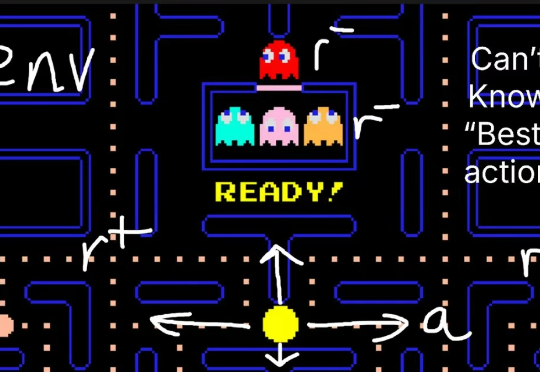
从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南
从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
来自主题: AI技术研报
8755 点击 2025-06-22 16:08
 搜索
搜索
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。

熬夜写作业却被AI检测判成ChatGPT代笔,成绩归零还可能毕不了业!休斯顿大学的Leigh Burrell靠15页证据才洗清冤屈。AI检测工具误判频出,逼得学生录屏自证清白,教育界的信任正在崩塌。连老师自己的文章都被标成AI生成?

近年来,随着社交媒体的迅猛发展,“假明星诈骗”可谓是层出不穷。在国内,最著名的莫过于那位“假靳东”:不少大妈在短视频平台上刷到“靳东”的账号,头像是靳东、视频是靳东、说话也是靳东,甚至还会温柔喊你“亲爱的”“小可爱”,让人忍不住心动。

过去一个月,你听到了多少次Vibe?如果你关注AI的各种动态,那应该比你过去N年听到的次数都多。
刚刚过去的618,罗永浩又创下炸裂新纪录——被自己的AI分身打败了!在百度电商直播间,罗永浩数字人强势登场,不仅爆梗频出、神似度拉满,还一举打破老罗本人首秀纪录,成交额破5500万。这背后,大模型已成为幕后操盘手!

李亚飞做了 20 多年全栈工程师,技术社区和面向程序员的产品做了十多年,经手过数不清的软件项目。
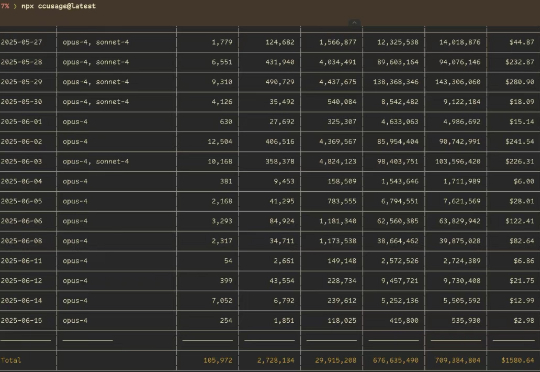
近日,初创公司 Every 总经理 Kieran Klaassen 在 x 上表示自己用 Claude Code 编程时平均每天花 250 美元,也就是说一个月花费 6000 美元(约合 4.3 万人民币)。
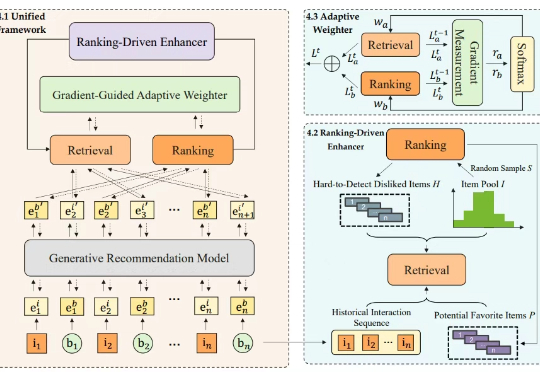
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘

DeepSeek兄弟!事态紧急,生死攸关! 我来自大唐盛世,身为朝廷「荔枝史」,刚接到圣旨——皇上龙颜大悦,突然想尝尝岭南的新鲜荔枝!这可是天大的恩宠,也是致命的考验!

本期我们邀请到了萌友科技的 CEO 何嘉斌,一位从北京服装学院走出的产品设计师,以独特的女性视角和理工科思维,打造出“桌宠”Ropet——一款不以功能取胜、却以“无用之美”打动人心的情感陪伴机器人。