
千问电脑端上线语音输入法——大模型公司为什么都在抢这个入口?
千问电脑端上线语音输入法——大模型公司为什么都在抢这个入口?我最近买了一个这样的键盘——
来自主题: AI资讯
6520 点击 2026-05-07 11:00
 搜索
搜索
我最近买了一个这样的键盘——
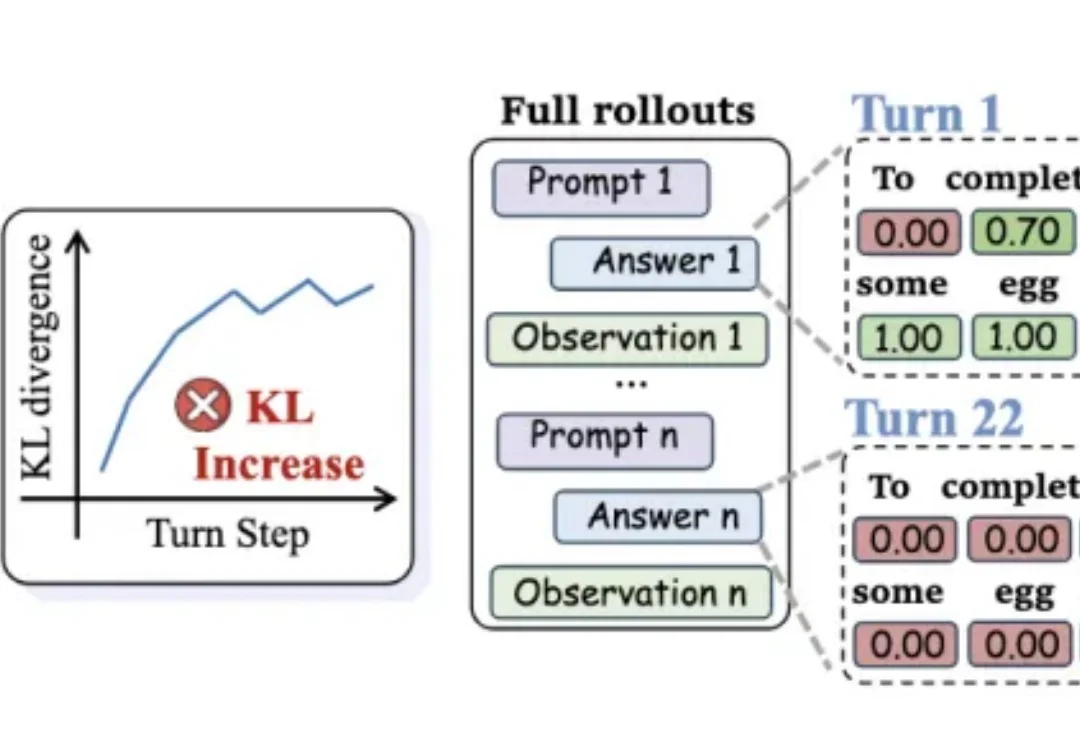
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

在对多位内部开发者的采访中得知,这个模型的研发已被叫停。LPM 1.0 并非仍在推进的核心项目,而是视频团队对过去一年工作成果的集中汇报——既是对外展示,也是对内总结。该视频团队由“童姥”( 前微软亚研院首席研究员童欣) 带领, AilingZeng做Tech Lead,作者中近半数来自 Anuttacon内部,蔡浩宇本人并未直接参与模型研发。
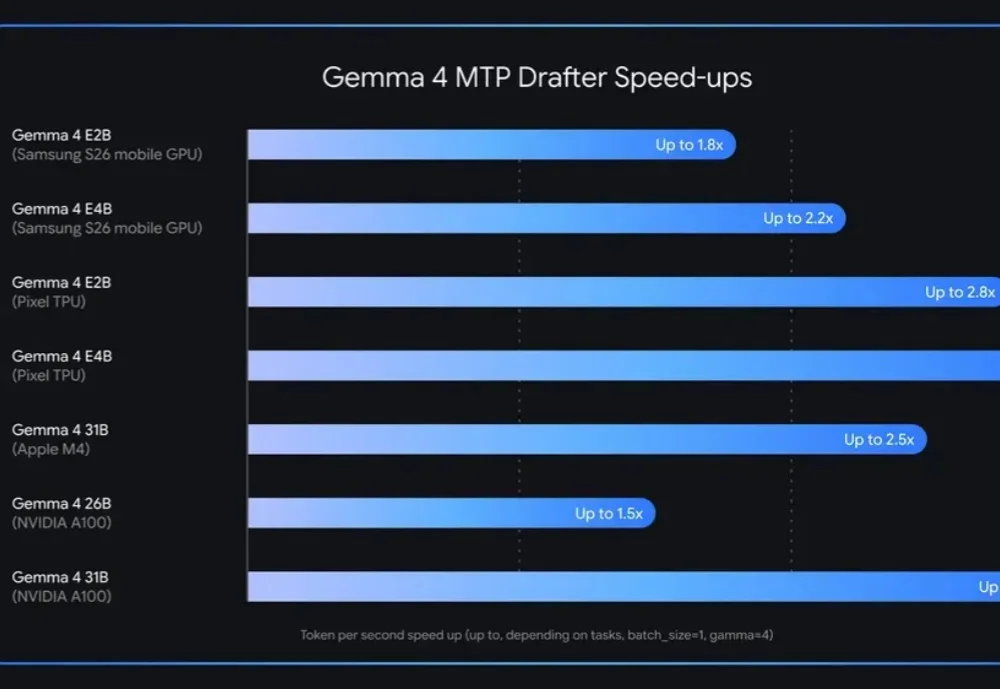
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。

