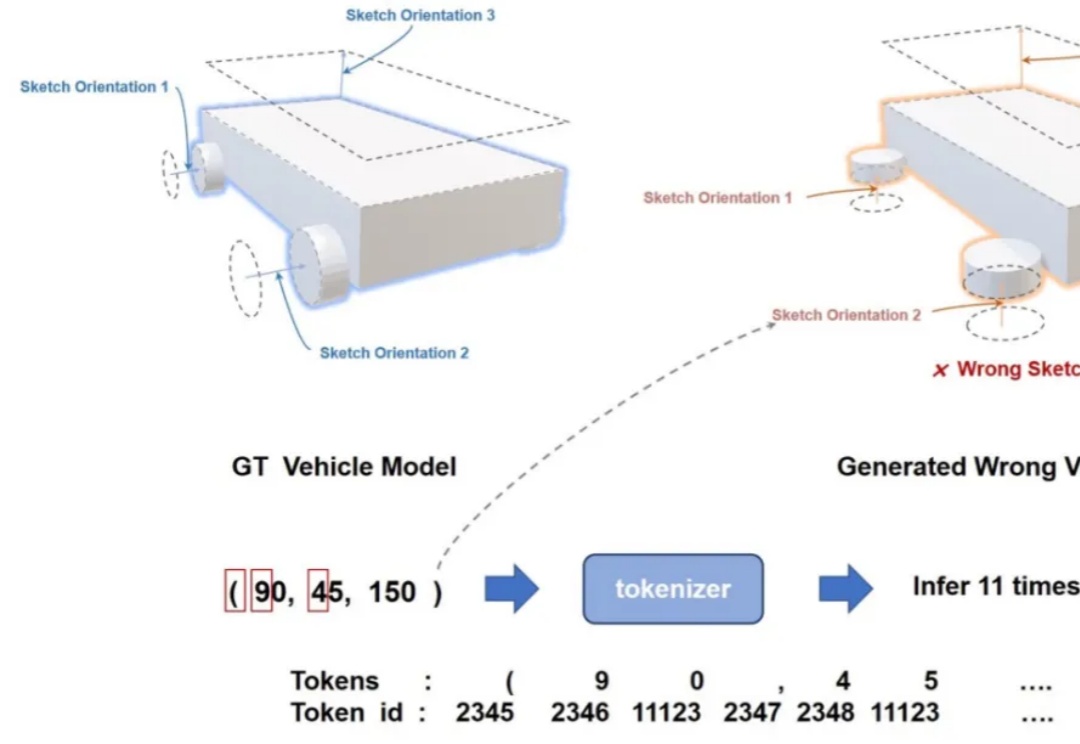
AAAI 2025 | 多模态大语言模型空间智能新探索:仅需单张图片或一句话,就可以精准生成3D建模代码啦!
AAAI 2025 | 多模态大语言模型空间智能新探索:仅需单张图片或一句话,就可以精准生成3D建模代码啦!计算机辅助设计(CAD)已经成为许多行业设计、绘图和建模的标准方法。如今,几乎每一个制造出来的物体都是从参数化 CAD 建模开始的。
来自主题: AI技术研报
3901 点击 2025-01-03 16:07
 搜索
搜索
计算机辅助设计(CAD)已经成为许多行业设计、绘图和建模的标准方法。如今,几乎每一个制造出来的物体都是从参数化 CAD 建模开始的。
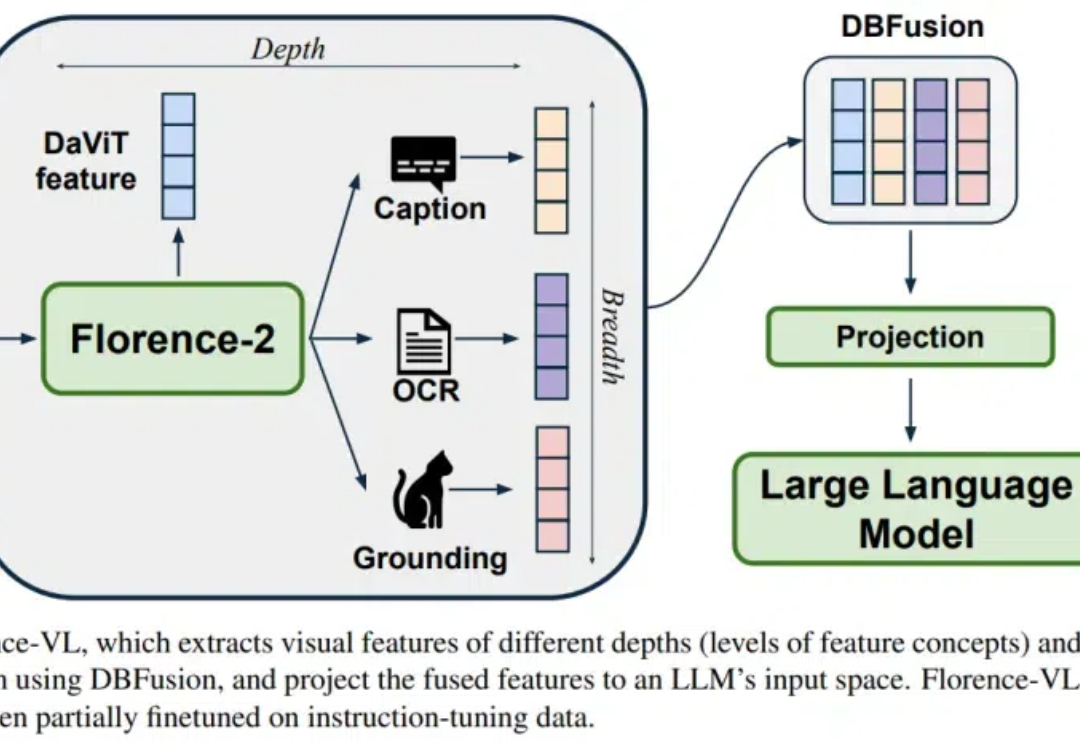
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
AtomThink 是一个包括 CoT 注释引擎、原子步骤指令微调、政策搜索推理的全流程框架,旨在通过将 “慢思考 “能力融入多模态大语言模型来解决高阶数学推理问题。量化结果显示其在两个基准数学测试中取得了大幅的性能增长,并能够轻易迁移至不同的多模态大模型当中。

多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。

视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。

视频理解仍然是计算机视觉和人工智能领域的一个主要挑战。最近在视频理解上的许多进展都是通过端到端地训练多模态大语言模型实现的[1,2,3]。然而,当这些模型处理较长的视频时,内存消耗可能会显著增加,甚至变得难以承受,并且自注意力机制有时可能难以捕捉长程关系 [4]。这些问题阻碍了将端到端模型进一步应用于视频理解。

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。 特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。