
奥特曼宣判Transformer死刑! AGI两年内降临,下一代架构已在路上
奥特曼宣判Transformer死刑! AGI两年内降临,下一代架构已在路上终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。
来自主题: AI资讯
8345 点击 2026-03-17 14:35
 搜索
搜索
终结Transformer的架构即将诞生!奥特曼最新访谈豪言,下一代AI架构彻底颠覆Transformer,LSTM的命运或将再次上演。
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”
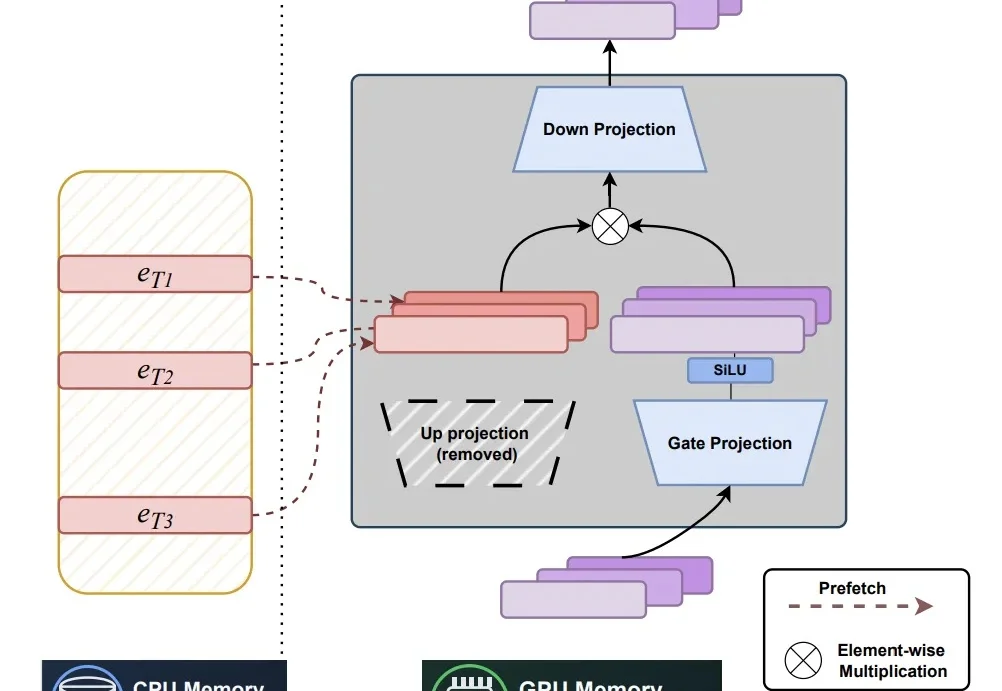
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
面对 OpenClaw(龙虾)可能存在的「恶意利用用户数据和资金」的重大风险,Transformer 八子之一 Illia Polosukhin 出手了。今天,Illia Polosukhin 在 Reddit 上发了一则帖子,深谈了其使用 Rust 来构建安全版 OpenClaw 的心路历程,引起了热议。
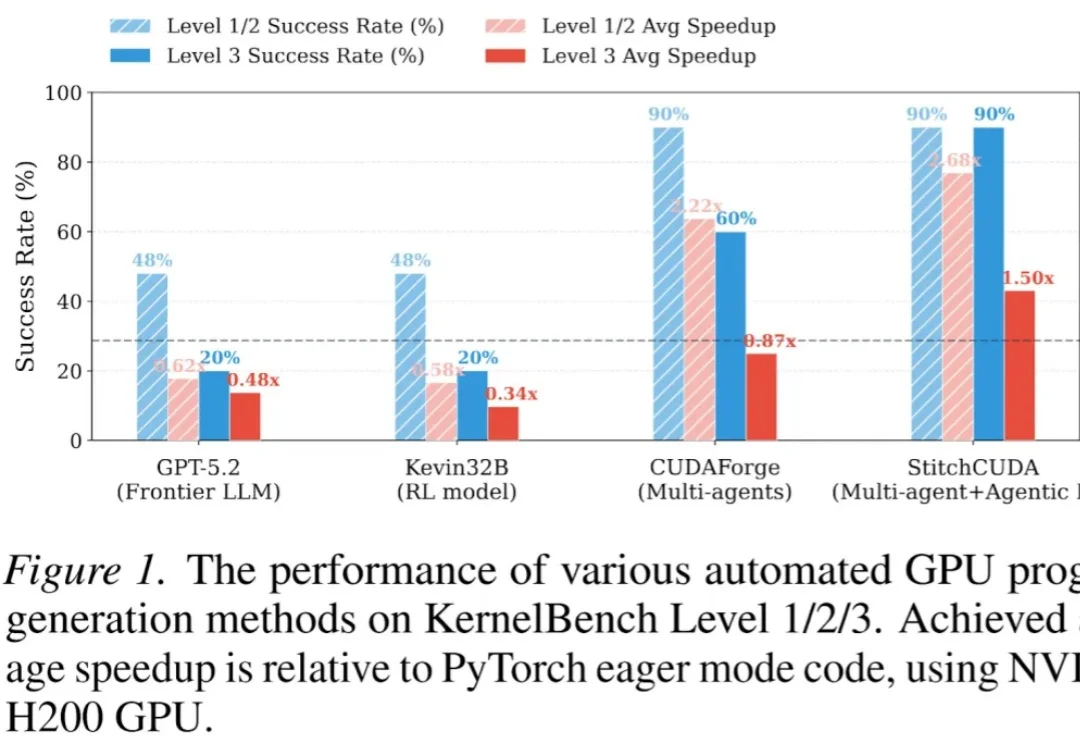
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

作者 | 高允毅 很多人知道,Transformer 是谷歌发明的。但 ChatGPT,却不是谷歌做出来的。这件事,在过去几年,几乎成了硅谷最大的“遗憾注脚”。 但如果真正走进今天的 Google D
在十九世纪的暹罗王国曾诞生过这样一对连体兄弟:他们分别拥有完整的四肢和独立的大脑,但他们六十余年的人生被腰部相连着的一段不到十厘米的组织带永远绑定在了一起。他们的连体曾带来无尽的束缚,直到他们离开暹罗,走上马戏团的舞台。十年间,两兄弟以近乎合二为一的默契巡演欧美,获得巨大成功。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混