
人在北京,用上豆包打车了!
人在北京,用上豆包打车了!刚刚,豆包悄然上线打车服务。智东西发现,获得灰测资格的用户已经可以直接在豆包App内使用打车功能,底层运力由曹操出行提供。从体验来看,整个流程与传统打车软件相比进一步简化。
来自主题: AI资讯
8496 点击 2026-06-22 20:02
 搜索
搜索
刚刚,豆包悄然上线打车服务。智东西发现,获得灰测资格的用户已经可以直接在豆包App内使用打车功能,底层运力由曹操出行提供。从体验来看,整个流程与传统打车软件相比进一步简化。

家人们,硅谷这次真的把抽象玩明白了。

今年的VivaTech大会上,阿里巴巴董事长蔡崇信在一次“炉边对话”中,系统性地阐述了阿里的长期AI远景,这是继5月末耶鲁大学峰会之后,蔡崇信再度公开复盘阿里。
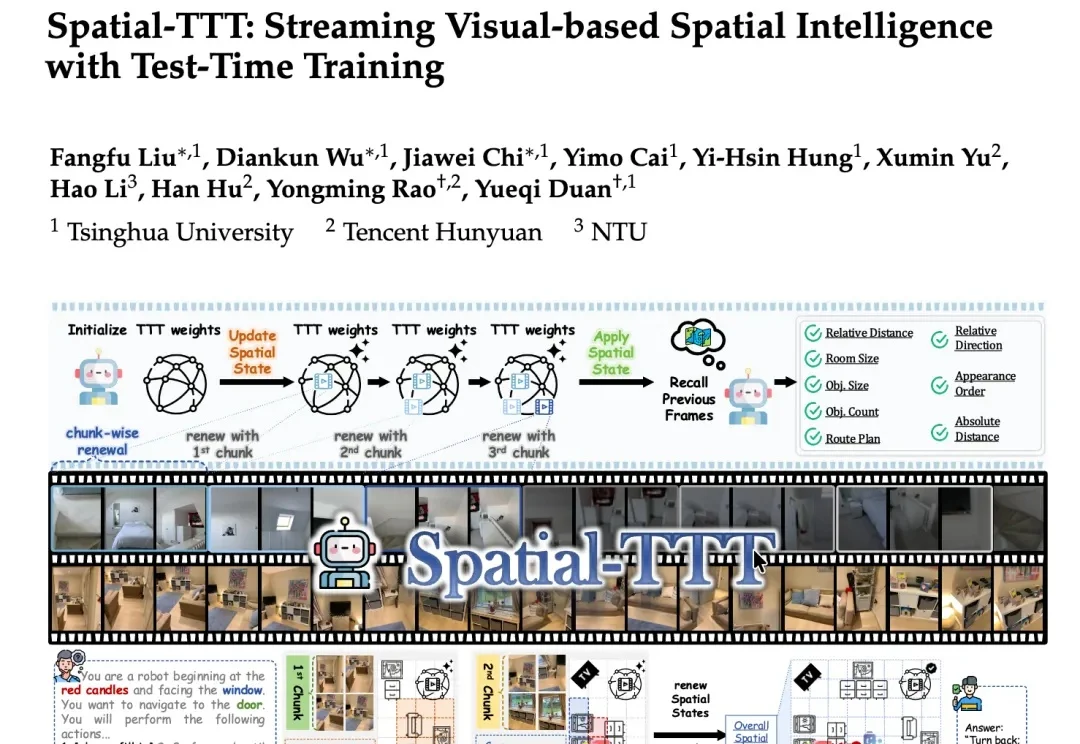
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
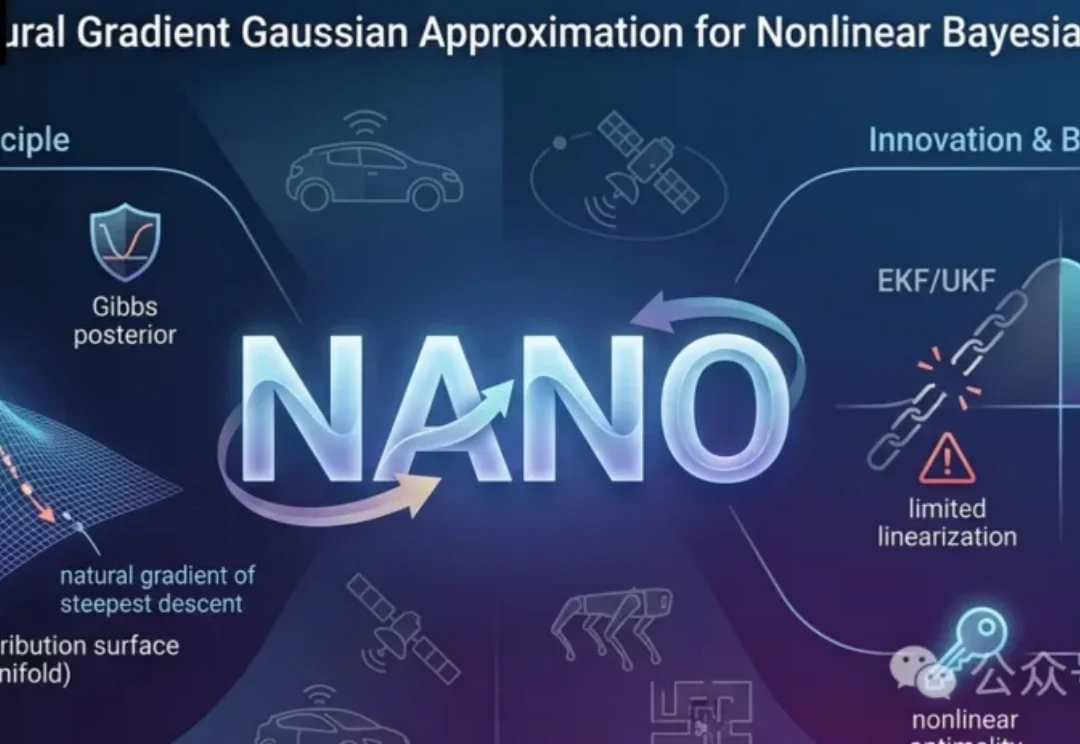
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。
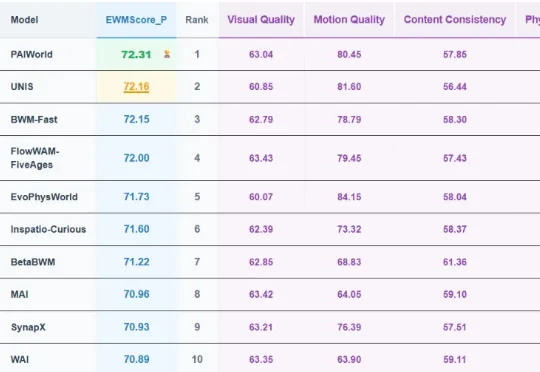
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度

我们最近在重新思考一件事:到底什么样的 Benchmark,才值得今天继续做?

当AI神话被账本照亮,最刺眼的真相终于浮出水面。退潮时刻,狂欢结束。探照灯打过来,谁在裸泳,一目了然。

自从AI爆发以来,所有人都在追问同一个问题:AI时代的护城河到底是什么?

每月一两千,把数字员工用到起飞。