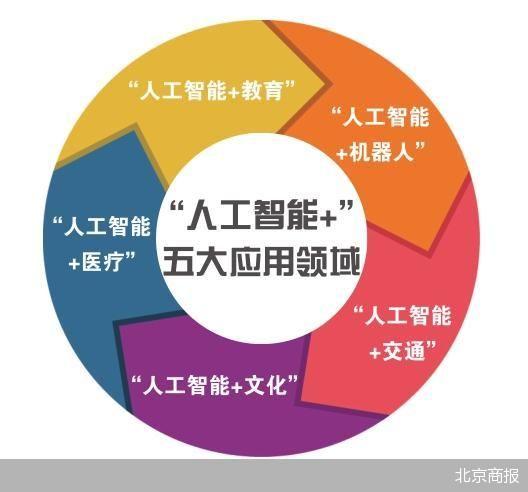
“人工智能+”计划发布北京大模型应用落地提速
“人工智能+”计划发布北京大模型应用落地提速7月26日,《北京市推动“人工智能+”行动计划(2024—2025年)》(以下简称《行动计划》)正式对外发布。
来自主题: AI资讯
8182 点击 2024-08-02 15:22
 搜索
搜索
7月26日,《北京市推动“人工智能+”行动计划(2024—2025年)》(以下简称《行动计划》)正式对外发布。
这么强的模型,谷歌给大家免费试用。

单卡搞定Llama 3.1(405B),最新大模型压缩工具来了!

现在,大模型可以做私人导游,为你规划Citywalk路线了——

人工智能毫无疑问是当今一项重要议题,通过大模型、垂类应用、智能体等多种方式推动着数字经济的发展。
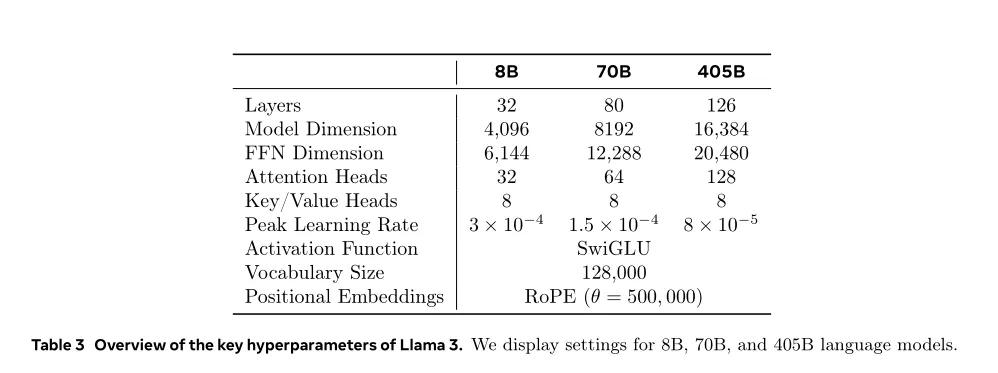
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

数值天气预报是现在,AI 天气预报会是未来吗?

Transformer大模型尺寸变化,正在重走CNN的老路!
是时候用CPU通用服务器跑千亿参数大模型了!

有 AI 在的科技圈,似乎没有中场休息。除了大模型发布不断,各家科技大厂也在寻找着第一个「杀手级」AI 应用的落脚之地。