ToMAP:赋予大模型「读心术」,打造更聪明的AI说服者
ToMAP:赋予大模型「读心术」,打造更聪明的AI说服者本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。
来自主题: AI资讯
9197 点击 2025-06-25 09:53
 搜索
搜索
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。

6月23日,山西临汾市人民医院发布了《基于DeepSeek AI大模型的智慧医疗应用系统建设项目》,预算金额为1569.264万元,预计采购时间为2025年9月。临汾市人民医院拟采购基于DeepSeek的智慧医疗项目建设一套,其建设内容包含:

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。
由数据分析领域资深人士联合创立的初创公司 Typedef, 今日结束隐匿运营状态 ,宣布获得由 Pear VC 领投的 550 万美元种子轮融资。
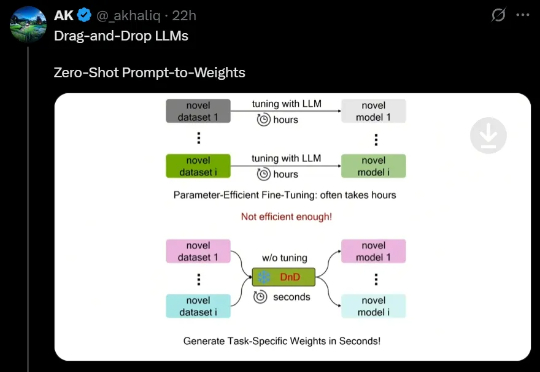
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

根据申妈朋友圈,字节跳动发布了新一期廉政通报,披露了一起涉及 Seed 团队高层的严重违规事件。据报道,Seed 大语言模型负责人乔木与其团队所配属的一名 HRBP 在未履行申报流程的情况下,发展成为亲密关系。

6月20日-22日,华为开发者大会2025(HDC 2025)于东莞举办,正式发布鸿蒙HarmonyOS 6操作系统及多项创新技术,来自全球各地的开发者、行业专家和合作伙伴齐聚现场,其中不乏AI+生物、医疗领域企业。
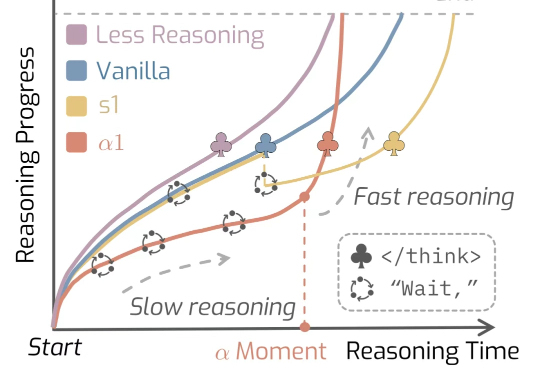
在思维节奏这件事上,人类早已形成一种独特而复杂的模式。

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。

《读佳》获悉,字节的UserGrowth(用户增长团队)做了一个名为”探饭“的AI产品,搭载的是豆包大模型。