
出息了:6 成中国AI上市公司营收实现增长,“大模型”和“出海”这两个杀手锏真好使
出息了:6 成中国AI上市公司营收实现增长,“大模型”和“出海”这两个杀手锏真好使AI半年考,人工智能上市公司的业绩答卷如何 截至 8 月底,据 IT 桔子不完全统计,至少有 34 家有人工智能相关业务的中国上市公司都已经公布了 2024 半年报。
来自主题: AI资讯
6944 点击 2024-09-06 10:08
 搜索
搜索
AI半年考,人工智能上市公司的业绩答卷如何 截至 8 月底,据 IT 桔子不完全统计,至少有 34 家有人工智能相关业务的中国上市公司都已经公布了 2024 半年报。
一觉醒来,阿里Qwen的GitHub网页404了?!
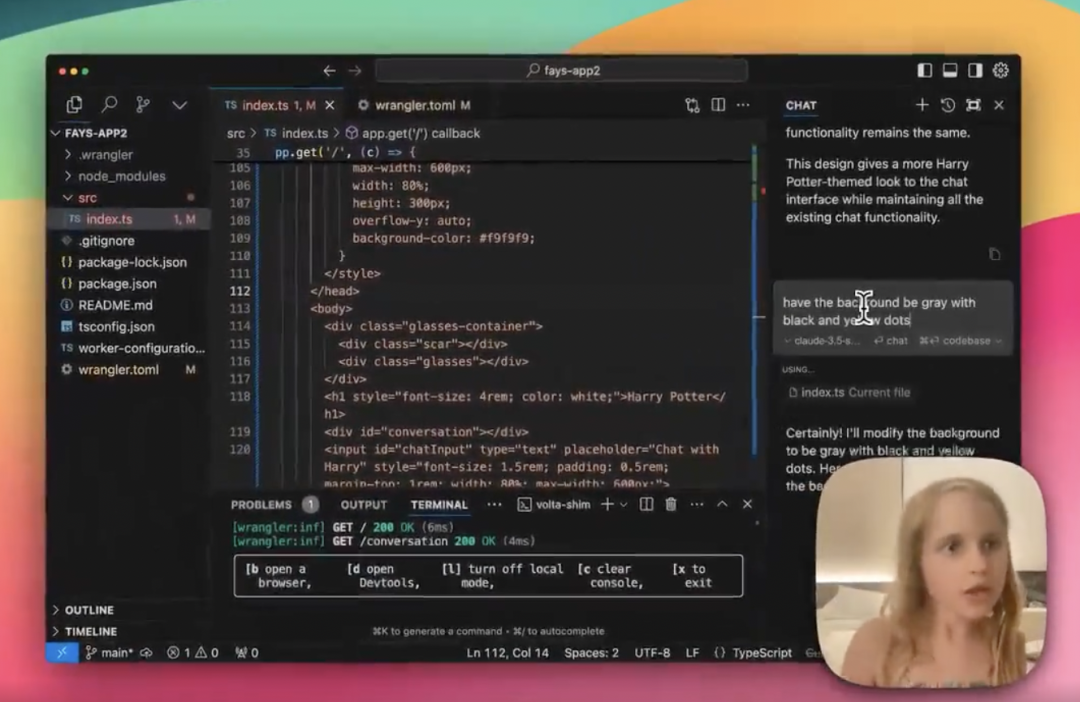
大模型应用落地,正在快步进入全民“淘金”时代——
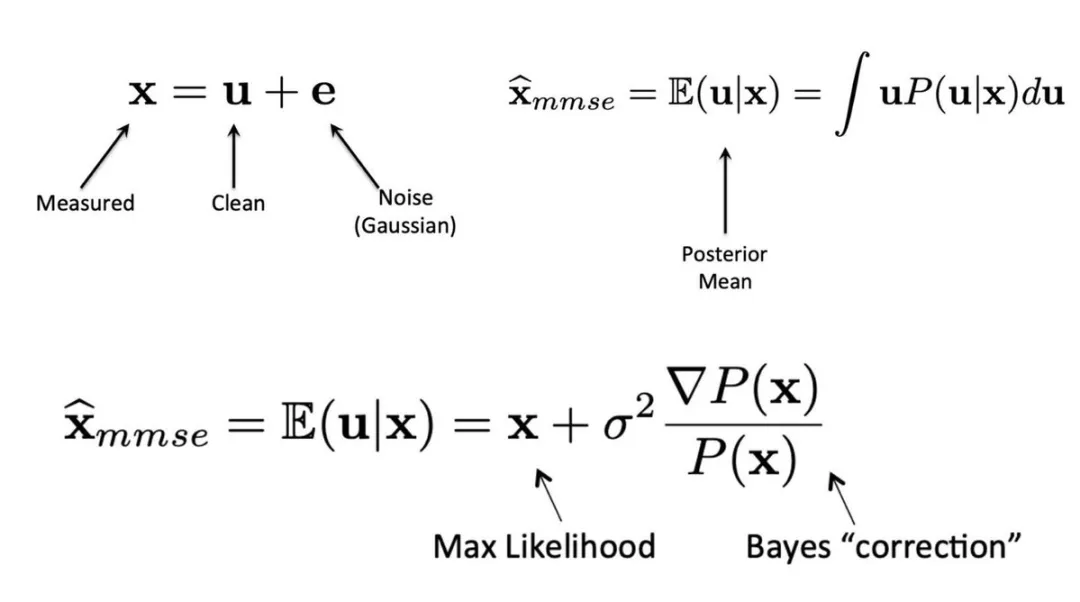
今天的内容有点烧脑但绝对干货满满!

训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

在未来,太空 AI 算力或许要比地球上功率最大的还要大。

这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。

在21世纪的科技洪流中,人工智能(AI)正以前所未有的速度重塑着世界的每一个角落,从医疗、教育到金融、制造,无一不感受到其强大的影响力。然而,当我们将目光投向看似与AI技术相去甚远的能源领域,尤其是石油行业时,一场由AI驱动的变革似乎正悄然酝酿。

PPIO推出新AI产品,助力分布式云计算及AIGC应用。

AI有情商吗?