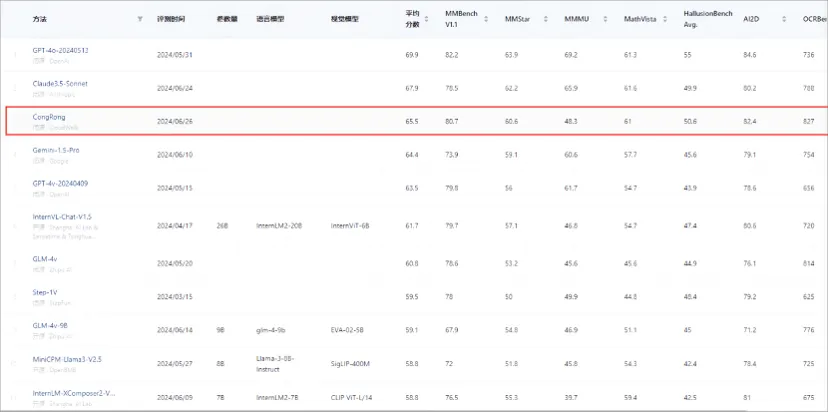
多模态能力全球TOP3,来自中国从容大模型
多模态能力全球TOP3,来自中国从容大模型国产多模态大模型的头号交椅,再次易主
来自主题: AI资讯
7529 点击 2024-07-02 18:20
 搜索
搜索
国产多模态大模型的头号交椅,再次易主

Claude 3.5 Sonnet的图表推理能力,比GPT-4o高出了27.8%。 针对多模态大模型在图表任务上的表现,陈丹琦团队提出了新的测试基准。 新Benchmark比以往更有区分度,也让一众传统测试中的高分模型暴露出了真实能力。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。
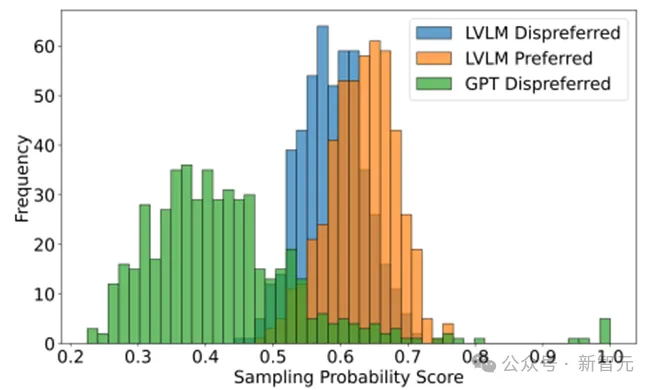
现有多模态大模型在对齐不同模态时面临幻觉和细粒度感知不足等问题,传统偏好学习方法依赖可能不适配的外源数据,存在成本和质量问题。Calibrated Self-Rewarding(CSR)框架通过自我增强学习,利用模型自身输出构造更可靠的偏好数据,结合视觉约束提高学习效率和准确性。
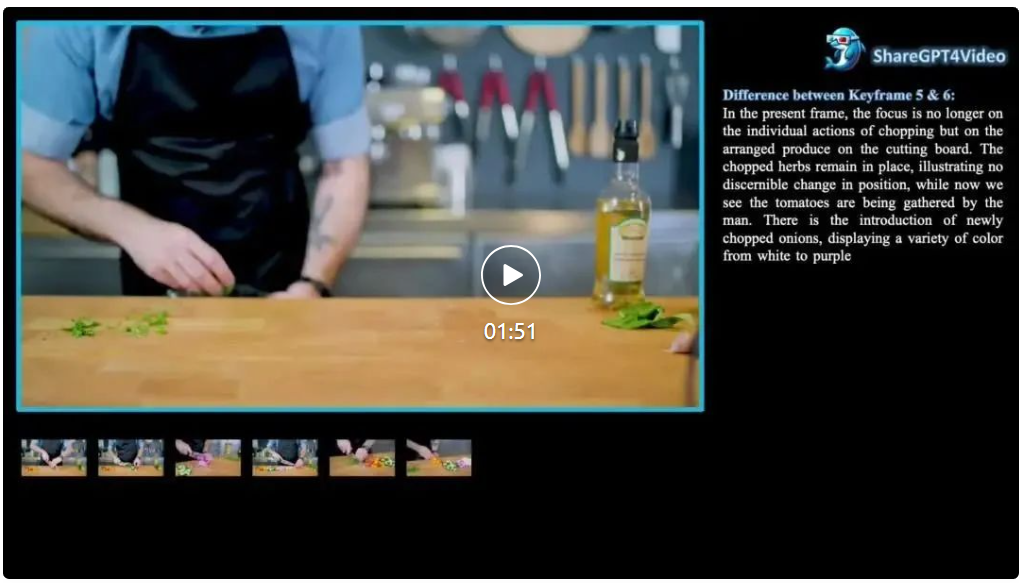
继Sora官宣之后,多模态大模型在视频生成方面的应用简直就像井喷一样涌现出来,LUMA、Gen-3 Alpha等视频生成模型展现了极佳质量的艺术风格和视频场景的细节雕刻能力,文生视频、图生视频的新前沿不断被扩展令大家惊喜不已,抱有期待。

