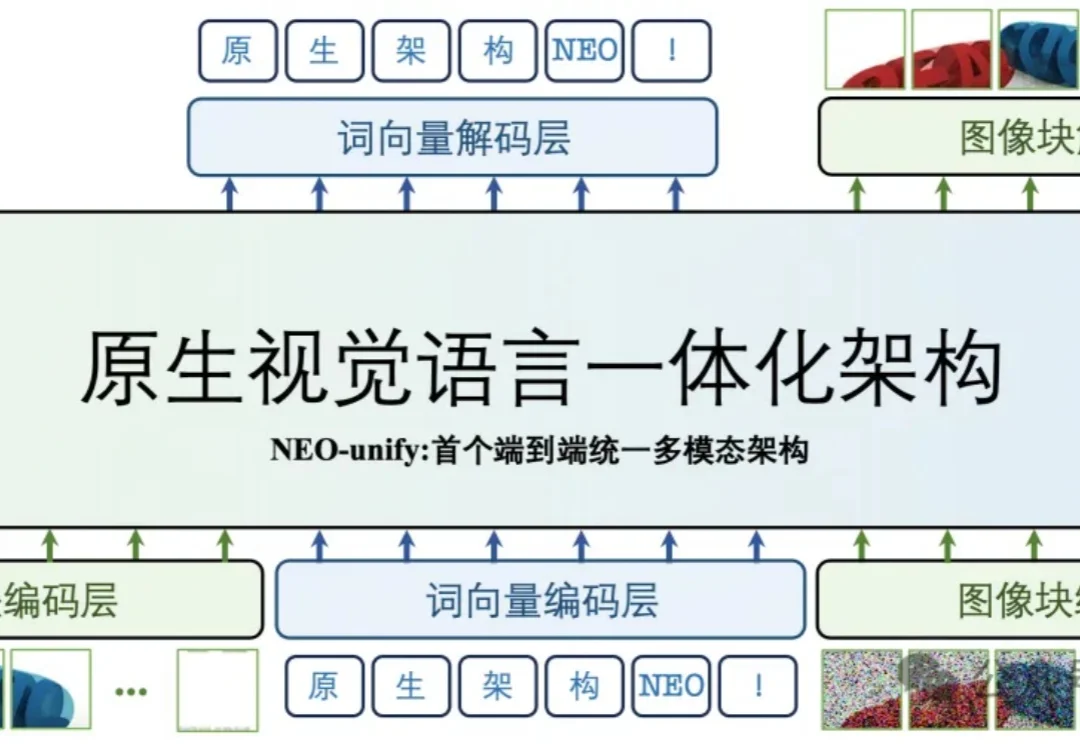
彻底告别VE与VAE!商汤硬核重构多模态:砍掉所有中间编码器
彻底告别VE与VAE!商汤硬核重构多模态:砍掉所有中间编码器多模态大模型的研发范式,正在被彻底重构。
来自主题: AI技术研报
6327 点击 2026-03-09 09:51
 搜索
搜索
多模态大模型的研发范式,正在被彻底重构。

从OpenAI出走的前首席研究官Bob McGrew,没有去卷更聪明的大模型,而是杀进制造业工厂,要用AI为流水线机器装上「眼睛+大脑」。
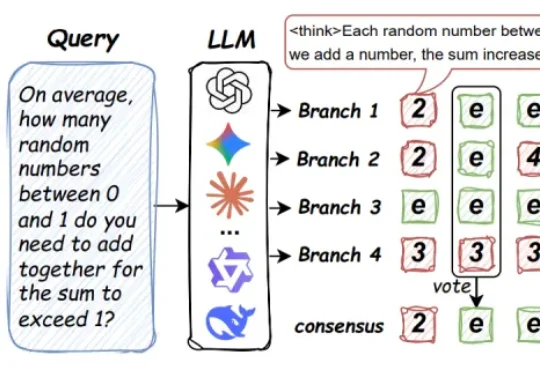
来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。

现在,一篇来自 CISPA 亥姆霍兹信息安全中心的最新论文《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》为我们揭开了一点谜底:那些你花真金白银购买的「第三方 API」,有可能偷偷把前沿大模型换成了廉价的替代品。

今日,小米正式启动类OpenClaw的移动端系统级智能体Xiaomi miclaw小范围封闭测试。最近一段时间,开源项目OpenClaw在开发者社区迅速走红,它展示了大模型调用工具、操作软件完成任务的惊艳能力。在开发者圈里,用OpenClaw搭建智能体助手也被戏称为“养龙虾”。而小米这次发布的Xiaomi miclaw,则把类似思路带进了手机系统。

