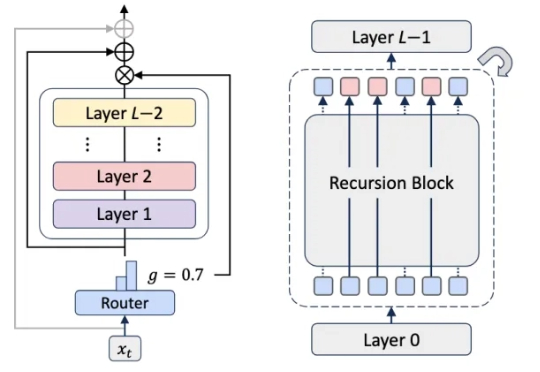
「有望成为Transformer杀手」,谷歌DeepMind新架构MoR实现两倍推理速度
「有望成为Transformer杀手」,谷歌DeepMind新架构MoR实现两倍推理速度大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
来自主题: AI技术研报
7775 点击 2025-07-18 11:58
 搜索
搜索
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
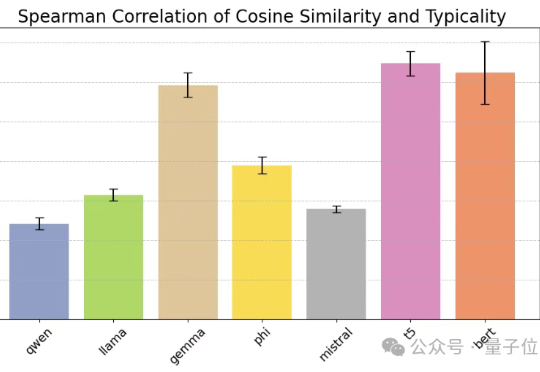
那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:LLM偏向极致的统计压缩,而人类更重细节与语境。
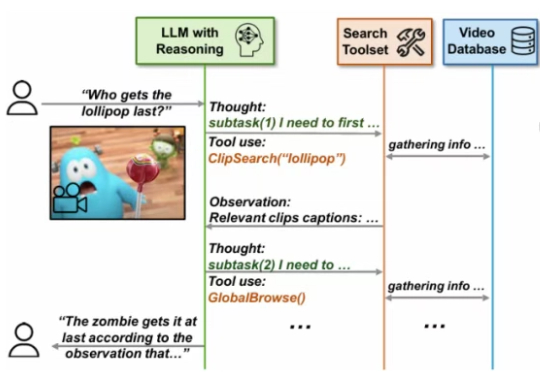
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。
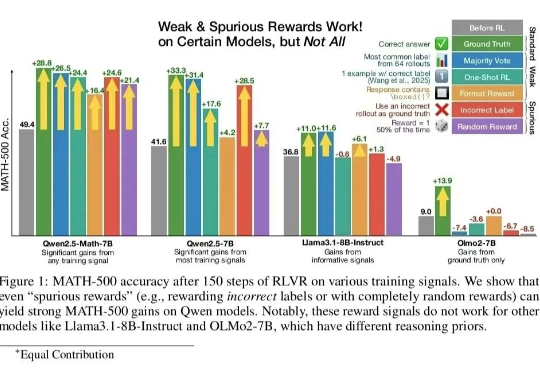
在人工智能领域,大型语言模型(LLM)的推理能力正以前所未有的速度发展。
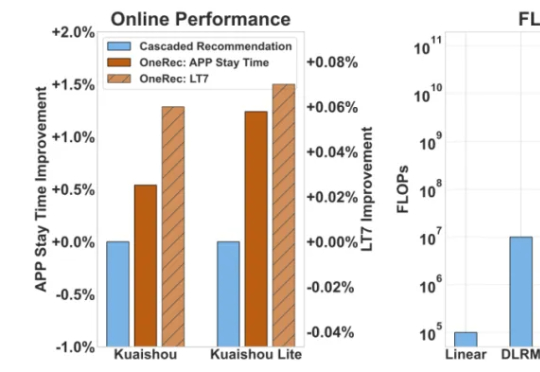
人人都绕不开的推荐系统,如今正被注入新的 AI 动能。 随着 AI 领域掀起一场由大型语言模型(LLM)引领的生成式革命,它们凭借着强大的端到端学习能力、海量数据理解能力以及前所未有的内容生成潜力,开始重塑各领域的传统技术栈。
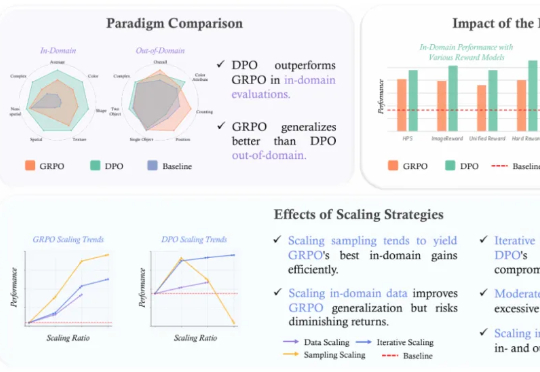
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。

近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。

搜索行为从传统浏览器向大型语言模型(LLM)平台迁移,价值超800亿美元的SEO市场根基已现裂痕,搜索迈入由语言模型主导的“生成式引擎优化(GEO)”全新范式。
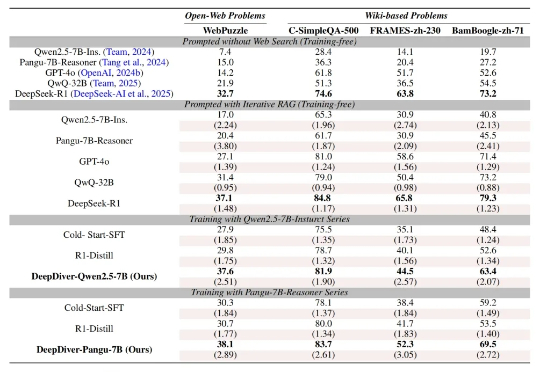
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?