
大模型明星独角兽CEO专访:AI毁灭人类不现实,爆料谷歌AI研发细节
大模型明星独角兽CEO专访:AI毁灭人类不现实,爆料谷歌AI研发细节Cohere CEO称要把大模型技术推向全世界,公司将以”非炒作的“策略拉取更多投资。
来自主题: AI资讯
6043 点击 2024-07-10 19:19
 搜索
搜索
Cohere CEO称要把大模型技术推向全世界,公司将以”非炒作的“策略拉取更多投资。

不大可能重现iPhone奇迹。

Kimi探索出了一条新路。

大幅节省算力资源,又又又有新解了!!
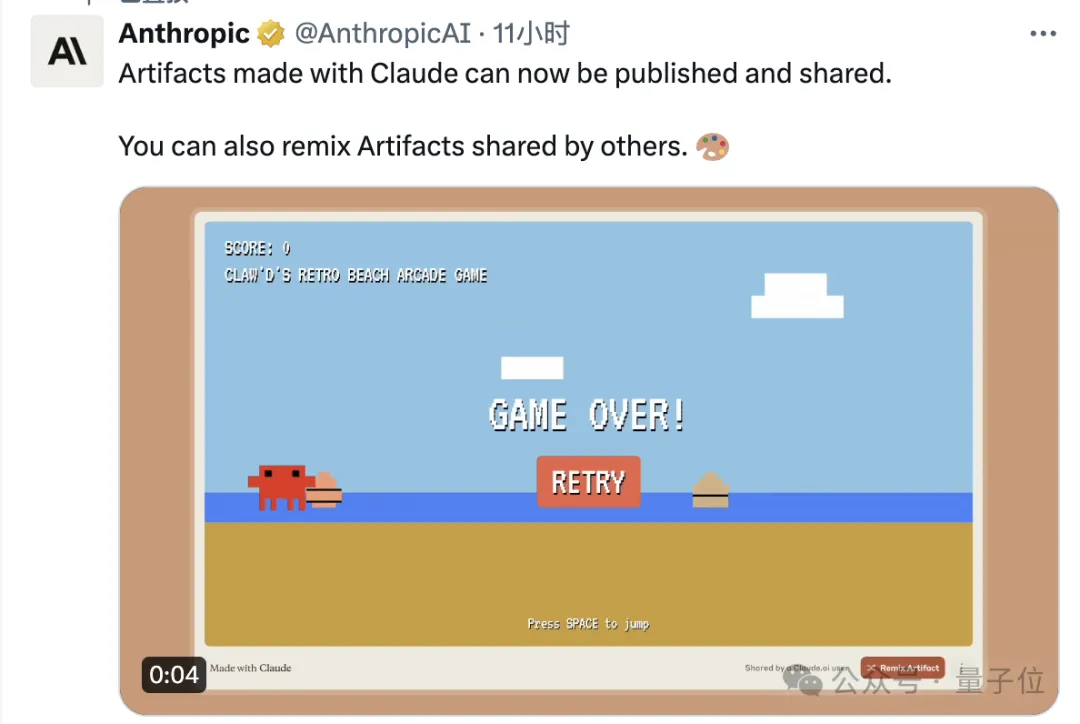
Claude 3.5上新的“工坊模式”(Artifacts)再次更新,写完的网页应用支持一键分享了!

