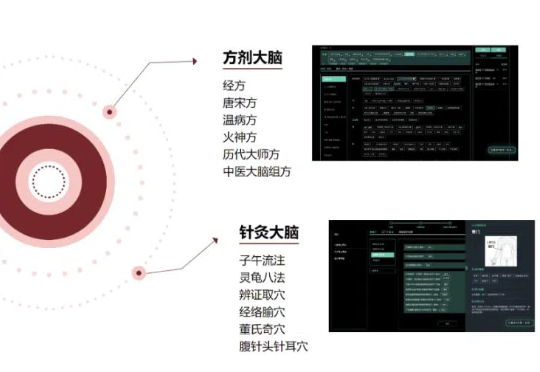
陷阱or风口?三年亏4亿,资本豪赌“AI中医”
陷阱or风口?三年亏4亿,资本豪赌“AI中医”2024年5月,归元堂生物获得君融健康产业投资超1000万元的天使轮投资,用于中医皮肤健康管理AI大模型研发。紧接着,12月,吾征智能完成数千万元的Pre-A轮融资,由仁毅资本领投,该公司致力于利用医学生物特征计算AI技术把“望闻问切”搬上互联网。
来自主题: AI资讯
10360 点击 2025-04-04 11:27
 搜索
搜索
2024年5月,归元堂生物获得君融健康产业投资超1000万元的天使轮投资,用于中医皮肤健康管理AI大模型研发。紧接着,12月,吾征智能完成数千万元的Pre-A轮融资,由仁毅资本领投,该公司致力于利用医学生物特征计算AI技术把“望闻问切”搬上互联网。
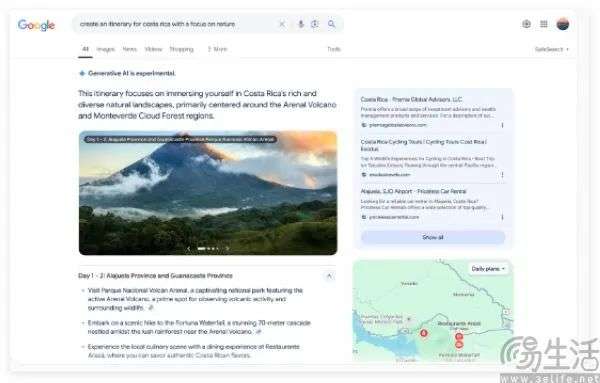
随着DeepSeek R1、OpenAI GTP-4o、Antropic Claude3.7、xAI Grok3纷至沓来,AI大模型已然变成巨头的游戏,“百模大战”也成为了过去式。到了2025年,让用户先把AI用起来,也已经成为了一众厂商的共识。

