
统一图像生成,无需繁杂插件!智源发布扩散模型框架OmniGen
统一图像生成,无需繁杂插件!智源发布扩散模型框架OmniGen多模态模型,统一图像生成。
来自主题: AI资讯
8043 点击 2024-10-30 13:39
 搜索
搜索
多模态模型,统一图像生成。
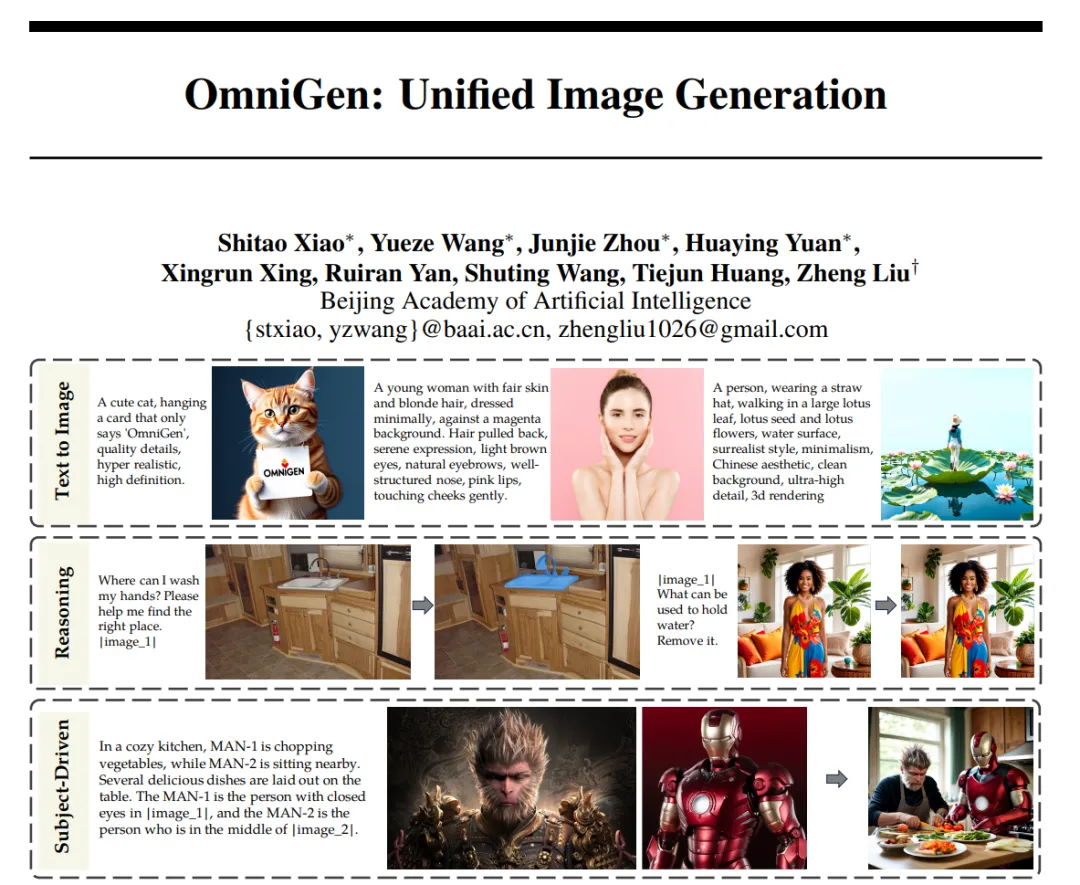
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

两位清华校友,在OpenAI发布最新研究—— 生成图像,但速度是扩散模型的50倍。 路橙、宋飏再次简化了一致性模型,仅用两步采样,就能使生成质量与扩散模型相媲美。

OpenAI 前首席科学家、联合创始人 Ilya Sutskever 曾在多个场合表达观点:只要能够非常好的预测下一个 token,就能帮助人类达到通用人工智能(AGI)。

多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。

如果您正在探寻人工智能未来的辉煌篇章,那么答案就在这里。 OpenAI的领导者Sam Altman和Greg Brockman最近表示:“现在正是我们展望未来的最佳时机。”他们预见了一个新时代,用户将不再只是与单一的模型对话,而是与由众多多模态模型和工具构成的系统互动,这些系统能够代表用户执行操作。

Molmo,开源多模态模型正在发力!

视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。

一条磁力链,又在AI圈掀起狂澜。成立一年法国AI独角兽Mistral,官宣首个多模态模型Pixtral 12B,不仅能看懂手绘稿,还可以理解复杂公式、图表。

在AI-2.0时代,OCR模型的研究难道到头了吗!?