多模态模型已落地多领域,OpenBayes贝式计算获评「大模型最具潜力创业企业 TOP 10」
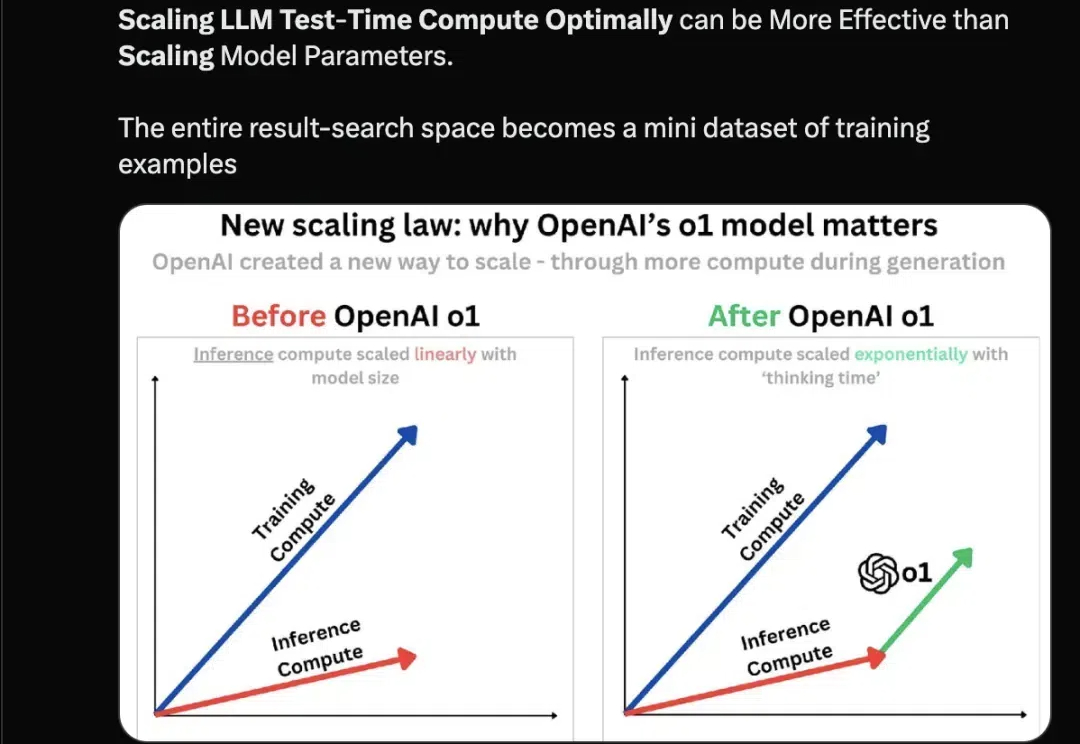
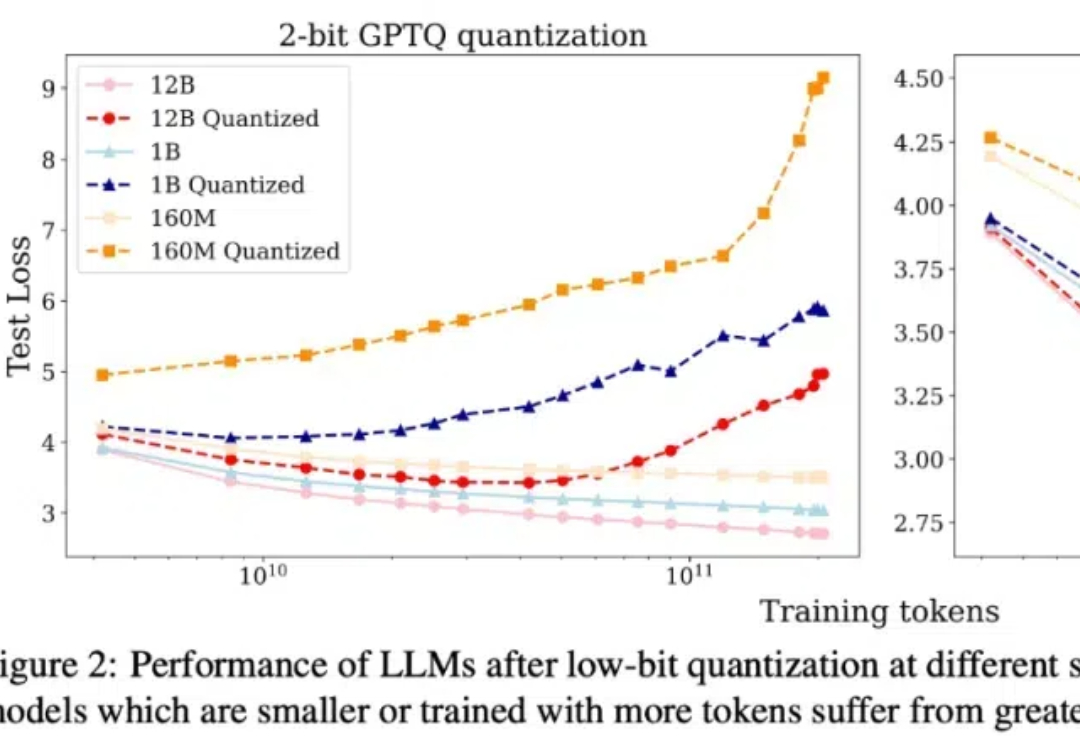
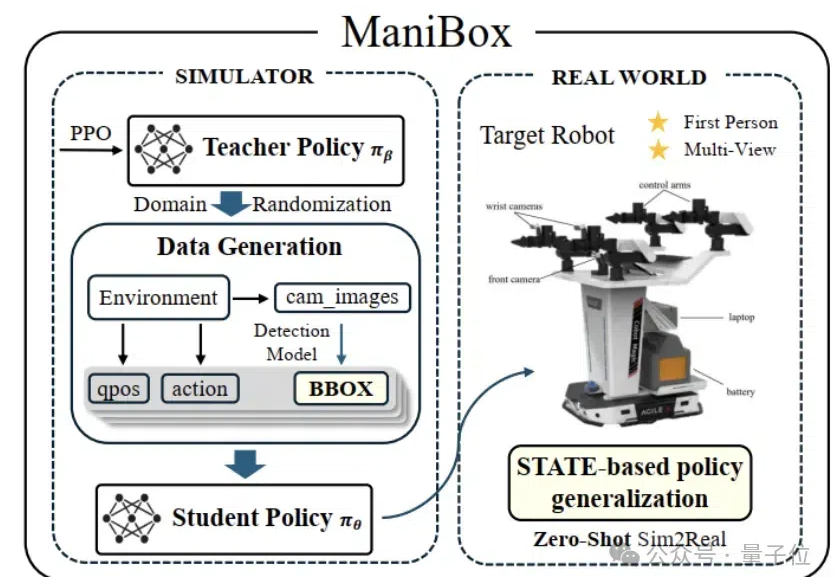
