
Mistral多模态大模型来了!120亿参数,原生支持任意大小/数量图像,公司估值已达420亿
Mistral多模态大模型来了!120亿参数,原生支持任意大小/数量图像,公司估值已达420亿Mistral的多模态大模型来了!Pixtral 12B正式发布,同时具备语言和视觉处理能力。
来自主题: AI资讯
5524 点击 2024-09-12 15:04
 搜索
搜索
Mistral的多模态大模型来了!Pixtral 12B正式发布,同时具备语言和视觉处理能力。

在AI-2.0时代,OCR模型的研究难道到头了吗!?

本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天内在 github 上斩获 1000+ 星标。

近年来,大模型在人工智能领域掀起了一场革命,各种文本、图像、多模态大模型层出不穷,已经深深地改变了人们的工作和生活方式。
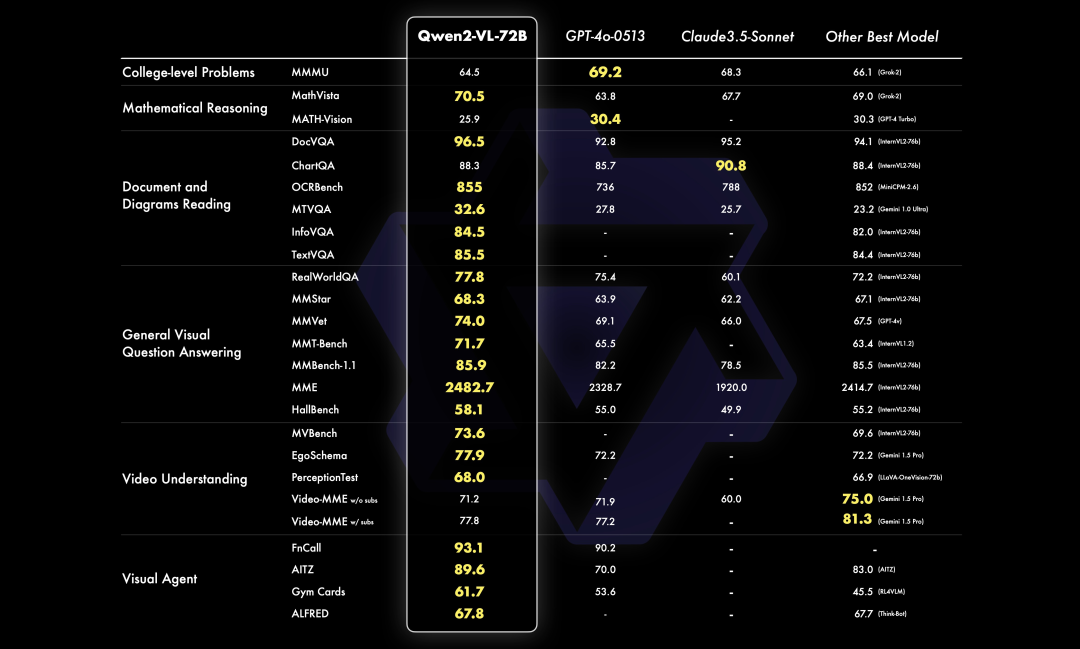
新的最强开源多模态大模型来了!

以 GPT 为代表的大型语言模型预示着数字认知空间中通用人工智能的曙光。这些模型通过处理和生成自然语言,展示了强大的理解和推理能力,已经在多个领域展现出广泛的应用前景。无论是在内容生成、自动化客服、生产力工具、AI 搜索、还是在教育和医疗等领域,大型语言模型都在不断推动技术的进步和应用的普及。

本期我们邀请到了 纽约大学计算机科学院博士 童晟邦 带来【多模态大模型:视觉为中心的探索】的主题分享。

4秒看完2小时电影,阿里团队新成果正式亮相——

只用提示词,多模态大模型就能更懂场景中的人物关系了。

李飞飞老师提出了空间智能 (Spatial Intelligence) 这一概念,作为回应,来自上交、斯坦福、智源、北大、牛津、东大的研究者提出了空间大模型 SpatialBot,并提出了训练数据 SpatialQA 和测试榜单 SpatialBench, 尝试让多模态大模型在通用场景和具身场景下理解深度、理解空间。