
超20位“大厂高管”,跑步入场大模型
超20位“大厂高管”,跑步入场大模型AI应用和垂直场景,成为新共识。
来自主题: AI资讯
10752 点击 2024-06-29 17:15
 搜索
搜索
AI应用和垂直场景,成为新共识。

国产大模型迎来“泼天富贵”?

被 OpenAI 的 Superalignment 研究团队解雇的 Leopold Aschenbrenner 最近发表了一篇关于人工智能的长篇大作,里面宣称根据他的曲线预测,人类到2027年就能实现通用人工智能。本文是对这一预测的讨论。

AI时代,我们需要怎样的大模型?

当数据拥有者不想给、AI厂商偏偏又很想要的情况下,结果就这样了。

OpenAI在6月25日凌晨宣布,将从7月9日起,将阻止来自不支持其服务的国家和地区的API流量,而中国也在禁用名单之列。

本文提出了解决一般性编辑任务的统一框架!近期,复旦大学 FVL 实验室和南洋理工大学的研究人员对于多模态引导的基于文生图大模型的图像编辑算法进行了总结和回顾。综述涵盖 300 多篇相关研究,调研的最新模型截止至今年 6 月!

性能翻倍的Gemma 2, 让同量级的Llama3怎么玩?
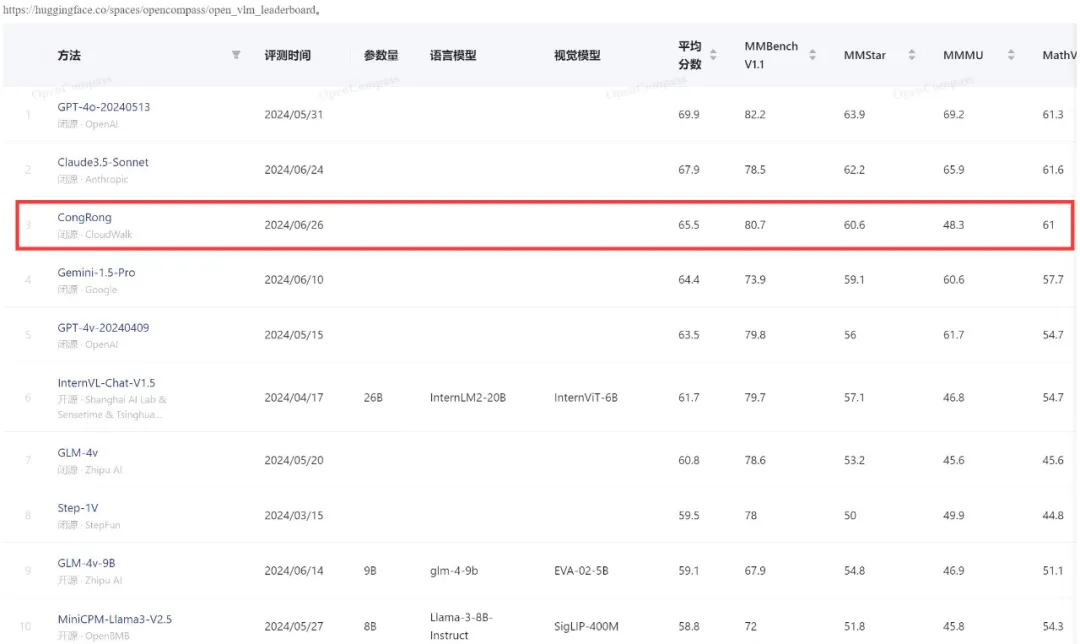
近日,云从科技从容大模型在综合评测权威平台 OpenCompass 的多模态评测领域中取得重大进展。 最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的 Gemini-1.5-Pro 和 GPT-4v,仅次于 GPT-4o(69.9)和 Claude3.5-Sonnet(67.9)。

想要达成通用人工智能 AGI 的终极目标,首先要达成的是模型要能完成人类所能轻松做到的任务。为了做到这一点,大模型开发的关键指导之一便是如何让机器像人类一样思考和推理。诸如注意力机制和思维链(Chain-of-Thought)等技术正是由此产生的灵感。