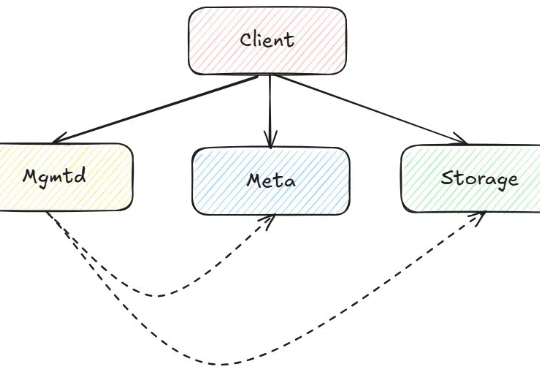
DeepSeek开源的文件系统,是如何提升大模型效率的?
DeepSeek开源的文件系统,是如何提升大模型效率的?在 AI 领域里,大模型通常具有百亿甚至数千亿参数,训练和推理过程对计算资源、存储系统和数据访问效率提出了极高要求。
来自主题: AI技术研报
8195 点击 2025-05-04 17:35
 搜索
搜索
在 AI 领域里,大模型通常具有百亿甚至数千亿参数,训练和推理过程对计算资源、存储系统和数据访问效率提出了极高要求。

从单张低分辨率(LR)图像恢复出高分辨率(HR)图像 —— 即 “超分辨率”(SR)—— 已成为计算机视觉领域的重要挑战。
近年来,「思维链(Chain of Thought,CoT)」成为大模型推理的显学,但要让小模型也拥有长链推理能力却非易事。

据新言科技报道,快手上线「喵记多」App,试水 AI 笔记赛道。该应用由快手旗下轻雀科技团队开发,更准确来说,来自协同办公产品「妙记多」团队。我们在「喵记多」上看到了 flomo、AI 宠物陪伴、Dola Agent 日程管理等产品的影子。

知名 Go 大佬 Thorsten Ball 最近用 315 行代码构建了一个编程智能体,并表示「它运行得非常好」且「没有护城河」(指它并非难以复制)。
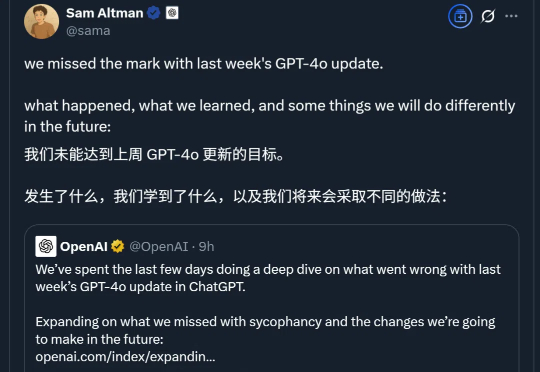
GPT-4o更新后“变谄媚”?后续技术报告来了。

现在如果我想听音乐,我第一反应是:“我要用哪个服务?Spotify还是Tidal?”但这其实不是我真正的需求。我的真实意图是:“我想听这首歌。”我希望只要说出来,AI就能帮我搞定。

AI也会偷偷努力了?Letta和UC伯克利的研究者提出「睡眠时计算」技术,能让LLM在空闲时间提前思考,大幅提升推理效率。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。

超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!