Cell | 想做多模态和可解释性一定要看,这篇论文不仅方法可圈可点,图也绘制的非常漂亮!
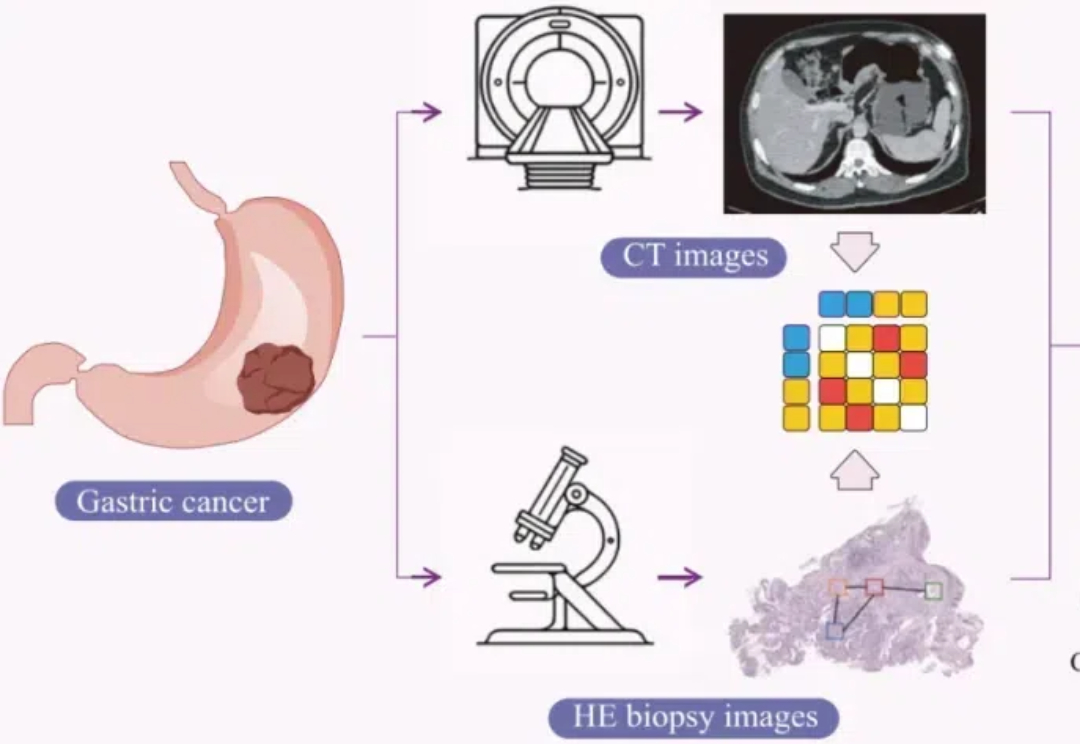
Cell | 想做多模态和可解释性一定要看,这篇论文不仅方法可圈可点,图也绘制的非常漂亮!Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。
来自主题: AI技术研报
8487 点击 2024-12-09 10:58
 搜索
搜索
Cell Reports Medicine近期的研究结合CT和病理图像,提出一种可解释的人工智能框架用于预测胃癌患者新辅助化疗的疗效。

