
首个多模态视频竞技场Video-MME来了!Gemini全面超越GPT-4o,Jeff Dean连转三次
首个多模态视频竞技场Video-MME来了!Gemini全面超越GPT-4o,Jeff Dean连转三次近日,首个多模态LLM视频分析综合评估基准Video-MME诞生!在这场全新的考试中,Gemini 1.5 Pro一路遥遥领先,谷歌首席科学家Jeff Dean更是愉快地连续转了3次推。
来自主题: AI资讯
5337 点击 2024-06-28 16:24
 搜索
搜索
近日,首个多模态LLM视频分析综合评估基准Video-MME诞生!在这场全新的考试中,Gemini 1.5 Pro一路遥遥领先,谷歌首席科学家Jeff Dean更是愉快地连续转了3次推。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。

近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。

当前的多模态和多任务基础模型,如 4M 或 UnifiedIO,显示出有希望的结果。然而,它们接受不同输入和执行不同任务的开箱即用能力,受到它们接受训练的模态和任务的数量(通常很少)的限制。

现在,AI 大模型可以真正与物理世界结合了。

最近,松鼠Ai的多模态智适应教育大模型全新升级了!大模型凭借多模态的功能,深度解析学生解题过程的每一步,降低学生学习的苦楚,全新多款松鼠Ai智能老师登场,精确匹配不同学习者的需求层次。

挖掘并建模多模态、多层次、多角度的AI合成线索。
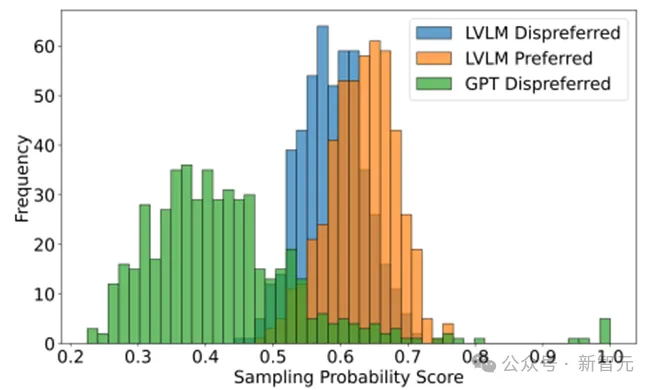
现有多模态大模型在对齐不同模态时面临幻觉和细粒度感知不足等问题,传统偏好学习方法依赖可能不适配的外源数据,存在成本和质量问题。Calibrated Self-Rewarding(CSR)框架通过自我增强学习,利用模型自身输出构造更可靠的偏好数据,结合视觉约束提高学习效率和准确性。
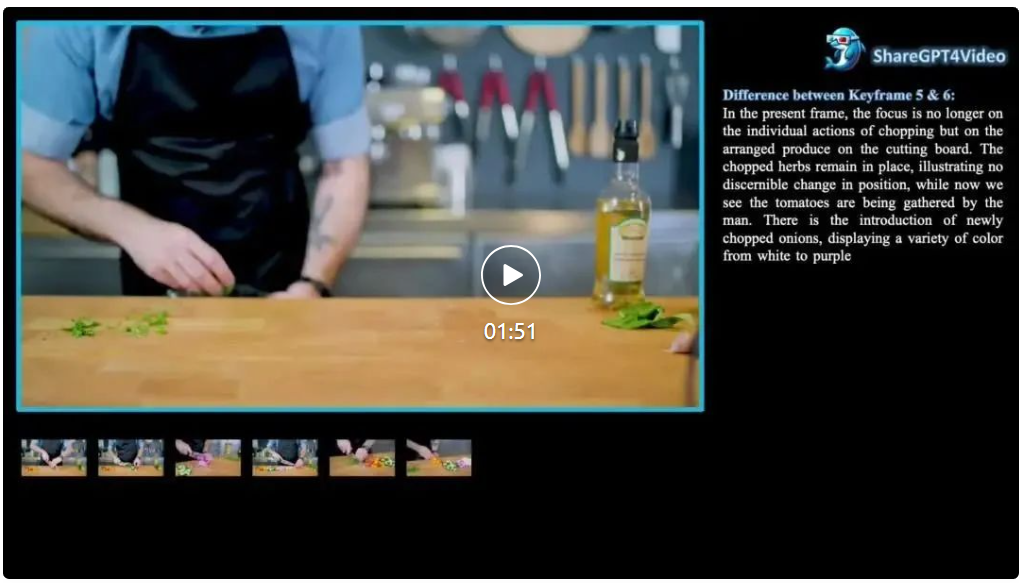
继Sora官宣之后,多模态大模型在视频生成方面的应用简直就像井喷一样涌现出来,LUMA、Gen-3 Alpha等视频生成模型展现了极佳质量的艺术风格和视频场景的细节雕刻能力,文生视频、图生视频的新前沿不断被扩展令大家惊喜不已,抱有期待。

机器人操纵的一个基本目标是使模型能够理解视觉场景并执行动作。