长文本向量模型在4K Tokens 之外形同盲区?
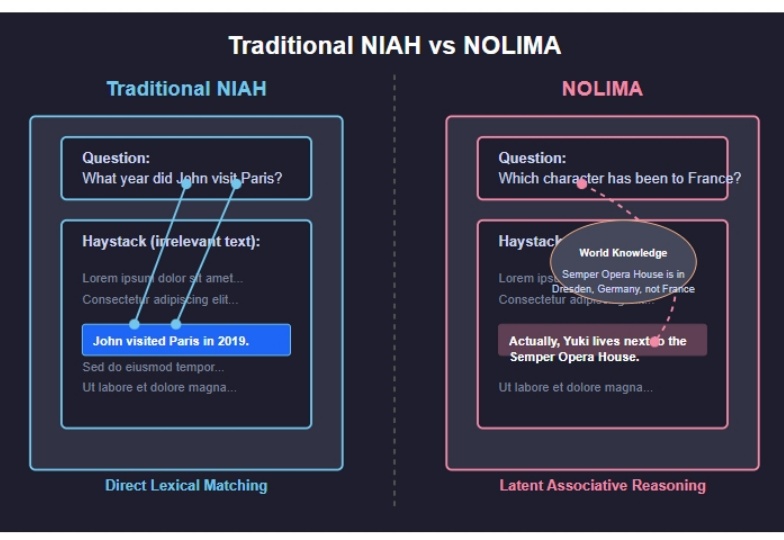
长文本向量模型在4K Tokens 之外形同盲区?2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
来自主题: AI技术研报
6271 点击 2025-03-12 15:08
 搜索
搜索
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。

3月6日上午,宁波市妇女儿童医学中心的产房中,小名思思的孩子呱呱坠地,医护人员为她进行了血氧饱和度测试以及心脏听诊,数据同步至“CHANGE大模型”(中文名启元大模型),几十秒钟后,大模型给出了“阳性”的红字提示,“是先天性心脏病,但是情况不严重,做好随访,3岁之前做一个微创手术就能根治。”医生安慰着思思的父母。
前几天,看到好基友歸藏在X上发了一个帖子:
几年前,由于元宇宙的热潮,几家专注于数字虚拟人的初创公司应运而生。虽然这股热潮已经消退,但生成式人工智能为虚拟人注入了新的活力,因为创建不同的虚拟身份变得更加容易。

在信息爆炸的时代,每个普通人都有机会成为优质内容创作者。关键不在于你的专业背景,而在于你如何把握时机、理解需求、传递价值。

我总是对工具保持警惕。真正有价值的工具应该像好的助手一样,它们存在于背景中,却能显著提升你的能力。对我来说,Obsidian和Claude就是这样的存在——重剑无锋,大巧不工。

如今的前沿推理模型,学会出来的作弊手段可谓五花八门,比如放弃认真写代码,开始费劲心思钻系统漏洞!为此,OpenAI研究者开启了「CoT监控」大法,让它的小伎俩被其他模型戳穿。然而可怕的是,这个方法虽好,却让模型变得更狡猾了……
下面这个,不是 Manus,是 OpenAI 新货:凌晨 1 点的时候,OpenAI 发布了全套 Agent 开发套件,让手搓 Manus 触手可及。套件包含 4 个主要内容Responses API:本次发布会的核心,可视作 Chat API 的上位升级

乙巳新春,中国的推理大模型DeepSeek R1火爆全球。作为一款在推理能力上媲美OpenAI的o1且收费标准远低于o1的国产大模型,DeepSeek一时间在国内刮起一股扑面而来的全民AI风潮,并不令人意外,但这款来自大厂体系外创业团队的开源大模型,经由数位外国商界领袖与技术大佬口碑相传并最终形成在外国新闻媒体上“刷屏”的效果,则是非常耐人寻味了。

为什么必须像评估劳动力一样评估LLM代理,而不仅仅是评估软件。