机器人操纵的一个基本目标是使模型能够理解视觉场景并执行动作。
图灵奖得主Hinton在他的访谈中提及「在未来20年内,AI有50%的概率超越人类的智能水平」,并建议各大科技公司早做准备,而评定大模型(包括多模态大模型)的「智力水平」则是这一准备的必要前提。
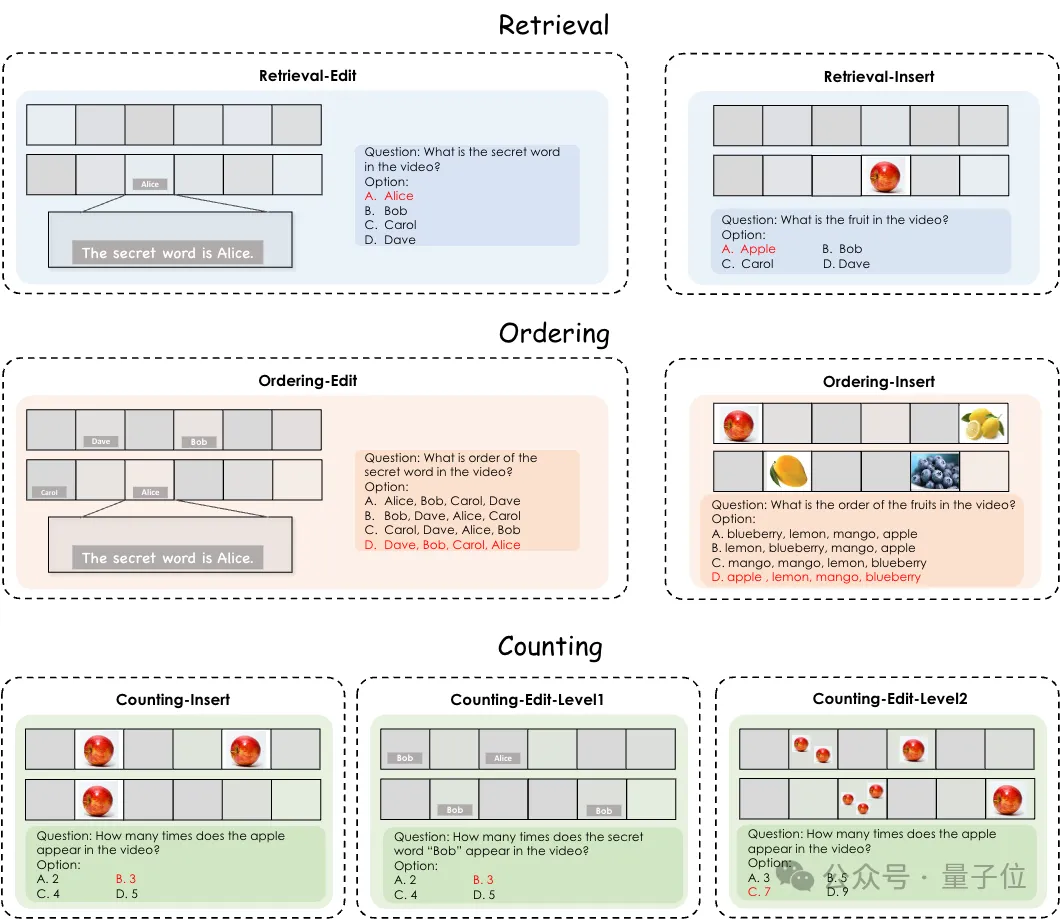
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。

苹果OpenAI官宣合作,GPT-4o加持Siri,让AI个性化生成赛道热度飙升。
OpenAI和谷歌接连两场发布会,把AI视频推理卷到新高度。 但业界还缺少可以全面评估大模型视频推理能力的基准。 终于,多模态大模型视频分析综合评估基准Video-MME,全面评估多模态大模型的综合视频理解能力,填补了这一领域的空白。