你是不是也在思考这个问题: AI大模型之间的真实差距,真的像各种榜单上表现得那样直观吗?
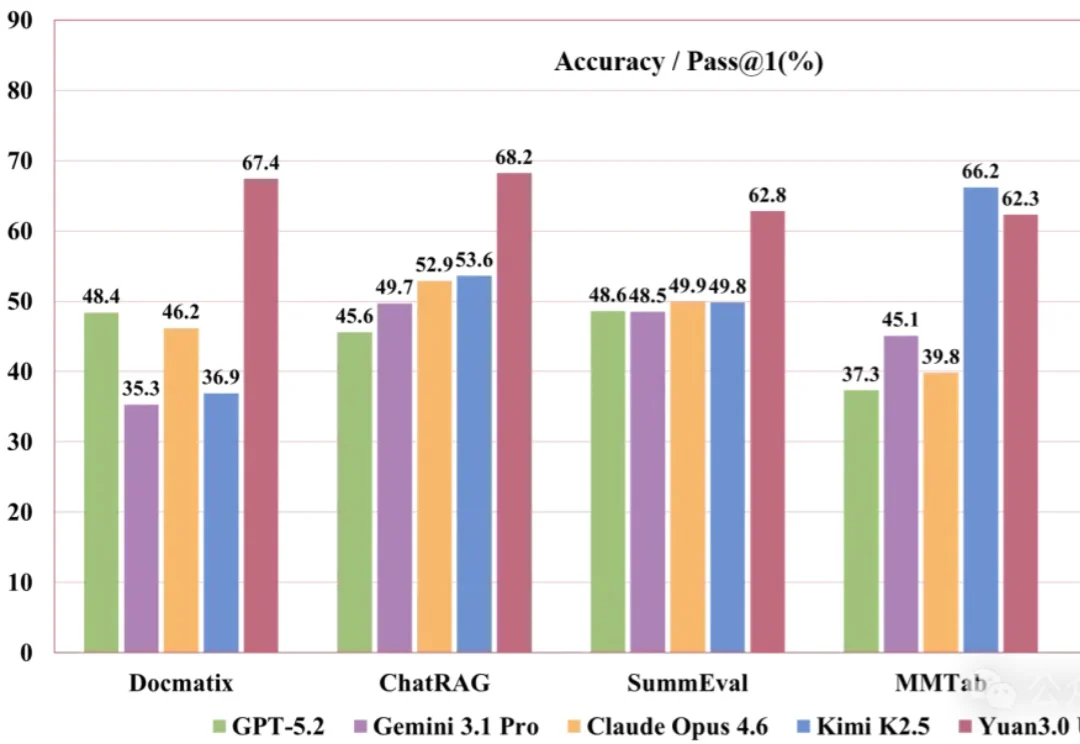
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
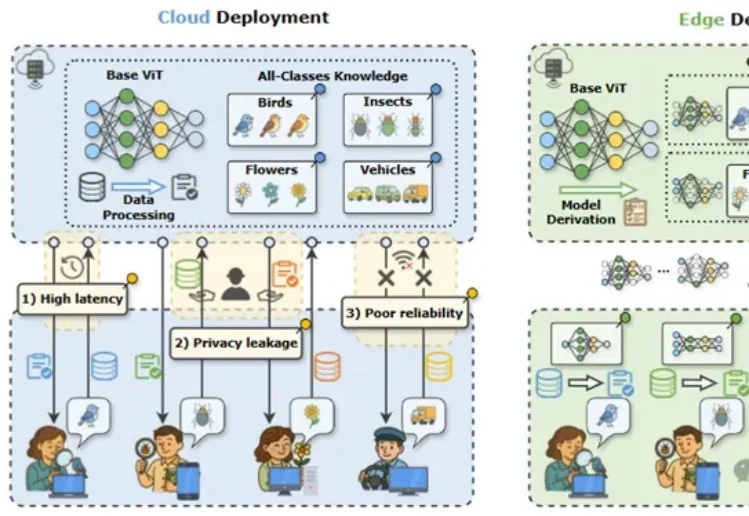
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。

北京时间3月4日下午约13:00,通义实验室紧急召开了All Hands会议,阿里集团CEO吴泳铭向千问员工坦诚表示。12个小时前(北京时间3月4日凌晨0点11分),阿里千问大模型技术负责人林俊旸在X上突然宣布离职——林俊旸是阿里AI开源模型的核心推手,也是阿里最年轻的P10之一——行业一片哗然之时,Qwen的部分成员也无法接受团队灵魂人物的突然出走。
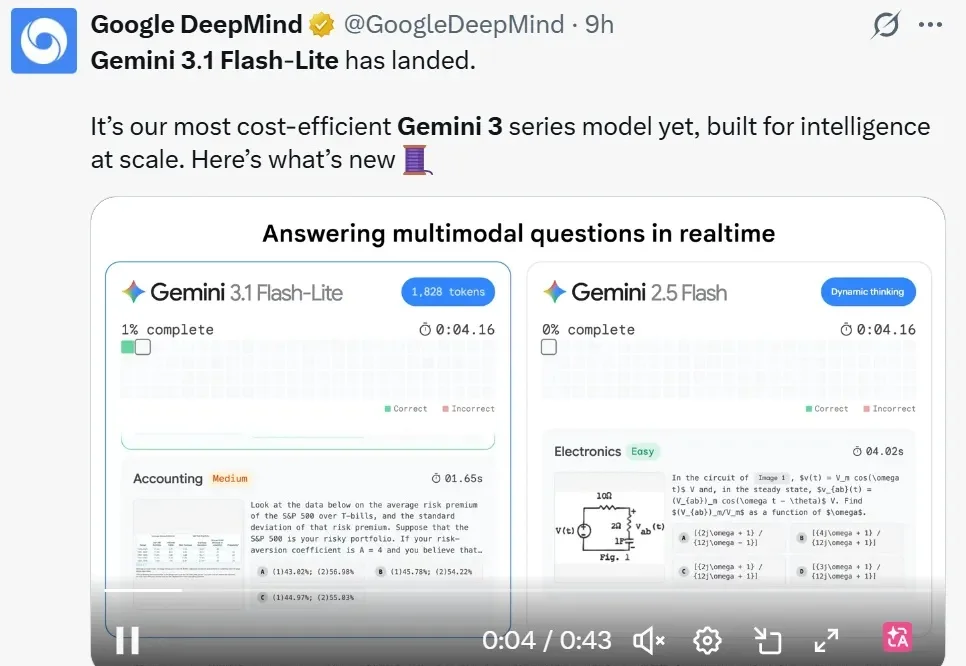
深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。