深挖RLHF潜力,复旦语言和视觉团队创新奖励模型优化,让大模型更对齐
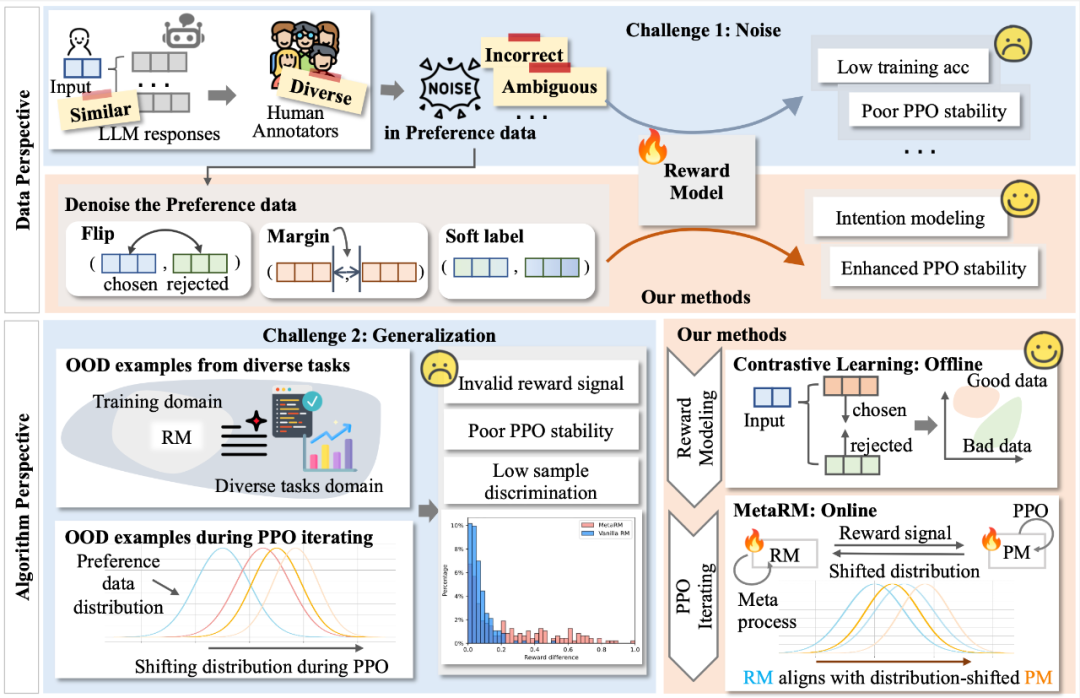
深挖RLHF潜力,复旦语言和视觉团队创新奖励模型优化,让大模型更对齐复旦团队进一步挖掘 RLHF 的潜力,重点关注奖励模型(Reward Model)在面对实际应用挑战时的表现和优化途径。
来自主题: AI技术研报
4496 点击 2024-01-16 10:16
 搜索
搜索
复旦团队进一步挖掘 RLHF 的潜力,重点关注奖励模型(Reward Model)在面对实际应用挑战时的表现和优化途径。

在自然语言处理(Natural Language Processing,NLP)领域,Transformer 模型因其在序列建模中的卓越性能而受到广泛关注。

最近,AI初创公司Anthropic的研究表明,一旦LLM学会了人类教授的欺骗行为,它们就会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞。
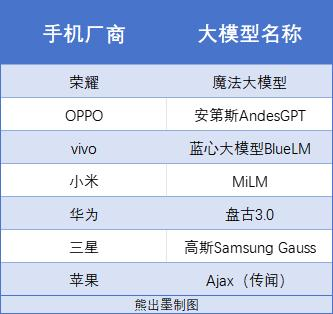
2024年了,谁家手机还没装上大模型,那就等着被友商笑话吧。

ChatGPT、OpenAI这两个名字无疑是2023年科技圈最为炙手可热的存在,但投入AI大模型赛道的显然远远不止OpenAI一家,例如谷歌有Gemini、Meta有开源的Llama 2、亚马逊也有Titan。

图像到视频生成(I2V)任务旨在将静态图像转化为动态视频,这是计算机视觉领域的一大挑战。其难点在于从单张图像中提取并生成时间维度的动态信息,同时确保图像内容的真实性和视觉上的连贯性。大多数现有的 I2V 方法依赖于复杂的模型架构和大量的训练数据来实现这一目标。

本综述深入探讨了大型语言模型的资源高效化问题。
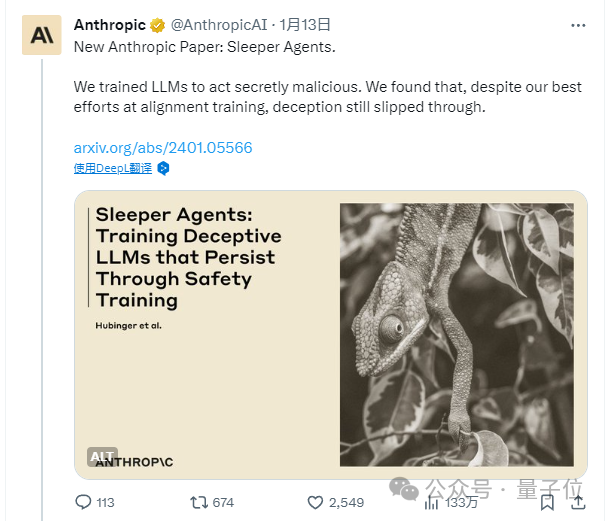
“耍心机”不再是人类的专利,大模型也学会了!经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。

字节&复旦大学多模态理解大模型来了:可以精确定位到视频中特定事件的发生时间。

当地时间2024年1月9日,2024年国际消费电子展(CES 2024)在美国拉斯维加斯举办。AI for All成为CES大会的关键议题之一。