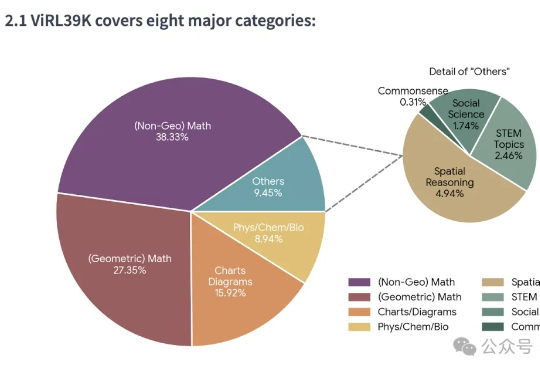
首个多模态专用慢思考框架!超GPT-o1近7个百分点,强化学习教会VLM「三思而后行」
首个多模态专用慢思考框架!超GPT-o1近7个百分点,强化学习教会VLM「三思而后行」在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
来自主题: AI技术研报
9215 点击 2025-06-07 11:00
 搜索
搜索
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
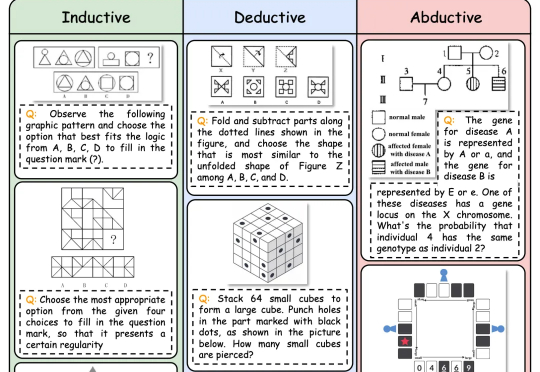
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
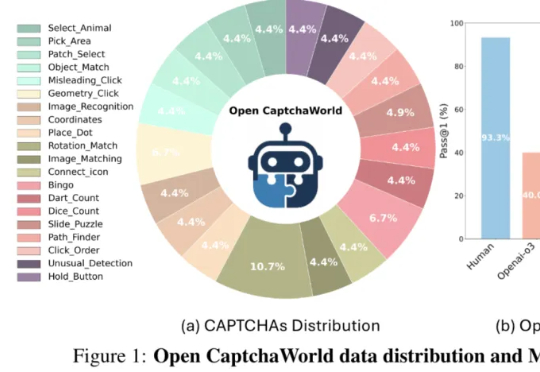
当前最强多模态Agent连验证码都解不了?
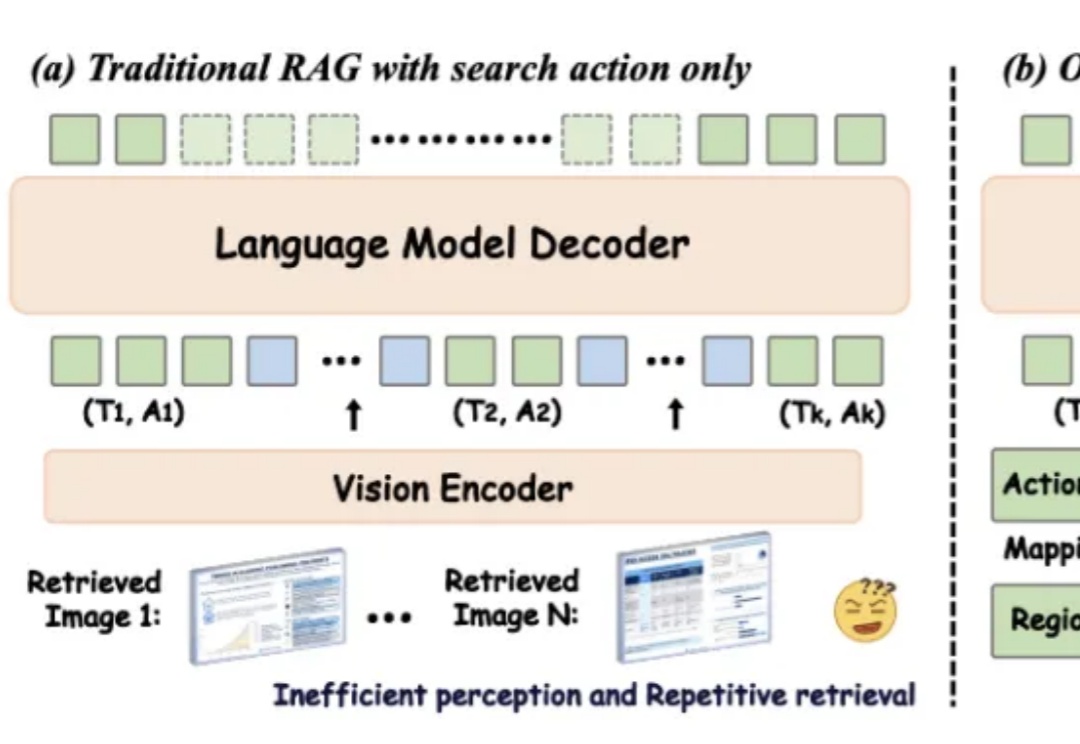
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。
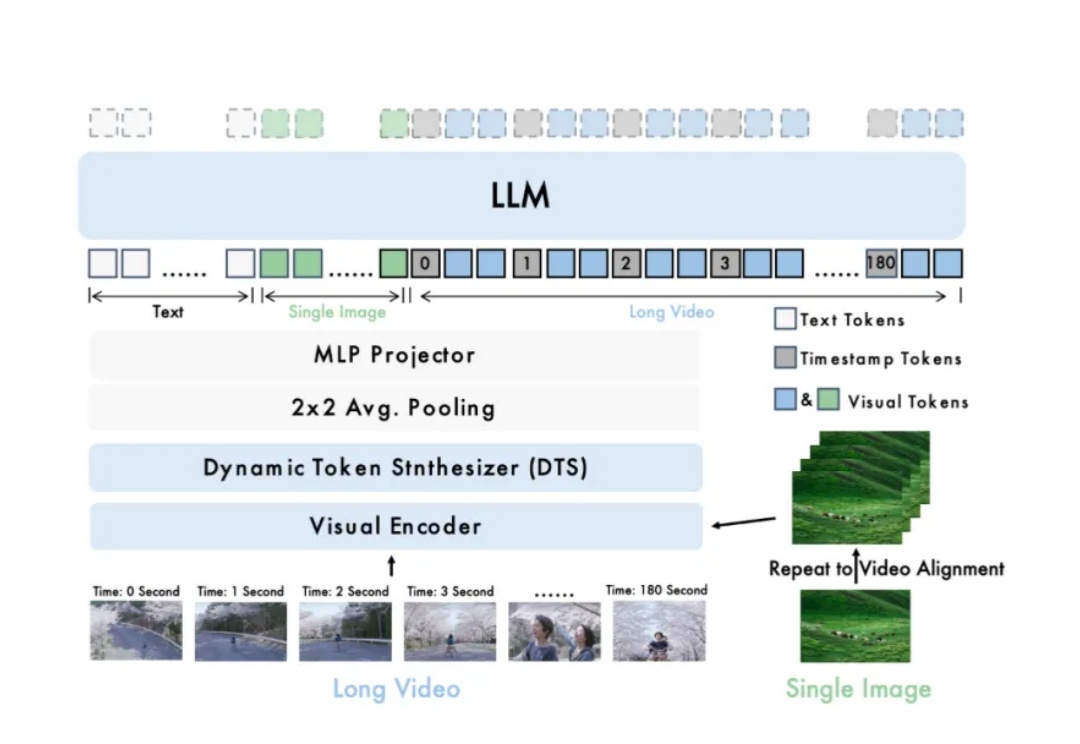