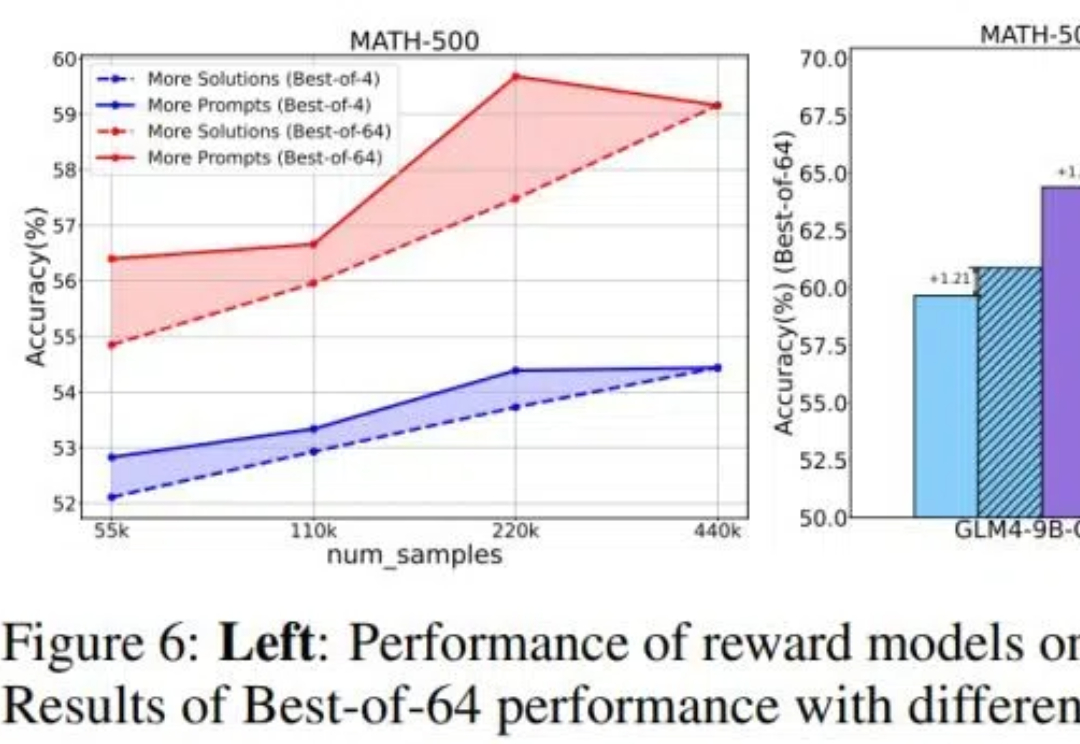
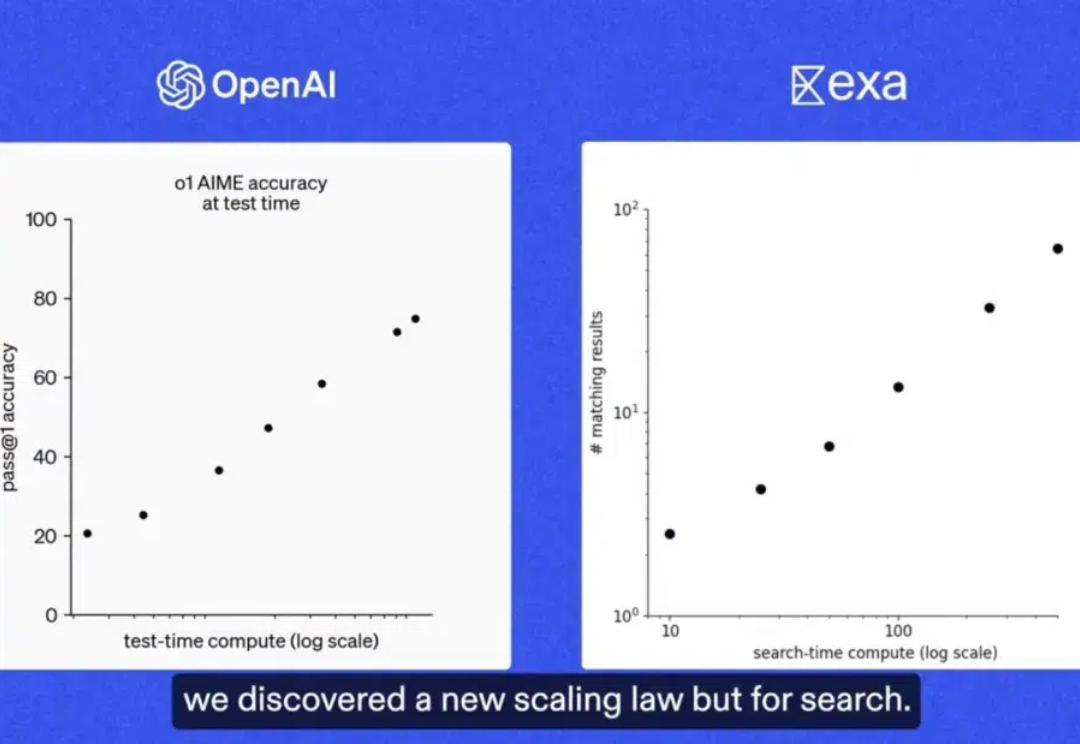
多模态模型已落地多领域,OpenBayes贝式计算获评「大模型最具潜力创业企业 TOP 10」在 2024 年的 NeurIPS 会议上,Ilya Sutskever 提出了一系列关于人工智能发展的挑战性观点,尤其集中于 Scaling Law 的观点:「现有的预训练方法将会结束」,这不仅是一次技术的自然演进,也可能标志着对当前「大力出奇迹」方法的根本性质疑。
来自主题: AI资讯
7848 点击 2025-01-02 16:31