以 GPT4V 为代表的多模态大模型(LMMs)在大语言模型(LLMs)上增加如同视觉的多感官技能,以实现更强的通用智能。虽然 LMMs 让人类更加接近创造智慧,但迄今为止,我们并不能理解自然与人工的多模态智能是如何产生的。
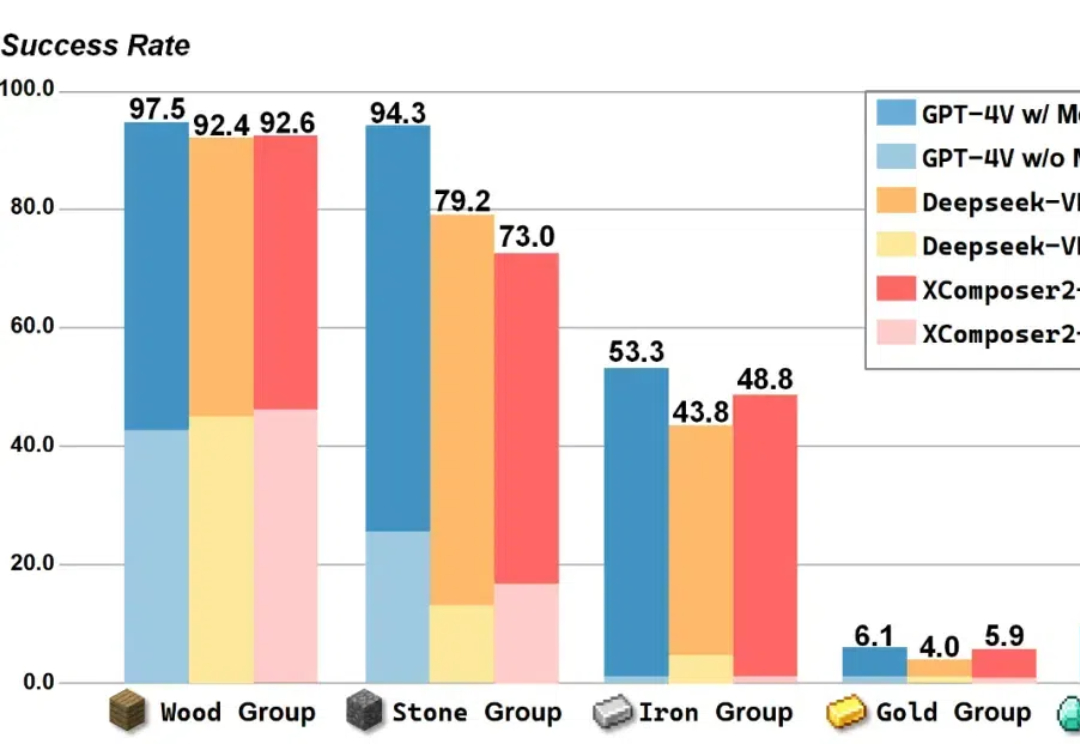
在 Minecraft 中构造一个能完成各种长序列任务的智能体,颇有挑战性。现有的工作利用大语言模型 / 多模态大模型生成行动规划,以提升智能体执行长序列任务的能力。

就在刚刚,满血版o1震撼上线了!它首次将多模态和新的推理范式结合起来,更智能、更快速。同时推出的还有200美元/月的专业版ChatGPT Pro。奥特曼亲自和Jason Wei等人做了演示,同时放出的,还有49页完整论文。据网友预测,GPT-4.5可能也要来了。

近日,眼科医学领域迎来了一项重大突破,由北京同仁眼科中心主任、河南省医学科学院院长王宁利教授领衔的科研团队携手成都中医药大学眼科学院/附属银海眼科医院段俊国教授科研团队等多个团队共同研发出了国内首个多模态、多任务眼科AI大模型——“伏羲慧眼”。
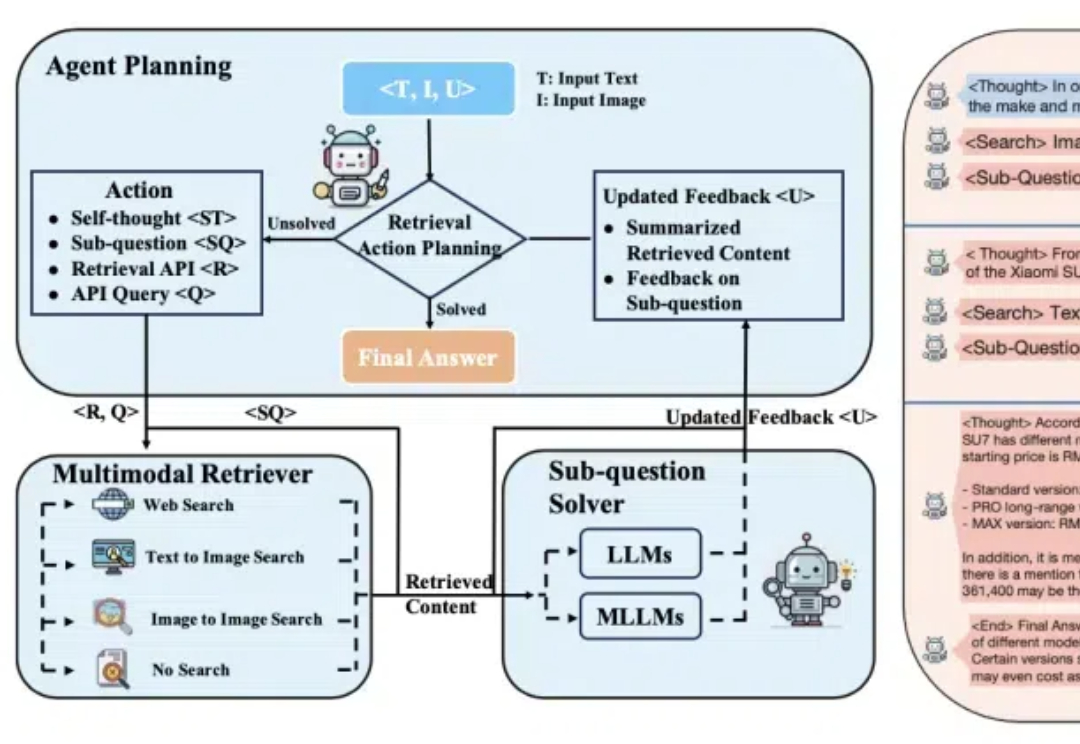
多模态检索增强生成(mRAG)也有o1思考推理那味儿了! 阿里通义实验室新研究推出自适应规划的多模态检索智能体。 名叫OmniSearch,它能模拟人类解决问题的思维方式,将复杂问题逐步拆解进行智能检索规划。

