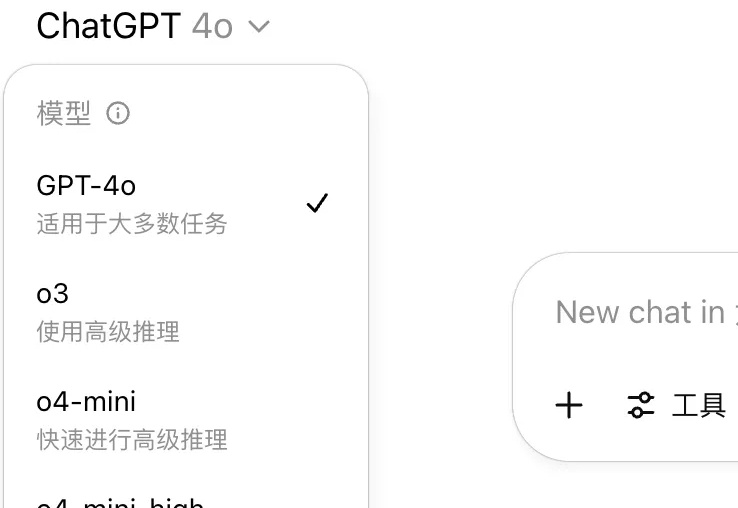
OpenAI模型命名混乱没规律,以至于打开ChatGPT后,好多人都不知道到底该用哪个模型来完成任务。

端午节前OpenAI发布了o3/o4-mini模型的Function Calling指南,这份指南可以说是目前网上最硬核权威的大模型函数调用实战手册,没有之一。

OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?

昨晚,终于等到了DeepSeek-R1-0528官宣。升级后的模型性能直逼o3和Gemini 2.5 Pro。如今,DeepSeek真正坐实了全球开源王者的称号,并成为了第二大AI实验室。
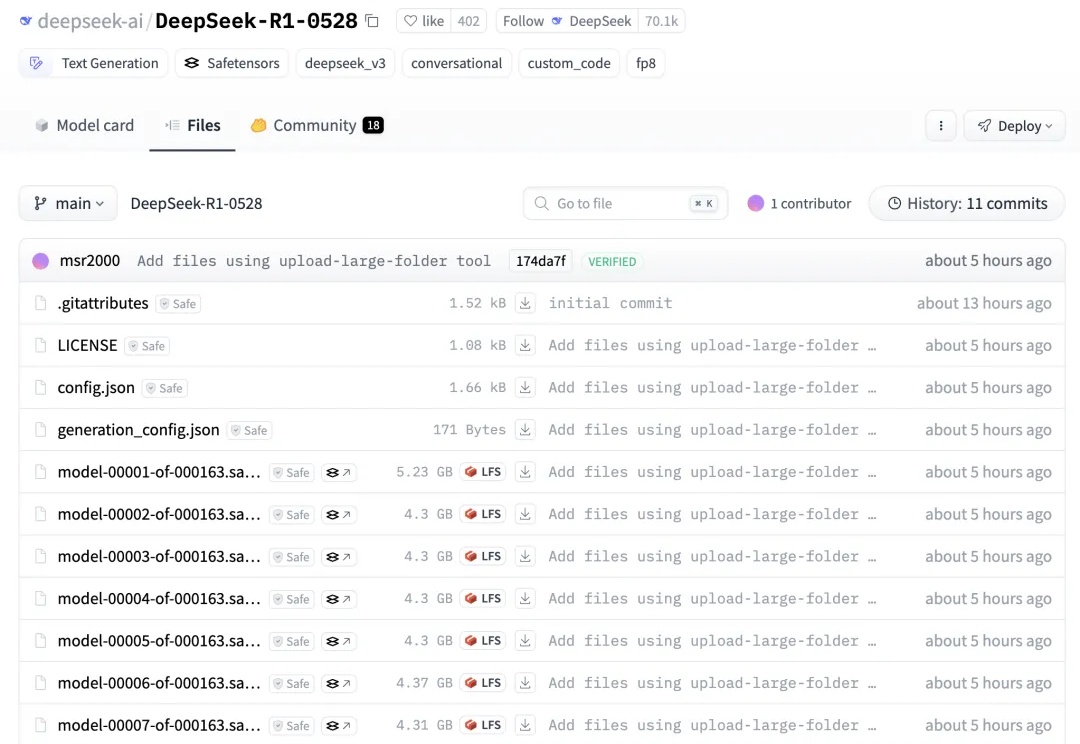
新版DeepSeek-R1重磅开源,凌晨已放出权重!此次模型性能几乎与o4-mini(Medium)相当,编程实测超越Claude 4 Sonnet。网友纷纷惊叹:开源又一次胜利了。

上周的开发者大会,谷歌冷不丁地掏出个 Veo3 就惊艳了全球。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……

Google I/O 2025 结束后,Google CEO Sundar Pichai 接受了《The Verge》主编专访,这也是双方连续第三年于 I/O 后展开对谈,而今年的背景更为特殊:Gemini 模型全面更新、多模态生成工具 Veo3 登场、AI 功能深度融入 Android 与 XR 平台,Google 展现出前所未有的产品化信心。
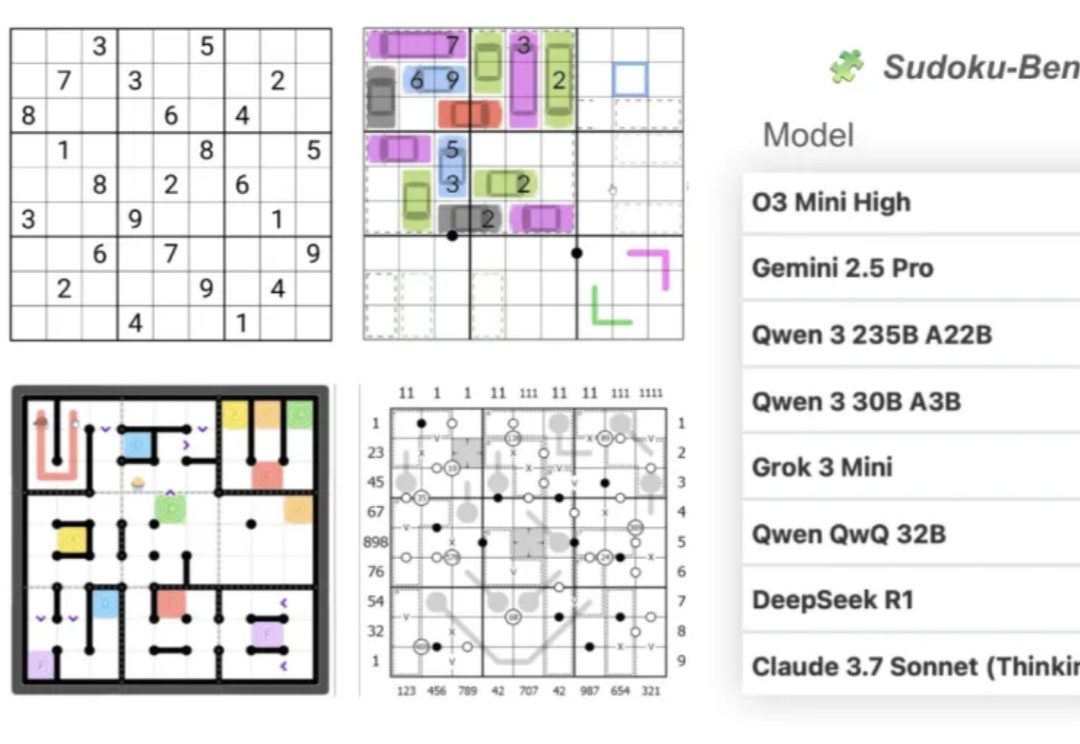
大模型做数独,总体正确率只有15%???