
AI 社交增长范式重构:“价值重估”与市场分化
AI 社交增长范式重构:“价值重估”与市场分化上周,X博士发布了《中国In-App AI生态演进》报告,揭示了国内移动互联网下半场关于“意图主权”的隐秘争夺。 今天,X博士将目光投向更广阔的全球赛道——《ChatGPT“嵌入”社交链:AI社交从“
来自主题: AI技术研报
9168 点击 2025-12-03 10:15
 搜索
搜索
上周,X博士发布了《中国In-App AI生态演进》报告,揭示了国内移动互联网下半场关于“意图主权”的隐秘争夺。 今天,X博士将目光投向更广阔的全球赛道——《ChatGPT“嵌入”社交链:AI社交从“

“既然我可以直接使用 PyTorch,为什么还要费心使用 CUDA 呢?”

不用“噫吁嚱”——前端没被AI杀死,终端且得狂飙。

太离谱了!你以为自己在和最先进的 AI 交互,屏幕对面坐着的却可能是两个满头大汗的人类。

2026 年的 AI 领域,会发生哪些变化?哪些技术会成为行业争夺的焦点?在应用层面,又有哪些变量可能彻底重塑市场格局?

当硅谷还在争论AI何时超越人类时,一群「末日信徒」已经把目光投向了世界上最古老的权力中心——梵蒂冈。前谷歌研究员莱文试图抢在科技巨头「安抚」教会之前,给教皇利奥十四世喂下一颗「红药丸」:真正的审判日可能不是神罚,而是失控的代码。这是一场发生在信仰与算法之间的博弈,赌注则是人类在AGI时代的命运。
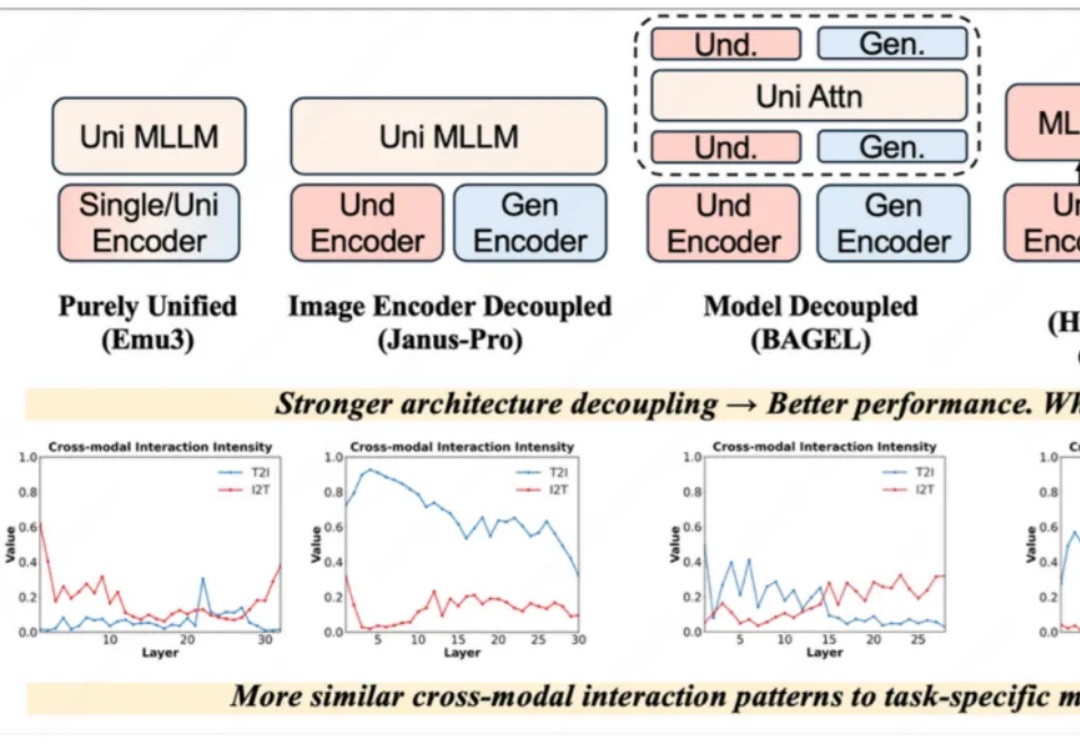
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。

在美国也出现了一种“开源重新兴起”的现象,某种意义上是对中国发展的反应。所以美国开始重新推动大量开源。
让兵马俑跳 K-Pop 是什么体验?

5000亿美元,是NASA预估能让人类完成火星登陆的预算、能买下1.36个阿里(3670亿美元)、3.5个NBA联盟(1400亿美元)、建设100座Apple Park(50亿美元)、买1400亿杯咖啡(3.5美元),却只够OpenAI建一座Stargate数据中心。