围剿英伟达,数十万颗自研二代芯片超算在建!亚马逊祭出地表最强全家桶,多模态Nova击败GPT-4o。

2024 年 12 月 1 月下午,奇绩创坛在北京中关村国际创新中心举办了 2024 年秋季创业营路演日,共有 60 家奇绩投资并加速的公司参与了路演。前沿创新信号:大模型(49 家),多模态(28 家),数据(24 家),具身智能(14 家),仿真(4 家)。
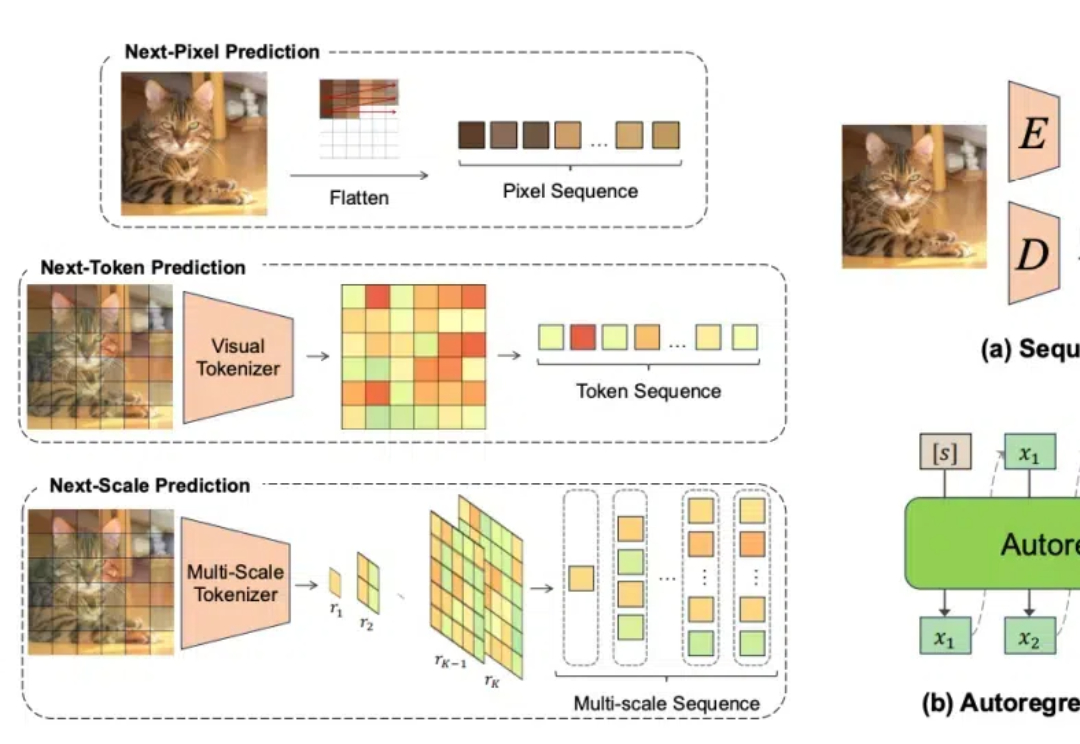
随着计算机视觉领域的不断发展,自回归模型作为一种强大的生成模型,在图像生成、视频生成、3D 生成和多模态生成等任务中展现出了巨大的潜力。然而,由于该领域的快速发展,及时、全面地了解自回归模型的研究现状和进展变得至关重要。本文旨在对视觉领域中的自回归模型进行全面综述,为研究人员提供一个清晰的参考框架。
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。