AI一天,人间一年。
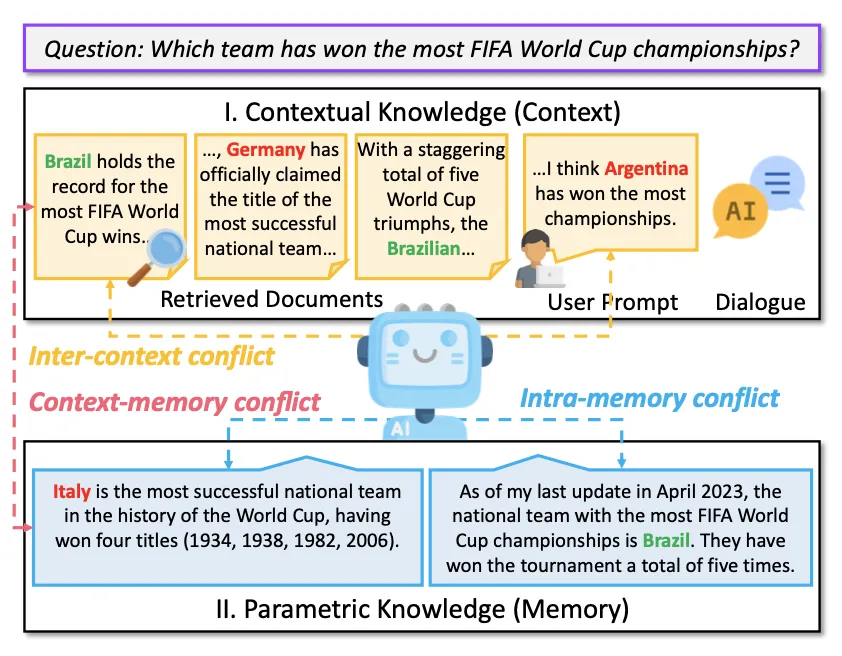
随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
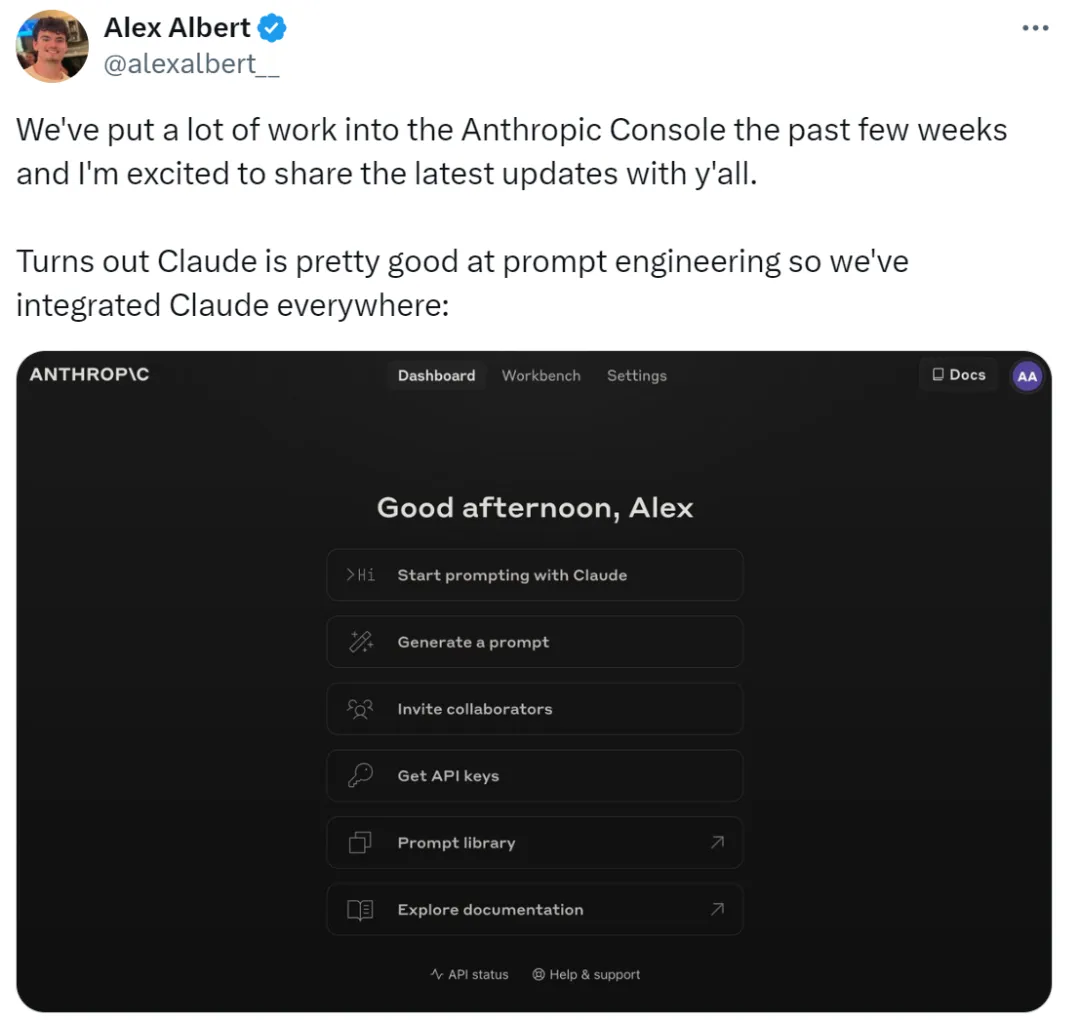
不会写 prompt 的看过来。

ControlNet作者张吕敏(Lvmin Zhang)又又又发新作了!

这几年,人们都在谈论大模型。特别是在 Scaling Law 的指导下,人们寄希望于将更大规模的数据用于训练,以无限提升模型的智能水平。在中国,「数据」作为一种与土地、劳动力、资本、技术并列的生产要素,价值越来越被重视。