
中国科技「亮剑」!十年来,AI领域项目首次问鼎国家科技奖一等奖
中国科技「亮剑」!十年来,AI领域项目首次问鼎国家科技奖一等奖2023年度国家科学技术大奖公布了!今年的评选堪称史上最严、最难,竞争最激烈的一届。这当中,大厂中唯有科大讯飞摘得了国家科学技术进步奖一等奖,成为过去十年AI领域获得的首个国奖一等奖。
来自主题: AI资讯
11164 点击 2024-06-26 10:44
 搜索
搜索
2023年度国家科学技术大奖公布了!今年的评选堪称史上最严、最难,竞争最激烈的一届。这当中,大厂中唯有科大讯飞摘得了国家科学技术进步奖一等奖,成为过去十年AI领域获得的首个国奖一等奖。
没想到,刚刚上线了图生视频和视频续写功能的可灵AI,竟已在全世界互联网上引爆了视频创作的热潮!

作为创新工场联合创始人,汪华见证了移动互联网的全过程,以及当下 AI 的兴起。

在过去的一年多时间里,“大模型” 一直是中国科技领域内最热门的赛道。

今天凌晨,OpenAI 突然宣布终止对中国提供 API 服务,进一步收紧国内开发者访问 GPT 等高水平大模型。国内开发者真是太难了。

阶跃星辰提供支持,这次敞开玩

还有12款大模型全军覆没……
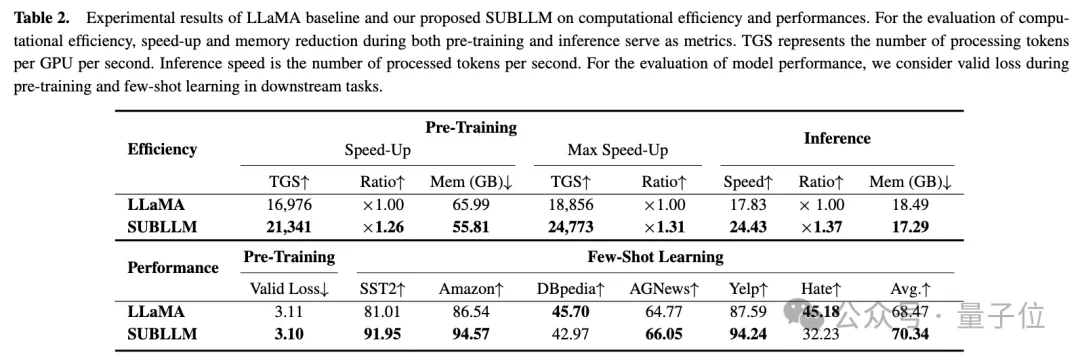
大模型推理速度提升50%以上,还能保证少样本学习性能!

今年 2 月,Sora 吸引了人们对视频生成赛道的关注。而这一赛道的头部创业公司爱诗科技,也开始进入人们的视野。

说起半导体行业面临的难题,人们第一时间想到的是什么?是光刻机?是5nm?是一块方方正正的芯片,我们造不出来?