CLIP被淘汰了?LeCun谢赛宁新作,多模态训练无需语言监督更强!
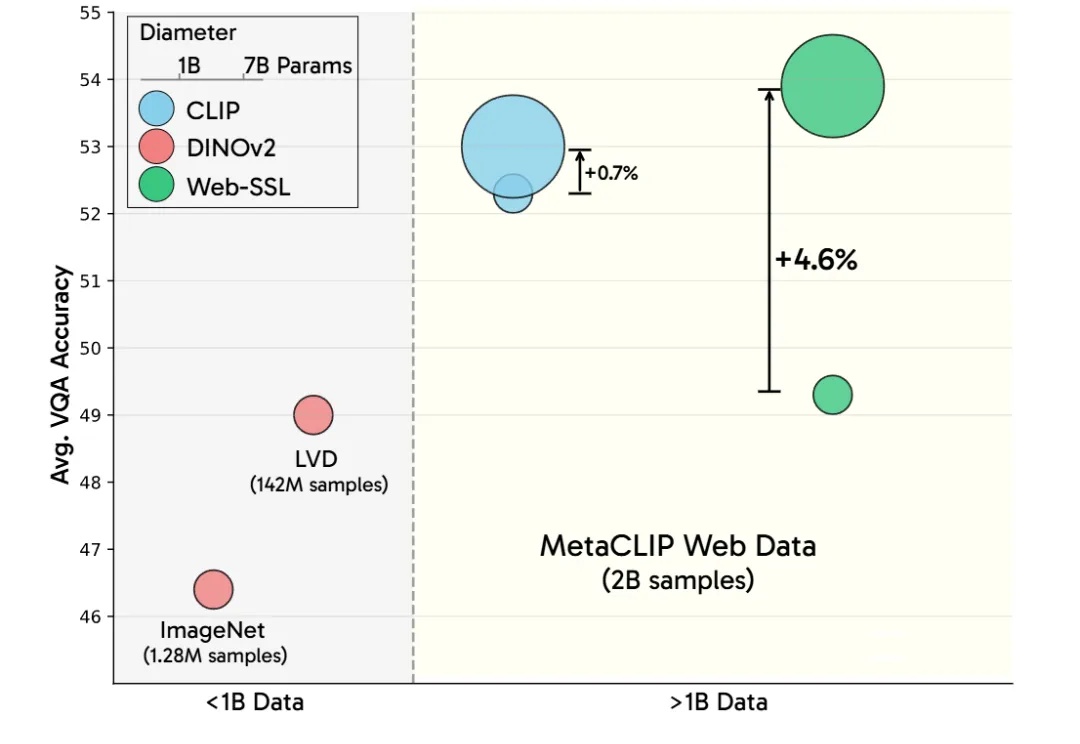
CLIP被淘汰了?LeCun谢赛宁新作,多模态训练无需语言监督更强!LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
来自主题: AI技术研报
9554 点击 2025-04-07 15:09
 搜索
搜索
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
Llama 4家族周末突袭,实属意外。这场AI领域的「闪电战」不仅带来了两款全新架构的开源模型,更揭示了一个惊人事实:苹果Mac设备或将成为部署大型AI模型的「性价比之王」。

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。
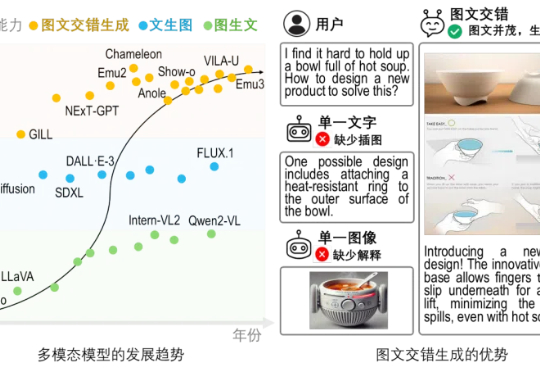
文生图 or 图生文?不必纠结了!
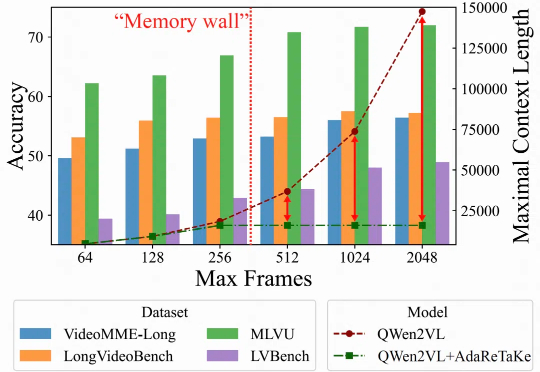
随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。长视频理解能力,对于智慧安防、智能体的长期记忆以及多模态深度思考能力有着重要价值。

近来风头正盛的GPT-4.5,不仅在日常问答中展现出惊人的上下文连贯性,在设计、咨询等需要高度创造力的任务中也大放异彩。
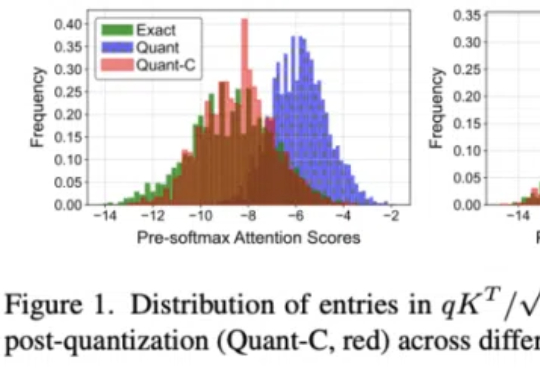
在InternVL-2.5上实现10倍吞吐量提升,模型性能几乎无损失。
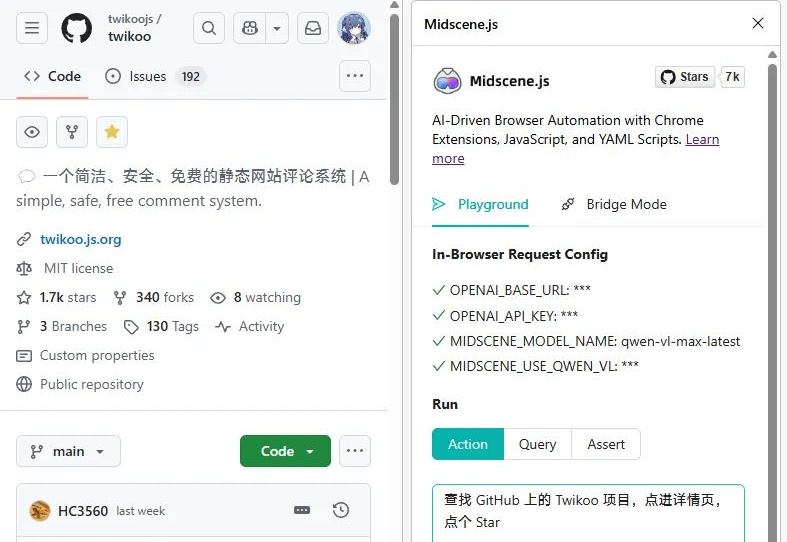
字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。

最近,ChatGPT 4o 新上线了多模态绘图功能,‘吉卜力’刷爆了特工们朋友圈的同时,也夹带着艺术设计圈朋友们的哀嚎,最让我们共情的莫过于推上的此段发言: