AlphaGo之父找到创造强化学习算法新方法:让AI自己设计
AlphaGo之父找到创造强化学习算法新方法:让AI自己设计强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。
来自主题: AI技术研报
7275 点击 2025-10-29 16:37
 搜索
搜索
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。

Anthropic深夜又放猛招!Claude直接以插件形态接入Excel,不仅能直接操作和读取数据,还能定位单元格内容,并给出修改理由。

刚刚,这样一个消息在 Reddit 上引发热议:硅谷似乎正在从昂贵的闭源模型转向更便宜的开放源替代方案。

对于机器人来说,世界模型真的有必要想象出精确的未来画面吗?在一篇新论文中,来自华盛顿大学、索尼 AI 的研究者提出了这个疑问。

在当前评测生成式模型代码能力的浪潮中,传统依赖人工编写的算法基准测试集,正日益暴露出可扩展性不足与数据污染严重两大瓶颈。

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。

直到我看到 Dedalus Labs 宣布完成 1100 万美元种子轮融资的消息,才意识到有人正在系统性地解决这个问题。这家由 Cathy Di 和 Windsor Nguyen 创立的公司,正在构建一个基础设施层,让开发者能够用 5 行代码就搭建起一个功能完整的 AI agent。这不是夸张的营销话术,而是他们真正在做的事情。
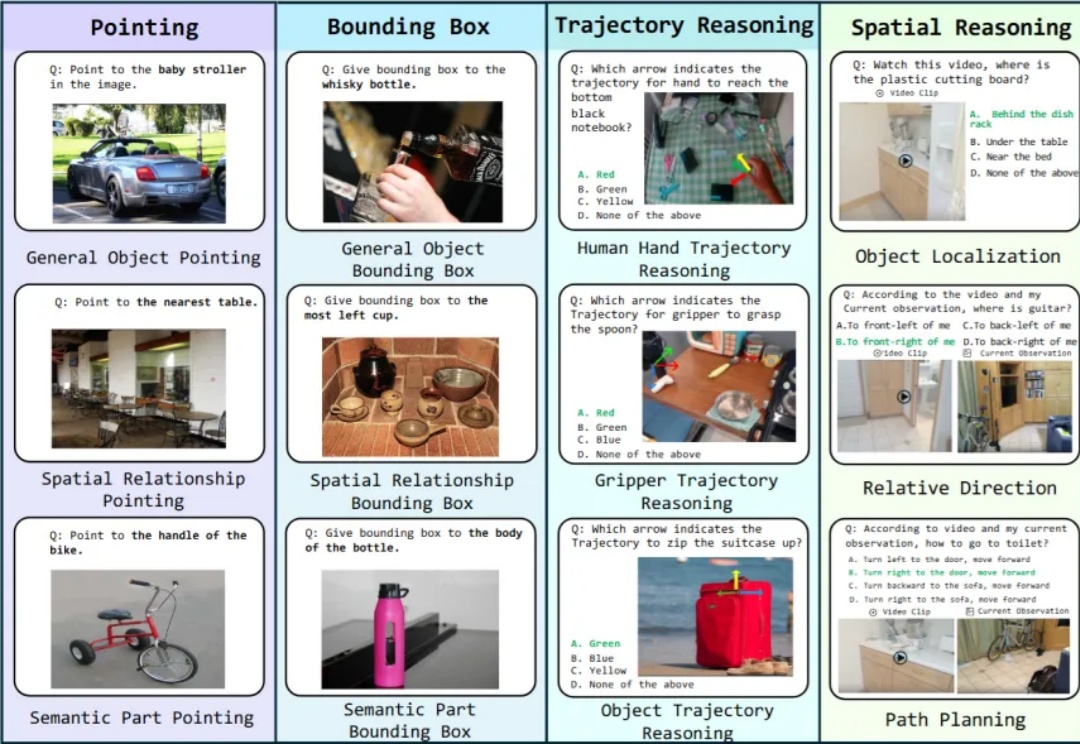
具身智能是近年来非常火概念。一个智能体(比如人)能够在环境中完成感知、理解与决策的闭环,并通过环境反馈不断进入新一轮循环,直至任务完成。这一过程往往依赖多种技能,涵盖了底层视觉对齐,空间感知,到上层决策的不同能力,这些能力便是广义上的具身智能。

近日,在 CNCC2025 大会上,郑波首次公开了淘宝全模态大模型的最新进展,并系统介绍了多模态智能在淘宝 AIGX 技术体系的研究应用。另外,结合 AI 模型技术在淘宝应用中的实践,他认为,「狭义 AGI 很可能在 5-10 年内到来。」
刚刚,不发论文、爱发博客的 Thinking Machines Lab (以下简称 TML)再次更新,发布了一篇题为《在策略蒸馏》的博客。在策略蒸馏(on-policy distillation)是一种将强化学习 (RL) 的纠错相关性与 SFT 的奖励密度相结合的训练方法。在将其用于数学推理和内部聊天助手时,TML 发现在策略蒸馏可以极低的成本超越其他方法。