这两年,大家的目光几乎被“大模型”三个字牢牢吸住了,谁超越了谁、榜单排名第一,少有人关注模型之外的东西。
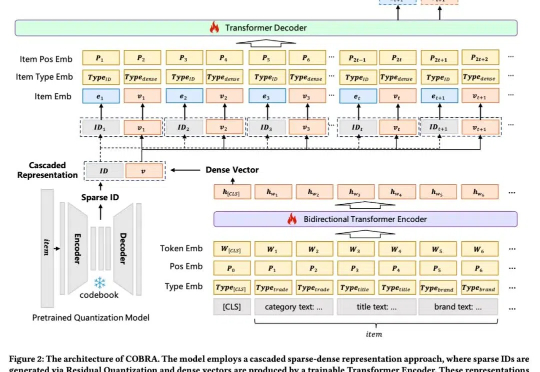
2025 年,生成式 AI 的发展速度正在加快。
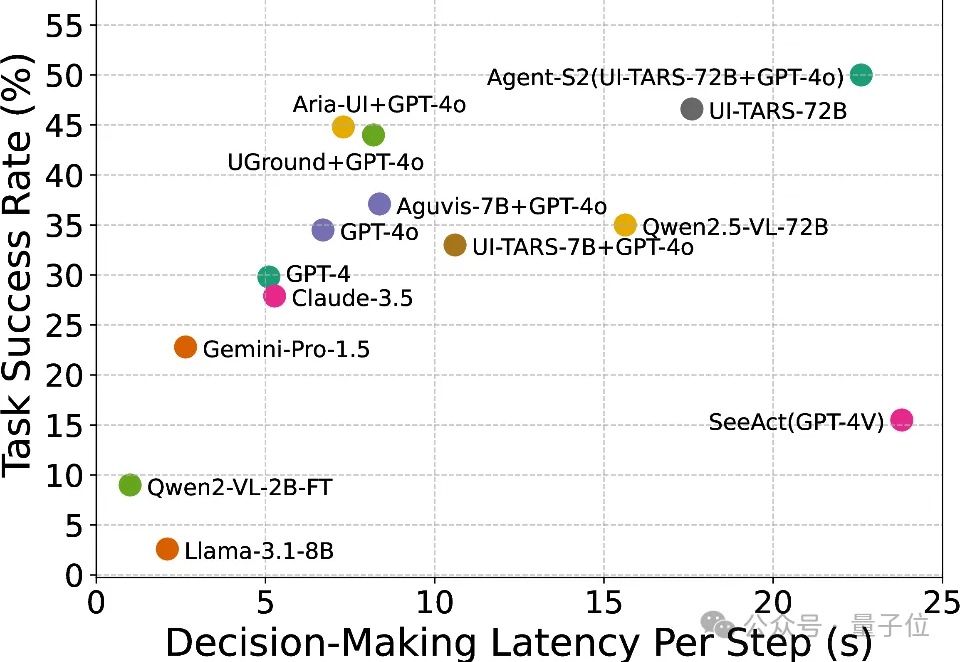
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。

大模型写代码早就是基操了,但让它写算法竞赛题或企业级系统代码,就像让只会煮泡面的人去做满汉全席 —— 生成的代码要么是 “铁板一块” 毫无章法,要么是 “一锅乱炖” 难以维护。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。

刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。
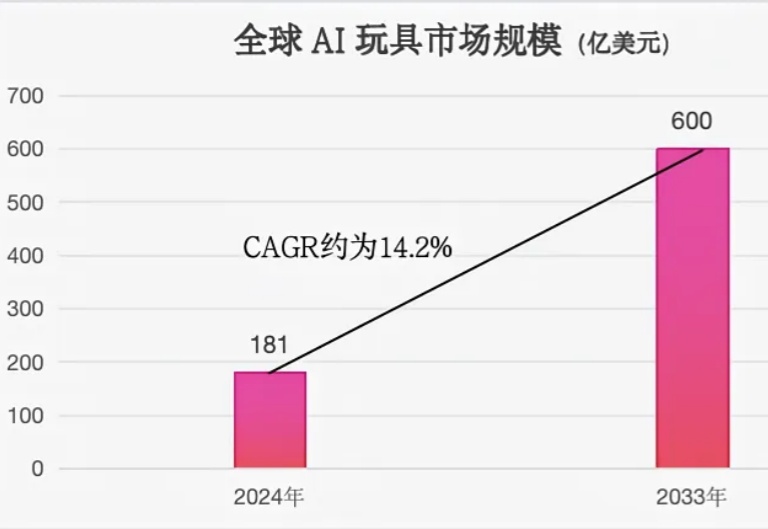
2025 年,DeepSeek 爆火带动传统产品的智能化升级,如传统玩具向 AI 玩具转型。央视新闻调查数据显示,2025 年 1 月,国内某电商平台面向 3-6 岁儿童的 AI 早教玩具销量环比增长 6 倍。咨询公司 IMARC 的预测数据显示,2024 年全球 AI 玩具市场规模已达 181 亿美元,预计到 2033 年将增长至 600 亿美元。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。