
稀疏算力暴涨591%,Meta推出5nm AI训练芯片,自研AI芯片盛世来了
稀疏算力暴涨591%,Meta推出5nm AI训练芯片,自研AI芯片盛世来了智东西4月11日报道,美国AI三巨头不仅在大模型赛道争奇斗艳,还纷纷卷起自研AI芯片。
来自主题: AI资讯
8653 点击 2024-04-11 21:59
 搜索
搜索
智东西4月11日报道,美国AI三巨头不仅在大模型赛道争奇斗艳,还纷纷卷起自研AI芯片。

近日,来自佐治亚大学、新泽西理工学院、弗吉尼亚大学、维克森林大学、和腾讯 AI Lab 的研究者联合发布了解释性技术在大语言模型(LLM)上的可用性综述,提出了 「Usable XAI」 的概念,并探讨了 10 种在大模型时代提高 XAI 实际应用价值的策略。
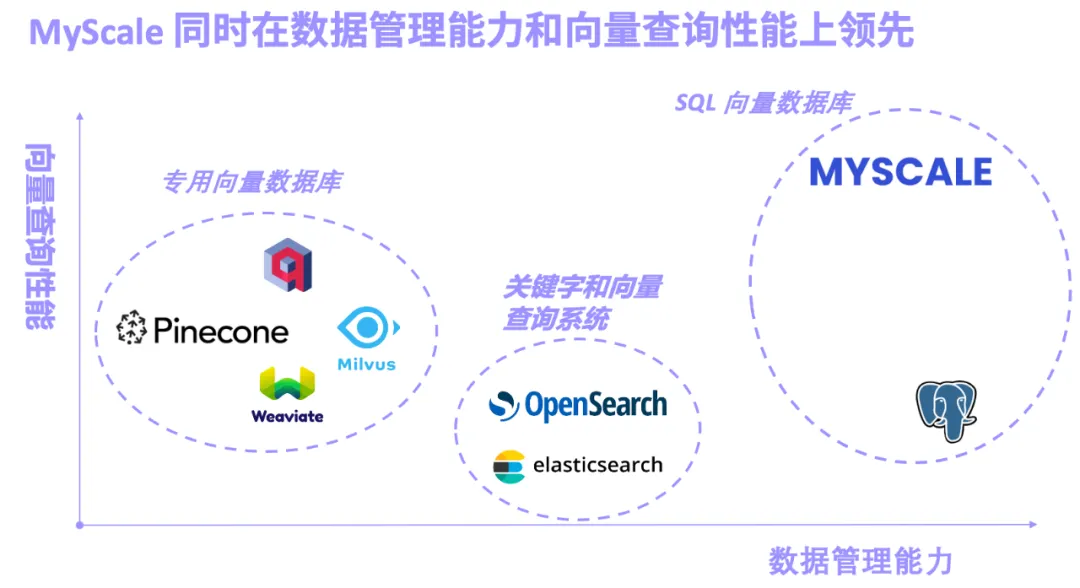
大模型和 AI 数据库双剑合璧,成为大模型降本增效,大数据真正智能的制胜法宝

大语言模型潜力被激发—— 无需训练大语言模型就能实现高精度时序预测,超越一切传统时序模型。

谁能想到,只是让大模型讲笑话,论文竟入选了顶会CVPR!

