
第二代InfLLM开源,同尺寸快三倍!零参数,可训练稀疏注意力
第二代InfLLM开源,同尺寸快三倍!零参数,可训练稀疏注意力InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。
来自主题: AI技术研报
9596 点击 2025-10-13 11:55
 搜索
搜索
InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。
在量子位智库的观察中,AI知识助手remio正在尝试这一方向。remio主打无感和自动化,致力于变成记忆和用户同频的第二大脑。主打能够在用户无感知的情况下,实时、自动化地采集用户所需管理的信息,为用户创造更加轻松顺畅的使用体验。
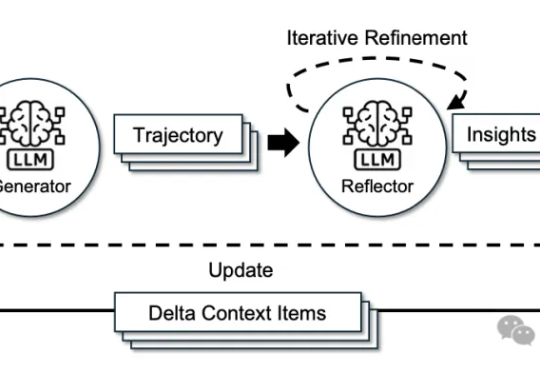
来自斯坦福大学、SambaNova Systems公司和加州大学伯克利分校的研究人员,在新论文中证明:依靠上下文工程,无需调整任何权重,模型也能不断变聪明。他们提出的方法名为智能体上下文工程ACE。
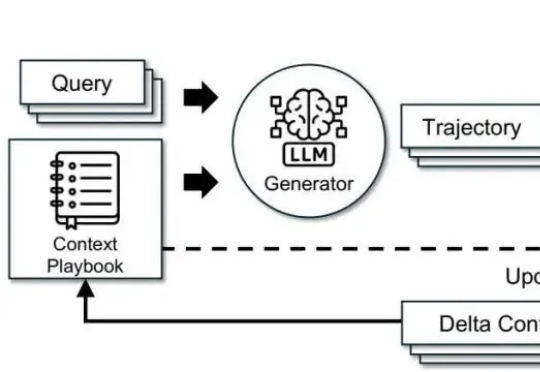
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。

我们正式推出第三代重排器 Jina Reranker v3。它在多项多语言检索基准上刷新了当前最佳表现(SOTA)。这是一款仅有 6 亿参数的多语言重排模型。我们为其设计了名为 “last but not late” (中文我们译作后发先至)的全新交互机制,使其能接受 Listwise 即列式输入,在一个上下文窗口内一次性完成对查询和所有文档的深度交互。
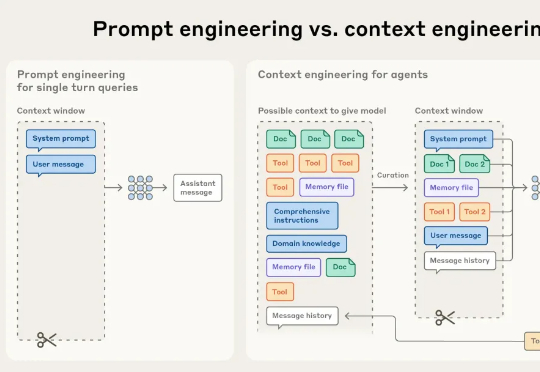
Hi,返工早上好。 我是洛小山,和你聊聊 AI 行业思考。 AI Agent 应用的竞争逻辑,正在发生根本性变化。 当许多团队还在死磕提示词优化(PE 工程)时,一些优秀团队开始重心转向了上下文工程
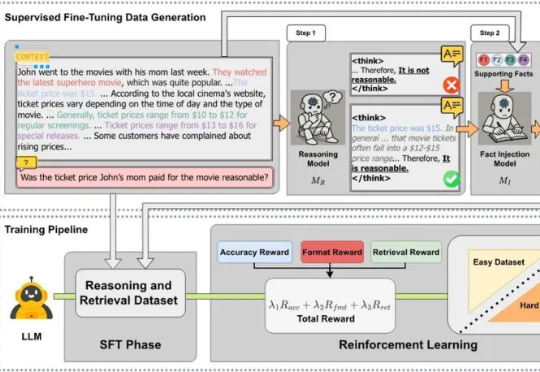
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布

构建有价值的AI Agent需审慎选择场景,避免滥用。应用前需评估任务复杂性、价值是否匹配成本、模型核心能力有无硬伤及出错风险容忍度。开发时坚持极简原则,聚焦环境、工具集、系统提示三大核心要素。优化调试的关键在于理解Agent有限上下文视角,模拟其受限决策状态。
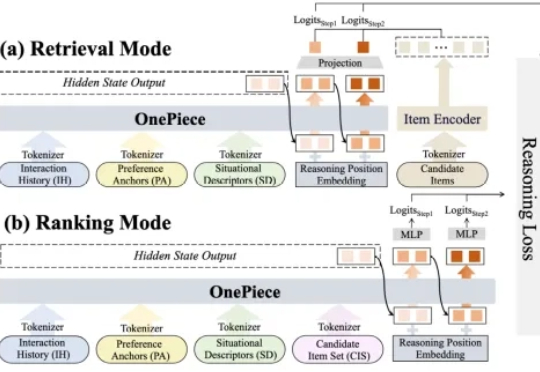
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。