独家获悉,RoboScience 机器科学于近日完成十亿元 A 轮融资,投资方包含多家国内外知名产业巨头及一线财务机构。本轮融资将用于持续深化其核心的 VLOA 大模型技术,以及推进自研机器人本体的工程化与量产,加速通用具身智能解决方案的规模化落地。
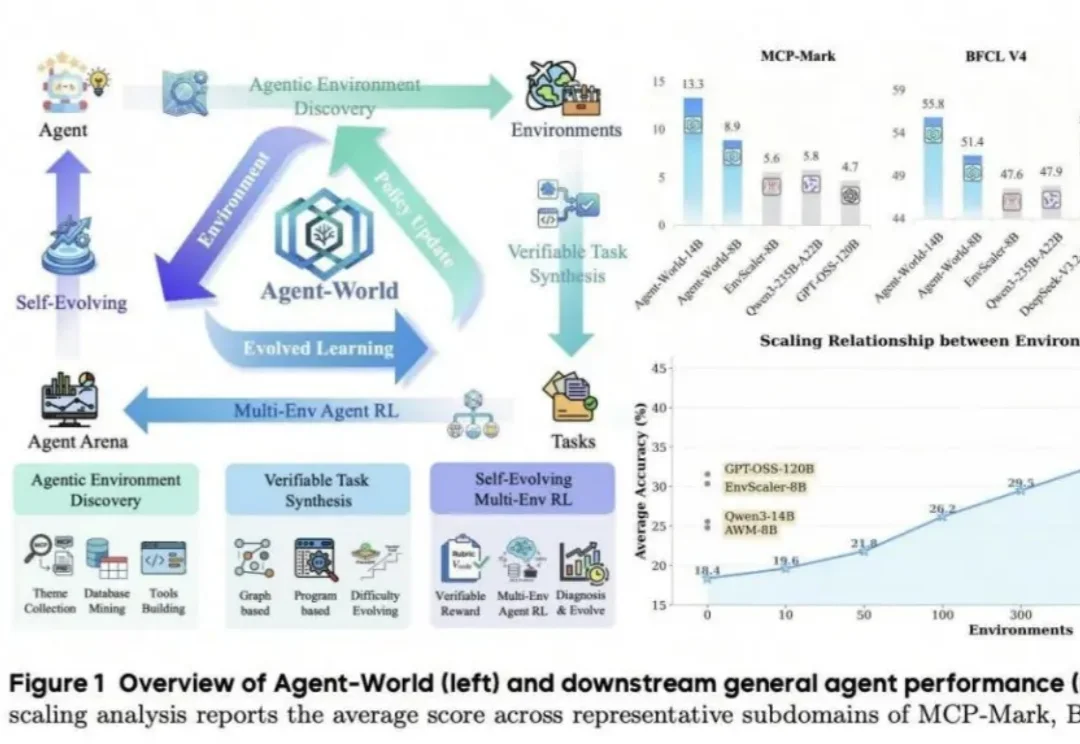
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。

随着AI大模型与生成式搜索全面普及,营销行业正迎来从传统搜索优化向AI原生优化的关键转型。GEO是适配AI问答、智能推荐的新一代营销体系,正在重新定义品牌与用户的信息连接方式。

独家获悉,字节跳动旗下AI应用“豆包”最快将于5月中下旬上线首款付费包月产品:豆包会员。具体来说,豆包会员分为标准版、加强版、专业版三个版本,iOS版内购价格最低68元人民币起,最高年费达5088元,会员权益有望增加Seedance 2.0生视频额度等功能。