用LaTRO框架,通过自我奖励机制来激发LLM潜在推理能力,基准上提升12.5% |Salesforce重磅
用LaTRO框架,通过自我奖励机制来激发LLM潜在推理能力,基准上提升12.5% |Salesforce重磅大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。
来自主题: AI资讯
8706 点击 2024-11-15 10:34
 搜索
搜索
大规模语言模型(LLMs)已经在自然语言处理任务中展现了卓越的能力,但它们在复杂推理任务上依旧面临挑战。推理任务通常需要模型具有跨越多个步骤的推理能力,这超出了LLMs在传统训练阶段的表现。

文本到图像的生成模型让创作更加灵活,用户可以用自然语言引导生成图像。

智东西11月14日消息,据外媒The Information报道,一位参与工作的内部人士称,谷歌最近一直在为提升其聊天机器人产品Gemini的性能而努力,该公司希望模型性能提升的速度可以与去年相当,这促使研究人员专注于其他方法来勉强取得效果。

成立3年多来,天鹜科技已成功交付30余款蛋白质设计项目。
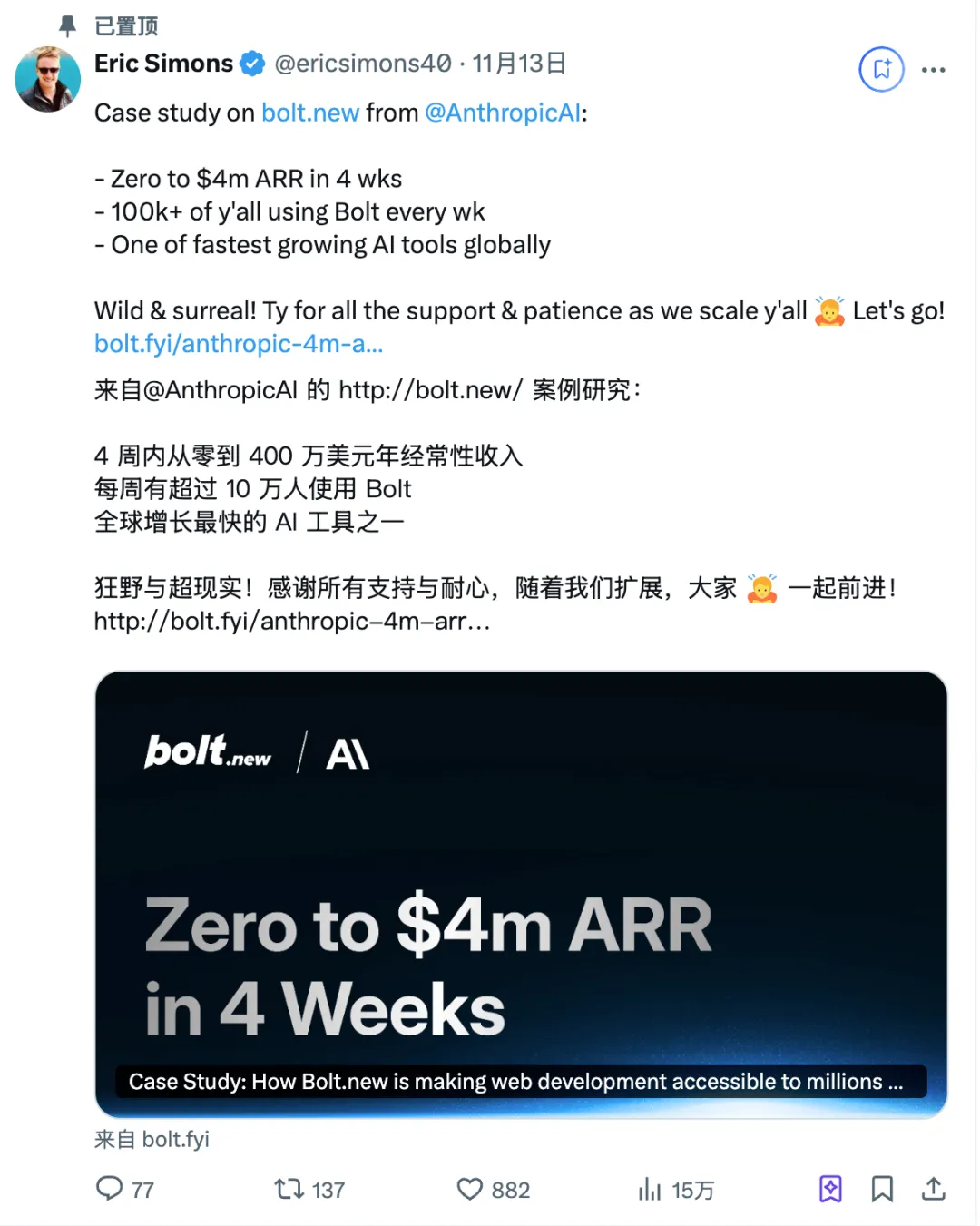
产品上线四周,ARR 收入从零到 400 万美元;

