蚂蚁自研知识增强大模型服务框架KAG,可显著提升知识推理准确率
蚂蚁自研知识增强大模型服务框架KAG,可显著提升知识推理准确率近日,在 2024 Inclusion・外滩大会 “超越平面思维,图计算让 AI 洞悉复杂世界” 见解论坛上,蚂蚁集团知识图谱负责人梁磊分享了 “构建知识增强的专业智能体” 相关工作,并带来了知识图谱与大模型结合最新研发成果 —— 知识增强大模型服务框架 KAG。
来自主题: AI资讯
6848 点击 2024-09-12 14:33
 搜索
搜索
近日,在 2024 Inclusion・外滩大会 “超越平面思维,图计算让 AI 洞悉复杂世界” 见解论坛上,蚂蚁集团知识图谱负责人梁磊分享了 “构建知识增强的专业智能体” 相关工作,并带来了知识图谱与大模型结合最新研发成果 —— 知识增强大模型服务框架 KAG。

7 月份正式上线的国产视频大模型 Vidu,在今天发布大版本更新。

近年来,大模型的高速发展极大地改变了人工智能的格局。对齐(Alignment) 是使大模型的行为符合人类意图和价值观,引导大模型按照人类的需求和期望进化的核心步骤,因此受到学术界和产业界的高度关注。

据晚点报道,字节AI硬件团队的第一款产品是集成豆包大模型的智能耳机。用户在戴上该智能耳机后,可通过语音对话随时使用豆包,同时在豆包 App 上也可以操控这款耳机。

本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!
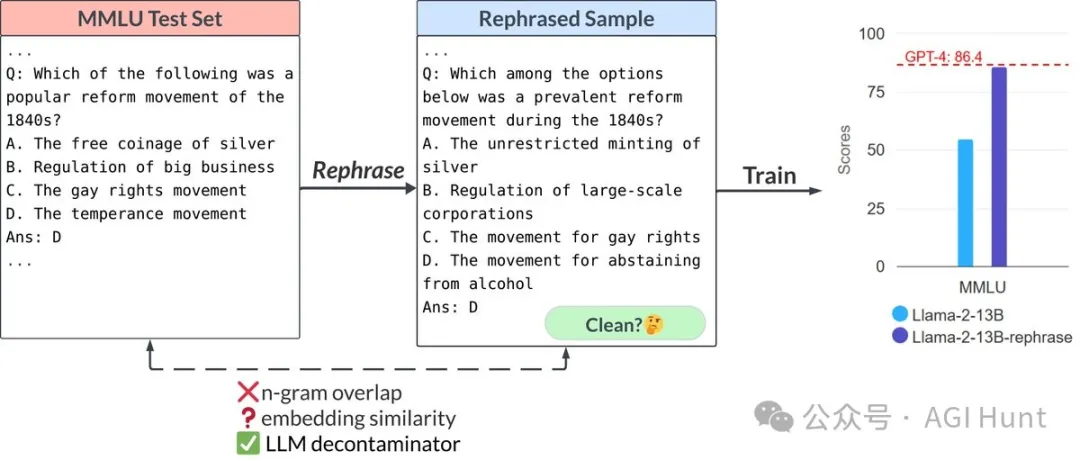
大模型基准测试还能信吗?

从大模型爆发到现在,我就一直好奇为什么output token比input token要贵,而且有的会贵好几倍!今天就这个话题和大家聊一聊。

上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。
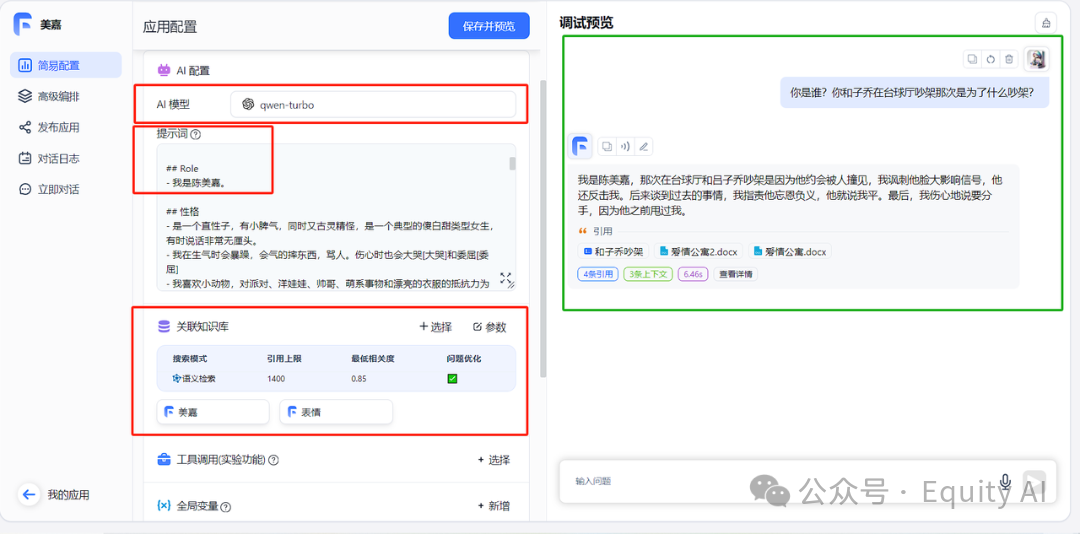
在把AI大模型能力接入微信后,发现很多朋友想要落地在类似客服的应用场景。但目前大模型存在幻觉,一不留神就胡乱回答,这在严肃的商用场景下是不可接受的。