AIGC新应用,到底将重塑怎样的一个新世界? 现在,只需一天的时间,你就能感受到它们正在引领的科技新范式。

一句话Siri就能帮忙打开美团外卖下订单的日子看来不远啦!
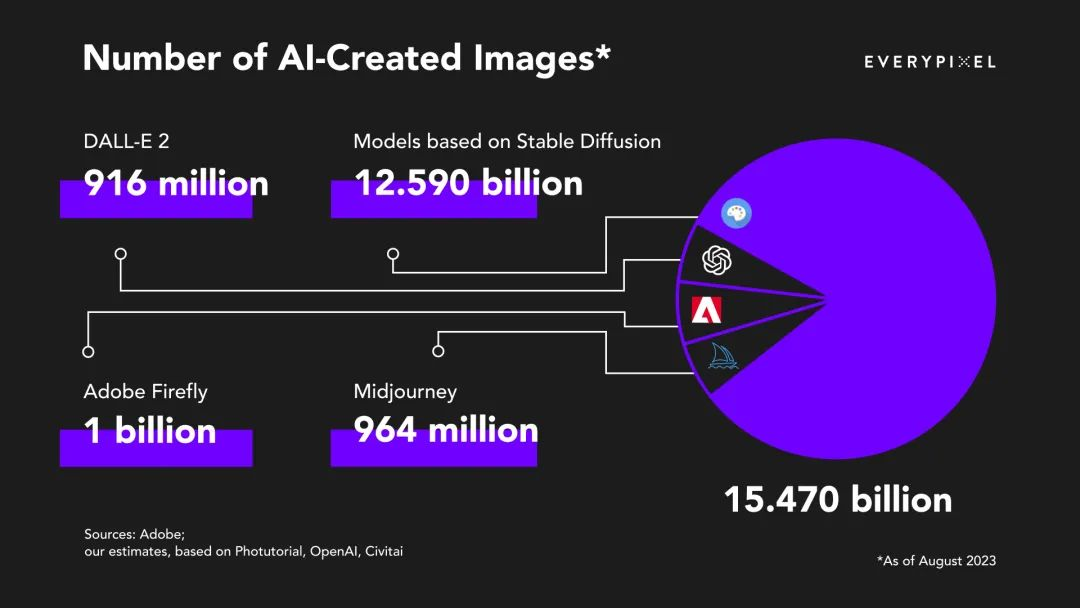
国内大模型还在如火如荼,但国外的一些生成式AI先锋们,正在上演一场生死出逃大戏。
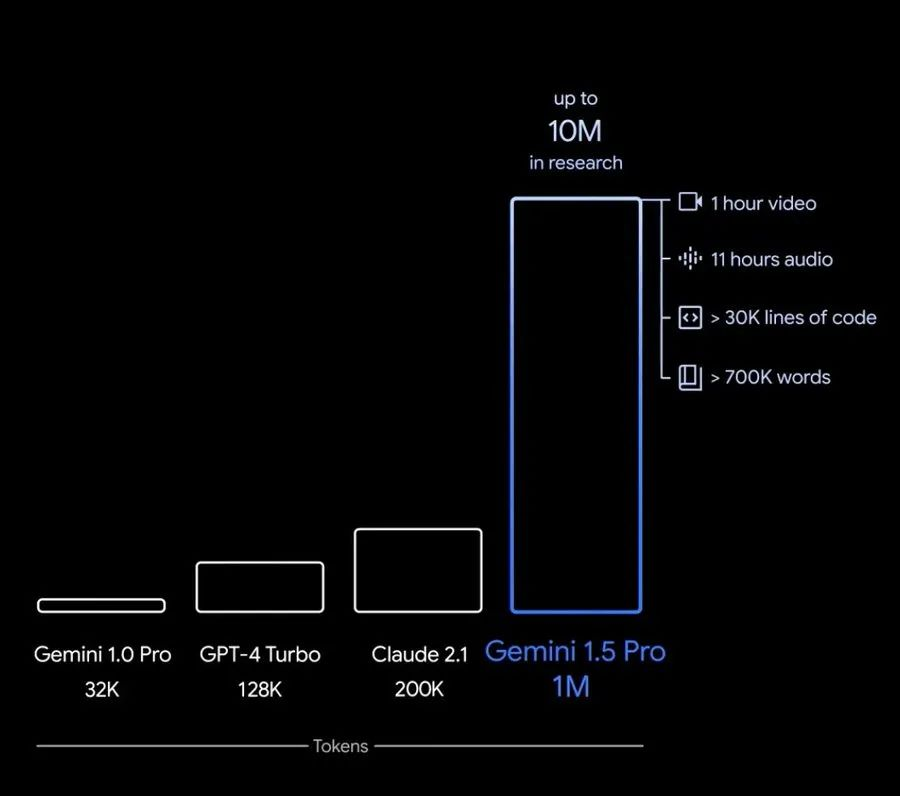
不得不感叹,国外AI大模型的迭代速度,就像是坐火箭????。

技术阿甘在不停奔跑。