
Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强
Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度
来自主题: AI产品测评
10243 点击 2025-04-20 20:47
 搜索
搜索
Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度
从人们被大模型“震撼”完开始思考如何把这项技术用起来的第一天,教育就是被很多人天然想到的场景。一个能压缩全世界知识的AI,天然就是一个人类想象里“老师”的样子。

诺奖得主Demis Hassabis表示,通过AI,DeepMind团队在一年里,完成了10亿年的博士研究时间!10亿年的科学探索被压缩到了一年之内,或许这才代表了AI技术的最高使命。
欧洲初创公司 Pruna AI 一直在研究 AI 模型的压缩算法,该公司的优化框架将于周四开源。Pruna AI 在几个月前完成了 650 万美元的种子轮融资。参与此次初创公司投资的包括 EQT Ventures、Daphni、Motier Ventures 以及 Kima Ventures。

国内首款全流程 AI 互动小说创作工具「谜境 Agent」于近日上线,该工具通过整合剧本生成、美术绘制、交互设计等模块,将传统需要 4-6 个月的开发周期压缩至 10 分钟内完成。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
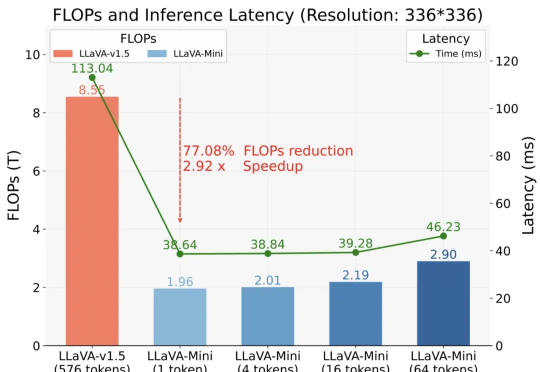
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。

港科大团队重磅开源 VideoVAE+,提出了一种强大的跨模态的视频变分自编码器(Video VAE),通过提出新的时空分离的压缩机制和创新性引入文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持很好的时间一致性和运动恢复。