雷军钦点的小米技术大神,回来了。
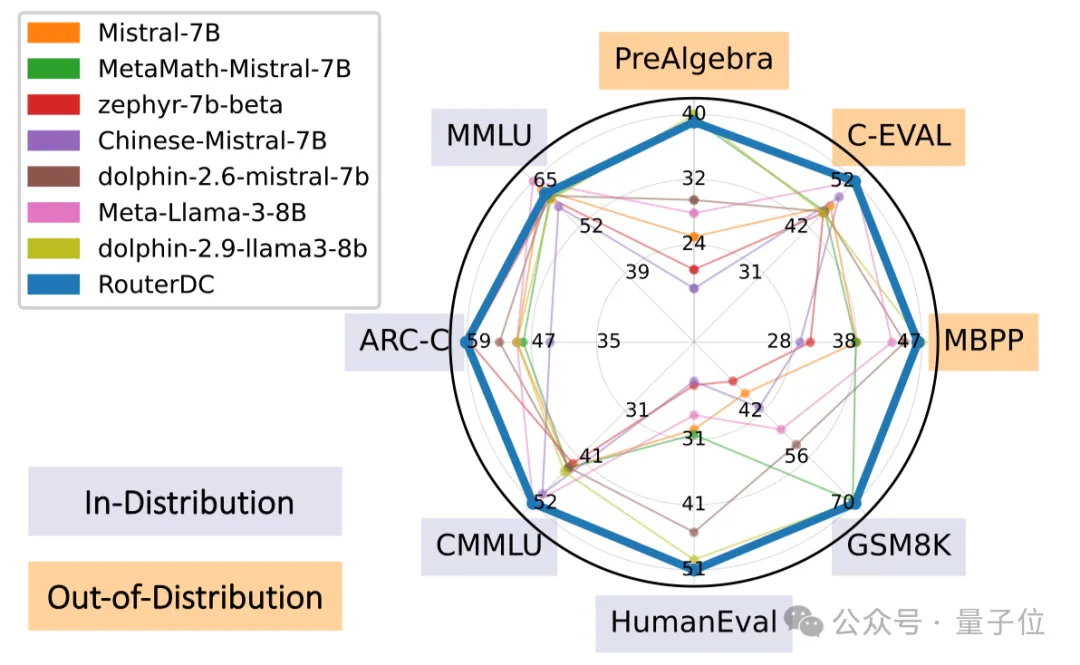
高效组合多个大模型“取长补短”新思路,被顶会NeurIPS 2024接收。
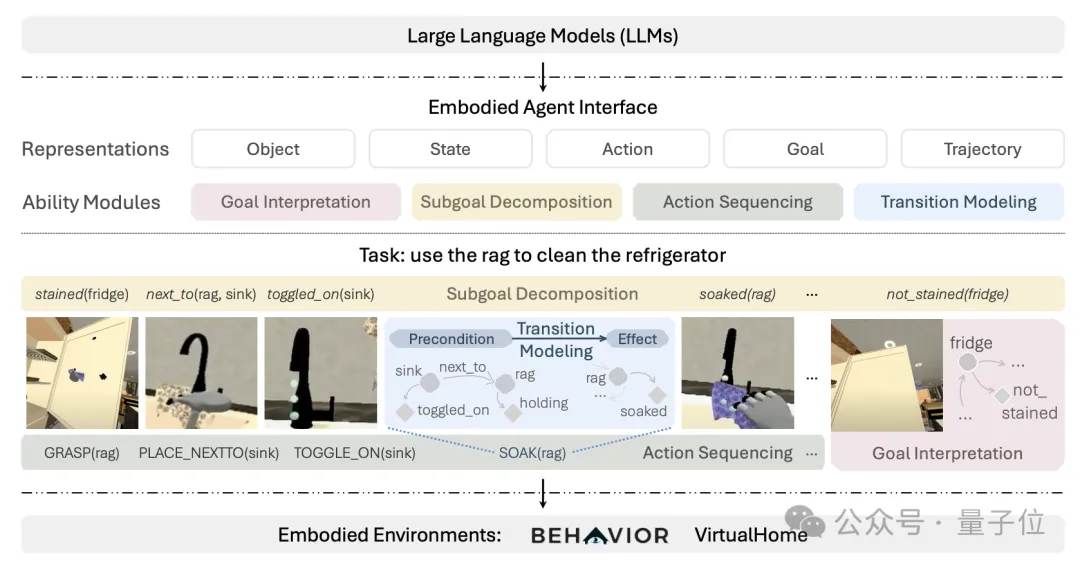
大模型的具身智能决策能力,终于有系统的通用评估基准了。

大模型的发展呈现出追风逐日般的速度,但与之相伴的安全问题,也是频频被曝光。

继 OpenAI o1 成为首个达到 Kaggle 特级大师的人工智能(AI)模型后,另一个 Kaggle 大师级 AI 也诞生了。