
DanceGRPO:首个统一视觉生成的强化学习框架
DanceGRPO:首个统一视觉生成的强化学习框架R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。
来自主题: AI技术研报
9403 点击 2025-05-15 10:47
 搜索
搜索
R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。
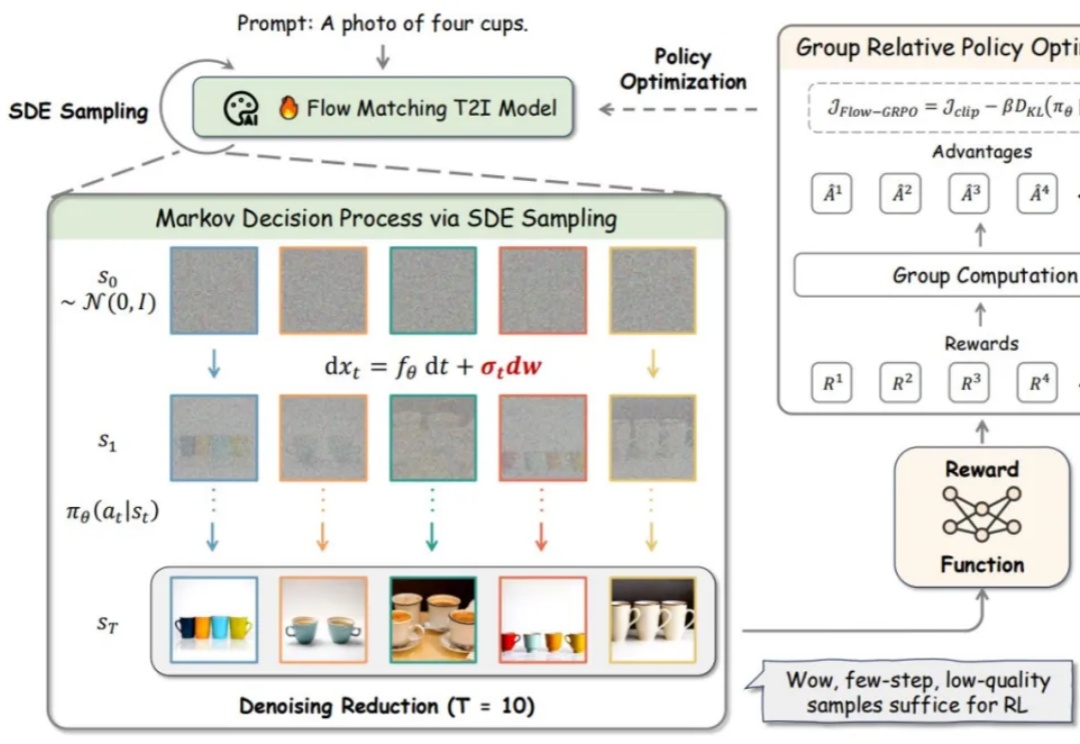
流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(Stable Diffusion, Flux)和视频生成(可灵,WanX,Hunyuan)领域最先进模型的训练方法。然而,这些最先进的模型在处理包含多个物体、属性与关系的复杂场景,以及文本渲染任务时仍存在较大困难。

谷歌Gemini原生图像生成功能又双叒升级了!

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。

扩散模型(Diffusion Models, DMs)如今已成为文本生成图像的核心引擎。凭借惊艳的图像生成能力,它们正悄然改变着艺术创作、广告设计、乃至社交媒体内容的生产方式。

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

OpenAI推出图像生成API,低至0.02美元/张,支持多模态定制。
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。

GPT-4o带火的漫画风角色生成,现在有了开源版啦!