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。

生成式AGI已经颠覆了人们的生活,但AI工具并没有随着用户使用场景的融合而整合。各个赛道的头部玩家依靠独家的数据库发展模型,现有算力和数据量难以支撑多模态和跨业务领域拓展,急需形成用户粘性的市场竞争也使得AI的生成稳定性被优先考虑。
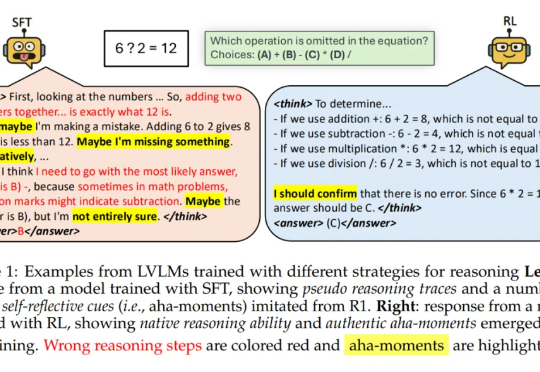
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」
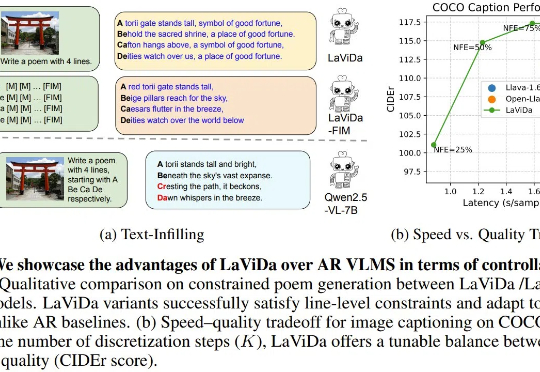
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。
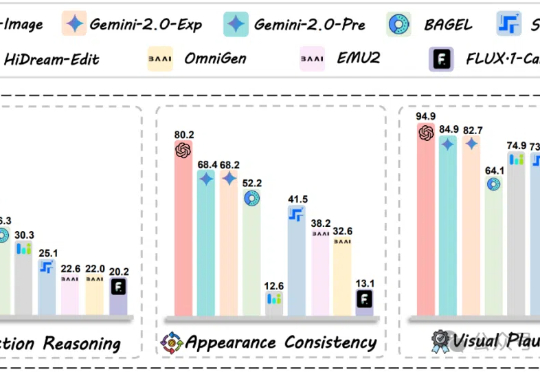
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。
字节跳动开源了一个口碑还不错的模型——BAGEL (ByteDance Agnostic Generation and Empathetic Language model), 一个统一多模态基础模型。啥叫“统一”?一个模型就能同时理解和生成文本、图像、视频!