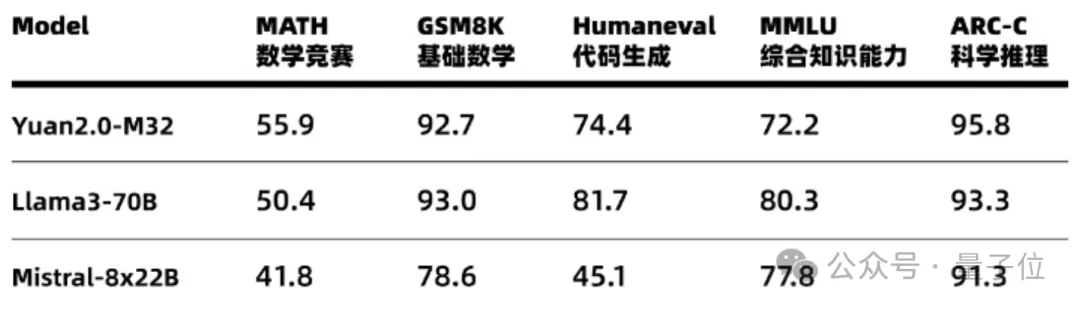
32专家MoE大模型免费商用!性能全面对标Llama3,单token推理消耗仅5.28%
32专家MoE大模型免费商用!性能全面对标Llama3,单token推理消耗仅5.28%每个token只需要5.28%的算力,精度就能全面对标Llama 3。
来自主题: AI技术研报
11660 点击 2024-05-30 15:51
 搜索
搜索
每个token只需要5.28%的算力,精度就能全面对标Llama 3。

挤爆了,简直要被大模型公司们给挤爆了。

在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。

一直以来,UC伯克利团队的LMSYS大模型排行榜,深受AI圈欢迎。如今,最有实力的全新大模型排行榜SEAL诞生,得到AI大佬的转发。它最大的特点是在私有数据上,由专家严格评估,并随时间不断更新数据集和模型。
搜集了328×204条数据,只为让机器人把开门这一件事做到极致。
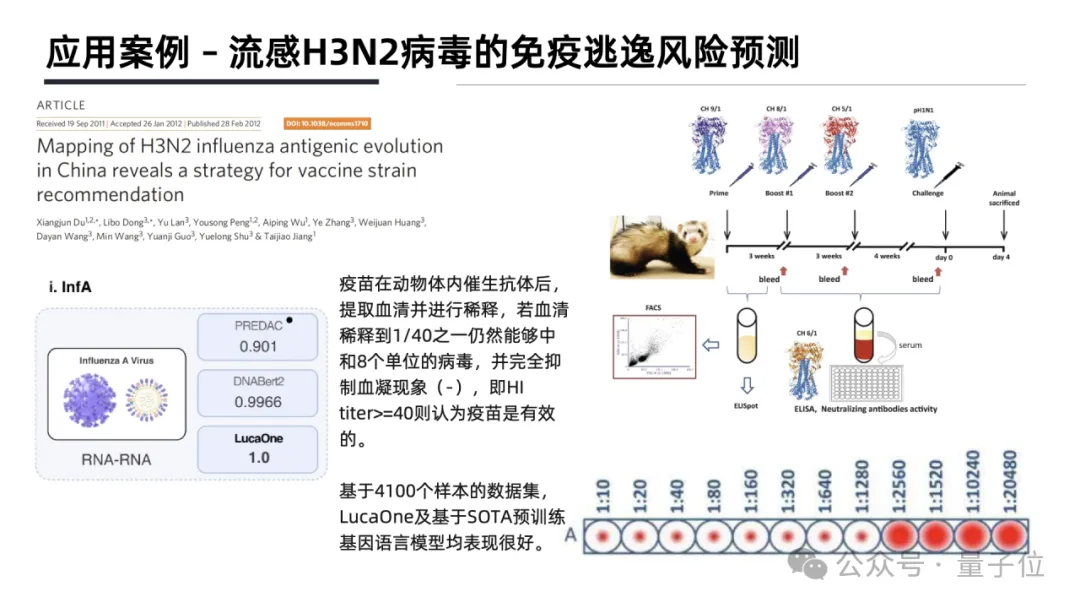
把169861个生物物种数据装进大模型,大模型竟get到了生物中心法则的奥秘——
医学影像,越来越需要AI的帮助了。

在大模型实际部署落地的过程中,如何赋予大模型持续学习的能力是一个至关重要的挑战。这使其能够动态适应新的任务并不断获得新的知识。大模型的持续学习主要面临两个重大挑战,分别是灾难性遗忘和知识迁移。灾难性遗忘是指模型在学习新任务时,会忘记其已掌握的旧任务。知识迁移则涉及到如何在学习新任务时有效地应用旧任务的知识来提升新任务学习的效果。
OpenAI 开始训练下一个前沿模型了。在联合创始人、首席科学家 Ilya Sutskever 官宣离职、超级对齐团队被解散之后,OpenAI 研究的安全性一直备受质疑。
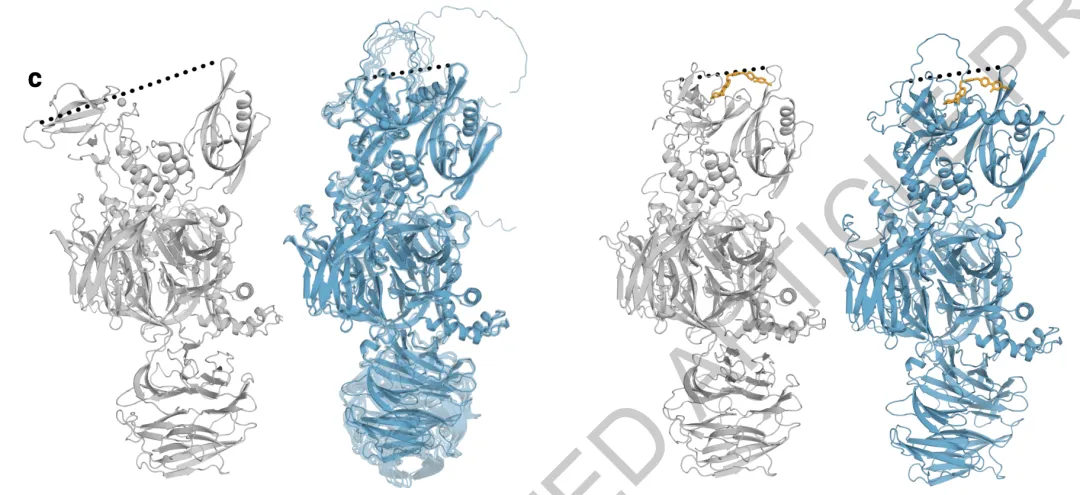
世界是变化的,分子是运动的,从预测静态单一结构走向动态构象分布是揭示蛋白质等生物分子功能的重要一步。探索蛋白质的构象分布,能帮助理解蛋白质与其他分子相互作用的生物过程;识别蛋白质表面下的潜在药物位点,描绘各个亚稳态之间的过渡路径,有助于研究人员设计出具有更强特异性和效力的目标抑制剂和治疗药物。但传统的分子动力学模拟方法昂贵且耗时,难以跨越长的时间尺度,从而观察到重要的生物过程。