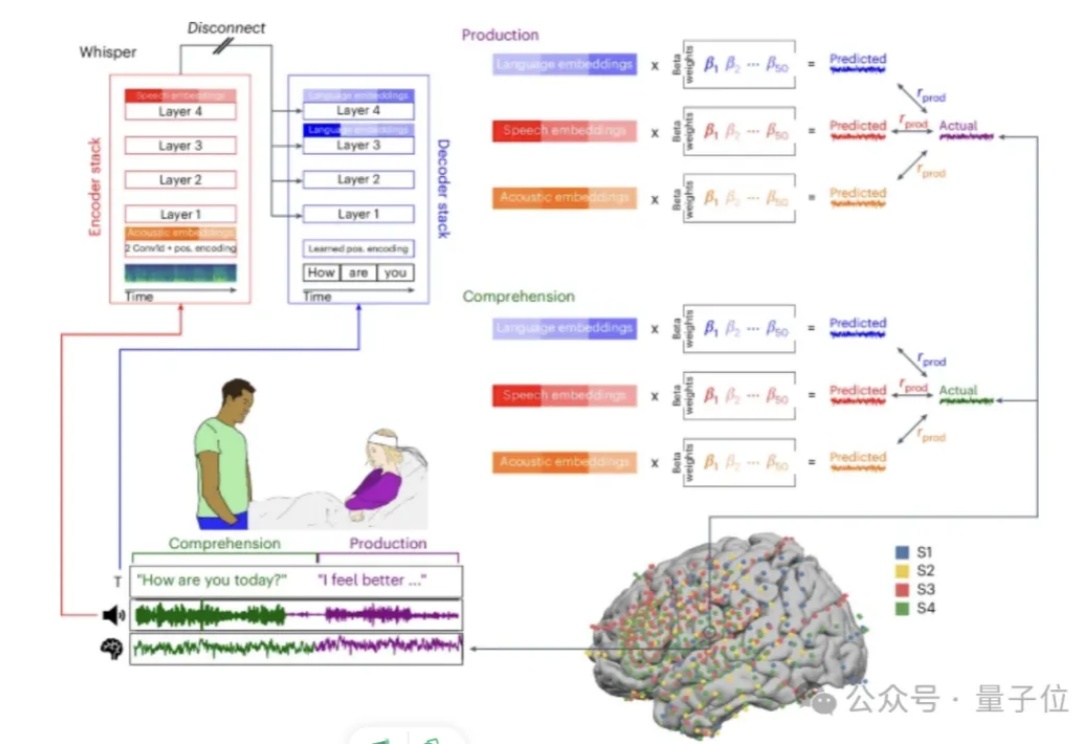
谷歌对齐大模型与人脑信号!语言理解生成机制高度一致,成果登Nature子刊
谷歌对齐大模型与人脑信号!语言理解生成机制高度一致,成果登Nature子刊谷歌最新发现,大模型竟意外对应人脑语言处理机制?!
来自主题: AI技术研报
9997 点击 2025-03-24 10:56
 搜索
搜索
谷歌最新发现,大模型竟意外对应人脑语言处理机制?!
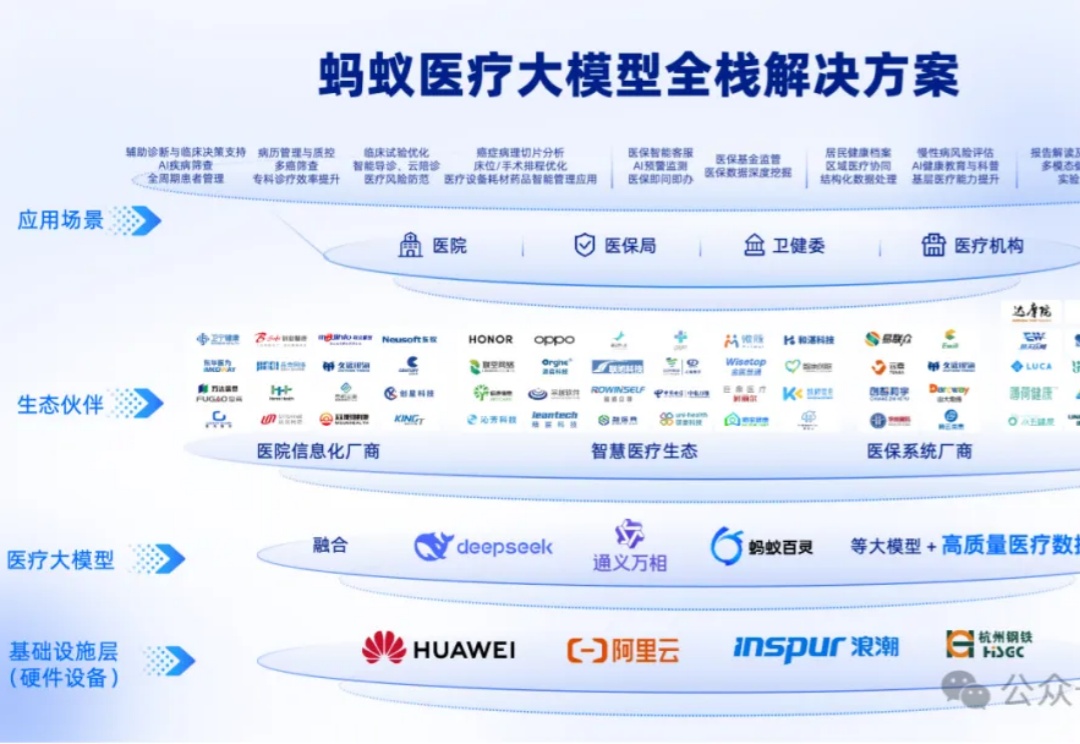
DeepSeek之后,大模型下半场的走向如何?

