
国产AI六小虎已经有俩变病猫,他们活下去的理由不好找
国产AI六小虎已经有俩变病猫,他们活下去的理由不好找昨天,是国产 AI 六小虎之一百川智能成立的两周年,CEO 王小川发布全员信强调公司方向: “ 减少多余动作,专注医学方向。”要知道,两年前,百川智能刚成立的时候,其愿景可是 “ 旨在打造中国版的 OpenAI 基础大模型及颠覆性上层应用 ”,非常宏大。
来自主题: AI资讯
10245 点击 2025-04-12 11:00
 搜索
搜索
昨天,是国产 AI 六小虎之一百川智能成立的两周年,CEO 王小川发布全员信强调公司方向: “ 减少多余动作,专注医学方向。”要知道,两年前,百川智能刚成立的时候,其愿景可是 “ 旨在打造中国版的 OpenAI 基础大模型及颠覆性上层应用 ”,非常宏大。

蚂蚁集团副总裁、前百灵大模型一号位徐鹏(花名:无改),已于近日离职;此外,据「市象」了解,基于蚂蚁百灵大模型的AI应用支小宝团队也在近期面临团队人员调整。
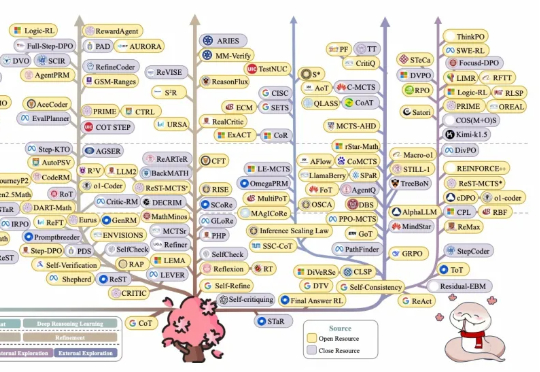
随着技术的深入应用,如何高效利用大模型技术优化用户体验,同时应对其带来的诸多挑战?本文将从RAG的发展趋势、技术挑战、核心举措以及未来展望四个维度总结我们应对挑战的新的思路和方法。

在 Gemini 的爆火之后,Google Cloud 正在成为真正意义上的「基础设施」。
当下,中国医疗行业正迎来一场硬核突围的历史性转折。面对供应链断裂、技术垄断多重封锁,国产医疗三剑客以技术为剑,以创新为盾,强势打破技术护城河。这将是一场从「跟跑」到「领跑」的逆袭之战。
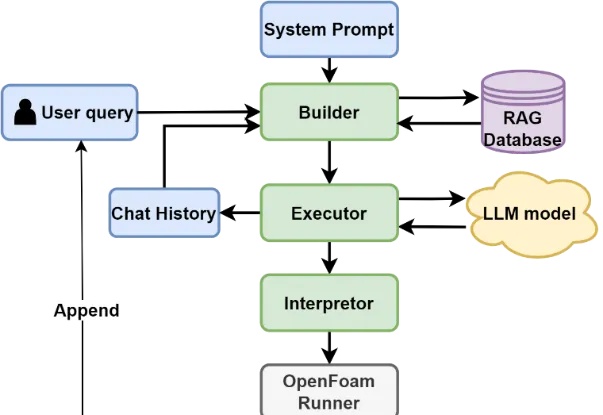
又一专业领域成功引入AI工程师!

在现实世界中,如何让智能体理解并挖掘 3D 场景中可交互的部位(Affordance)对于机器人操作与人机交互至关重要。所谓 3D Affordance Learning,就是希望模型能够根据视觉和语言线索,自动推理出物体可供哪些操作、以及可交互区域的空间位置,从而为机器人或人工智能系统提供对物体潜在操作方式的理解。

港中文、清华等高校提出SICOG框架,通过预训练、推理优化和后训练协同,引入自生成数据闭环和结构化感知推理机制,实现模型自我进化,为大模型发展提供新思路。
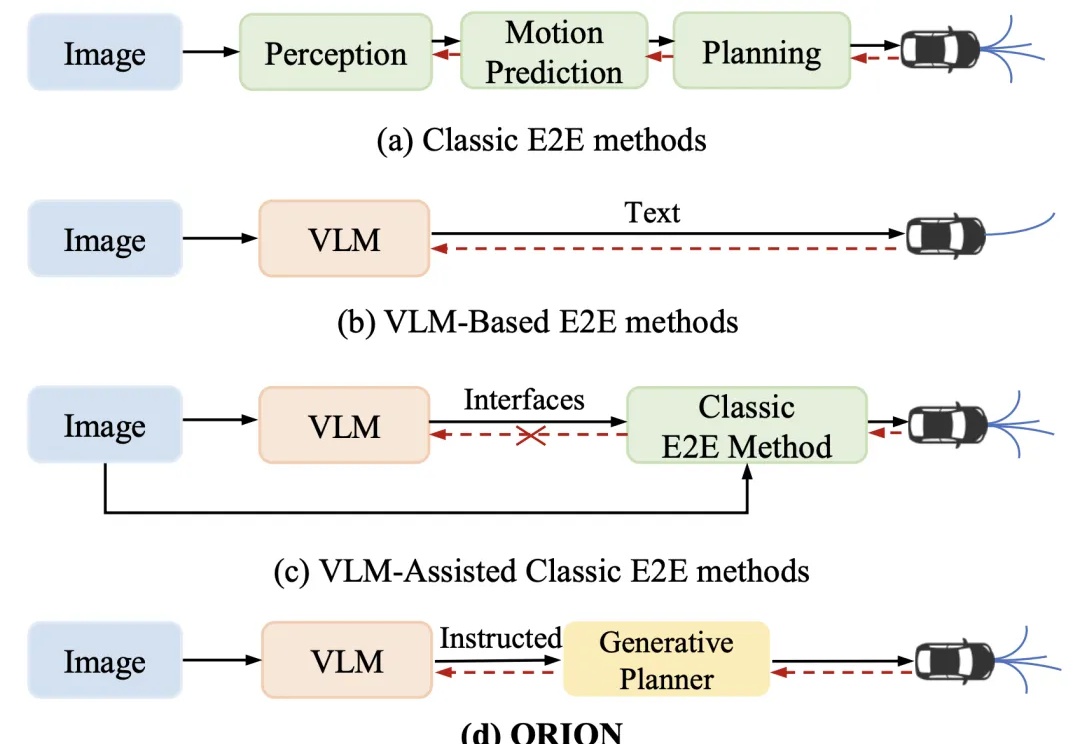
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。

商汤最新升级的日日新SenseNova V6解锁的新能力—— 原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3: