
黄学东分享:Zoom AI如何正确地「碾压GPT-4」
黄学东分享:Zoom AI如何正确地「碾压GPT-4」【新智元导读】Zoom AI通过独创的「联邦AI」的技术路线,联合多个大模型,在特定任务上超越GPT-4,体现出了多个大模型互帮互助的强大能力,而且成本也能控制在GPT-4一半的水品。
来自主题: AI技术研报
9404 点击 2024-04-02 16:05
 搜索
搜索
【新智元导读】Zoom AI通过独创的「联邦AI」的技术路线,联合多个大模型,在特定任务上超越GPT-4,体现出了多个大模型互帮互助的强大能力,而且成本也能控制在GPT-4一半的水品。
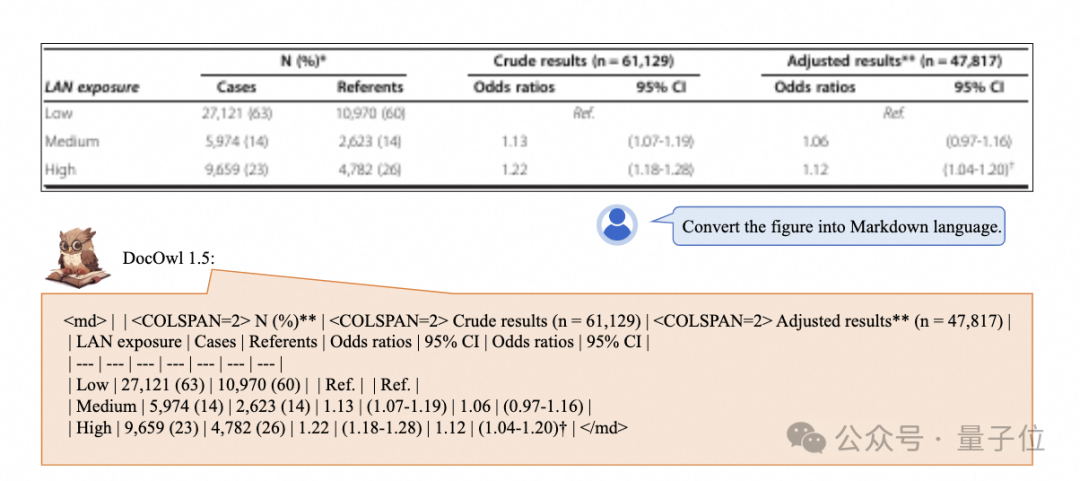
多模态文档理解能力新SOTA!阿里mPLUG团队发布最新开源工作mPLUG-DocOwl 1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。

大模型长文本能力测试,又有新方法了!

作为 Meta 的前 CTO,Quora CEO Adam D'Angelo 目前还是 OpenAI 的董事会成员,在 Quora 之外推出的 Poe,成为当下接入大模型最多的 Chatbot 平台:GPT-4、Claude3、Mistral 等模型都有,用户也可以在上面搭建自己的 Chatbot 机器人,如果有别的用户使用,还可以产生收益。

如何利用 Agent 解决医疗大模型患者真实偏好的痛点?医患沟通能否更高效?医疗诊断能否更精准?AI 能否进一步释放医疗领域新的可能性?华中科技大学陈伟教授的 AI Hospital 给我们带来了启发。Enjoy

“你能算出一个苹果有多少种子,但是永远不知道一颗种子能结多少苹果。” 科技也是一样。 很多时候,我们将科技看为一个结果,一个苹果,但其实科技是一颗种子,是一个开始。绿洲相信人工智能带来的社会变革,绿洲更加相信人工智能只是整个人类进入智能时代的其中一个截面,而具身智能正是另外一个截面。

JAX在最近的基准测试中的性能已经不声不响地超过了Pytorch和TensorFlow,也许未来会有更多的大模型诞生在这个平台上。谷歌在背后的默默付出终于得到了回报。
LLM战场的新玩家,一出手就是王炸!信仰Scaling Law的阶跃星辰,一口气带来了Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型,以及Step-2万亿参数MoE语言大模型的预览版。而阶跃星辰之旅,终点就是AGI。

3 月 28 日,云天励飞举办 AI 大模型产品发布会,发布“深目”AI 模盒,同时宣布自研大模型“云天天书-2.0-68B”版本免费向合作伙伴开放。

澜舟科技官宣:孟子3-13B大模型正式开源!这一主打高性价比的轻量化大模型,面向学术研究完全开放,并支持免费商用。