当前,传统生物制造方法在知识整合、数据处理和实验设计方面面临诸多挑战,限制了其在工业化应用中的效率和可扩展性。
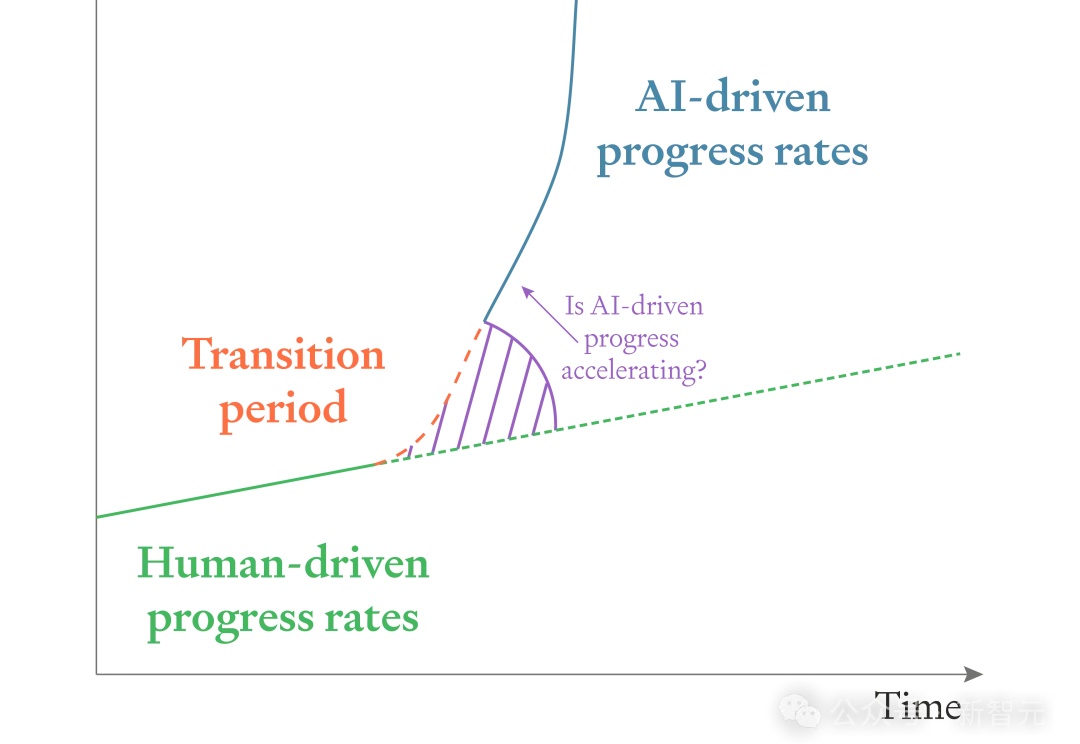
硅谷投资人Tom Davidson的硬核长文预测,给出了惊人结论:全栈的AI大爆炸,或将率先发生在中国!而当芯片规模扩大1万倍时,AI将逼近物理极限。

国产厨电龙头老板电器出品的全球首个烹饪大模型「食神」升级,不光接入了DeepSeek,还拓展了多模态。像推荐菜谱、指导烹饪已经是常规操作。在此基础上,它还能一眼看出你的健康状况——通过面部识别、分析体检报告,生成长期的健康膳食计划。
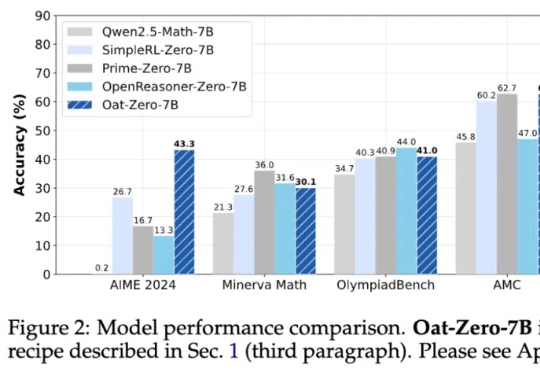
其实大模型在DeepSeek-V3时期就已经「顿悟」了?

Grok连夜上线图片编辑功能,继Gemini引爆图片编辑热潮后,动动嘴就能实现「证件照换西装」、「黑发变金发」等专业级P图效果。随着AI巨头内卷加剧,很多工作可能会经历「从复杂操作到简单交互」的范式转移,大模型内卷,受伤可能是传统软件。

3月20日,国家儿童医学中心、首都医科大学附属北京儿童医院(以下简称“北京儿童医院”)联合北京百川智能科技有限公司(以下简称“百川智能”)、小儿方健康科技(北京)有限公司(以下简称“小儿方”)正式发布国内首个儿科大模型——“福棠·百川”儿科大模型,同时发布两款人工智能应用即AI儿科医生基层版和专家版。

据“新浪科技”近日报道,和月之暗面齐名、估值高达200亿元的“大模型六小虎之一”百川智能,其联合创始人焦可已离职,另一位联合创始人陈炜鹏也正在办理离职手续,两人未来或将在AI领域创业,目前正在寻求融资。

到目前为止,百川智能是所有大模型企业中,唯一对外高调表达要all in 医疗的。这种明确的表态,让百川智能备受关注的同时,也背负了很多的质疑。百川智能和王小川近日再次成为媒体关注的焦点,主要关注点是百川智能的组织调整,以及大部分人对于百川为什么收缩金融业务而all in医疗表示出极大的不解。