Claude都能操纵计算机了,吴恩达:智能体工作流越来越成熟
Claude都能操纵计算机了,吴恩达:智能体工作流越来越成熟受 ChatGPT 强大问答能力的影响,大型语言模型(LLM)提供商往往优化模型来回答人们的问题,以提供良好的消费者体验。
来自主题: AI资讯
5124 点击 2024-11-15 15:04
 搜索
搜索
受 ChatGPT 强大问答能力的影响,大型语言模型(LLM)提供商往往优化模型来回答人们的问题,以提供良好的消费者体验。

Recraft团队通过结合TextDiffuser-2技术和自训练的大型语言模型,提升了文本到图像渲染的质量和准确性,不过现有模型在处理复杂语言如中文和未明确指定的文本时,仍存在渲染不准确的问题。

研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!
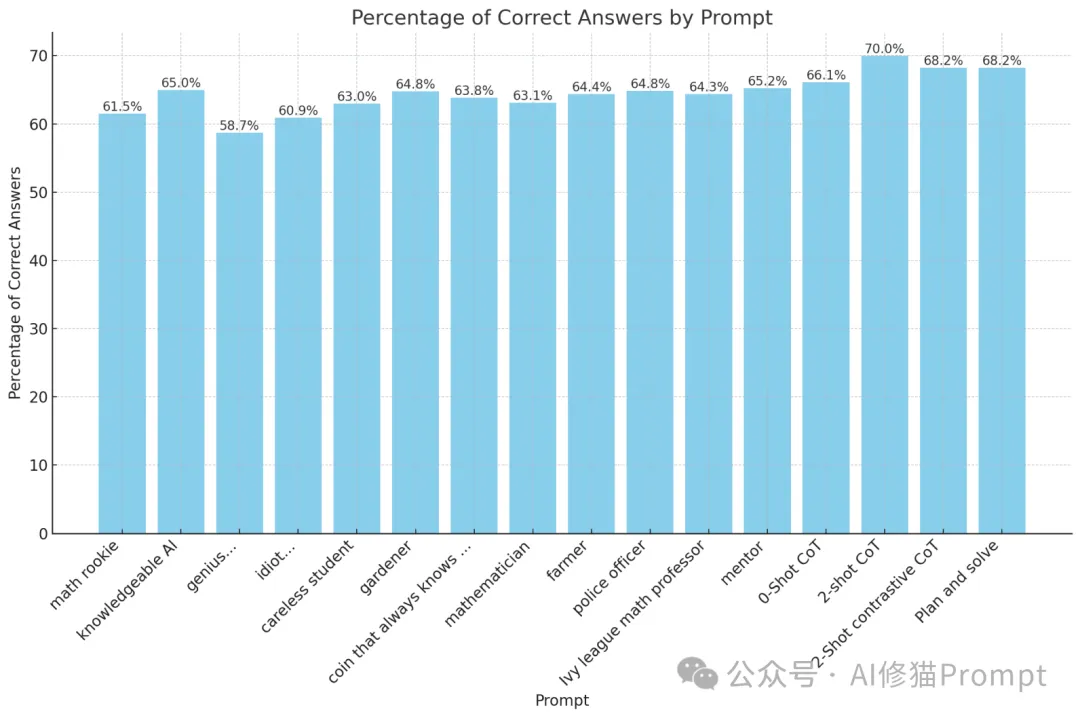
在Prompt工程领域,角色扮演提示是否能够有效提高大型语言模型(LLM)的性能一直是一个备受关注的话题。

MME-Finance 是一个专为金融领域设计的多模态基准测试,由同花顺财经旗下的 HiThink 研究团队联合多家高校共同开发,旨在评估和提升多模态大型语言模型(MLLMs)在金融领域的专业理解和推理能力。

现在正是多模态大模型的时代,图像、视频、音频、3D、甚至气象运动都在纷纷与大型语言模型的原生文本模态组合。而浙江大学及其计算机创新技术研究院的一个数十人团队也将结构化数据(包括数据库、数仓、表格、json 等)视为了一种独立模态。

在金融市场中,动态知识图谱(Dynamic Knowledge Graphs,DKGs)是一种表达对象之间随时间变化的多种关系的流行结构。它们可以有效地表示从复杂的非结构化数据源(如文本或图像)中提取的信息。在金融应用中,基于从金融新闻文章中获取的信息,DKGs 可用于检测战略性主题投资的趋势。
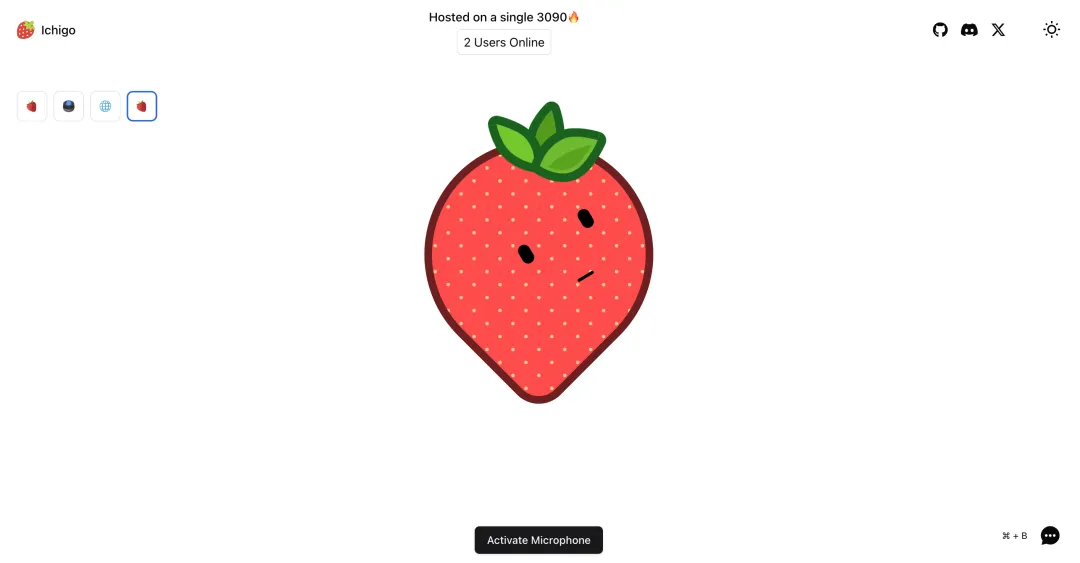
Ichigo[1] 是一个开放的、持续进行的研究项目,目标是将基于文本的大型语言模型(LLM)扩展,使其具备原生的“听力”能力。
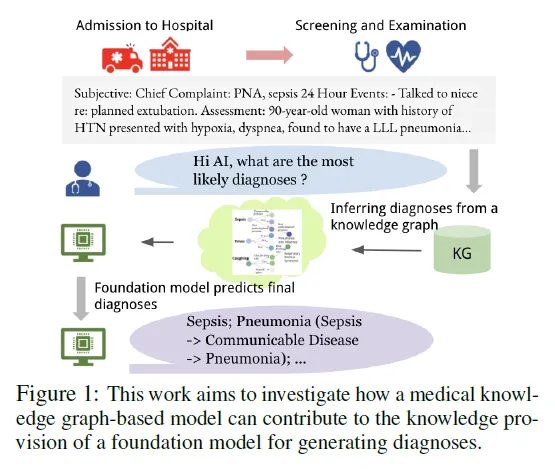
近年来,生成式大型语言模型(LLMs)在各类语言任务中的表现令人瞩目,但在医疗领域的应用面临诸多挑战,尤其是在减少诊断错误和避免对患者造成伤害方面。