
那个逼得我喊“救命”的AI客服,终于活出“人样”了。
那个逼得我喊“救命”的AI客服,终于活出“人样”了。我就说这个世界有点颠。 你看嗷,自打大模型爆火以来,不对,甚至在大模型爆火之前,人工智能客服就“入侵”了我们的生活。
来自主题: AI资讯
10174 点击 2025-07-24 11:09
 搜索
搜索
我就说这个世界有点颠。 你看嗷,自打大模型爆火以来,不对,甚至在大模型爆火之前,人工智能客服就“入侵”了我们的生活。

持续适应性学习,即指适应环境并提升表现的能力,是自然智能与人工智能共有的关键特征。大脑达成这一目标的核心机制在于神经递质调控(例如多巴胺DA、乙酰胆碱ACh、肾上腺素)通过设置大脑全局变量来有效防止灾难性遗忘,这一机制有望增强人工神经网络在持续学习场景中的鲁棒性。本文将概述该领域的进展,进而详述两项6月Nature发表的背靠背相关研究。

在万物互联的智能时代,具身智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力

7月23日,夸克健康大模型成功通过中国12门核心学科的主任医师笔试评测,成为国内首个完成这一挑战的大模型。离上次通过12门副主任医师职称考试仅仅隔了两个月。
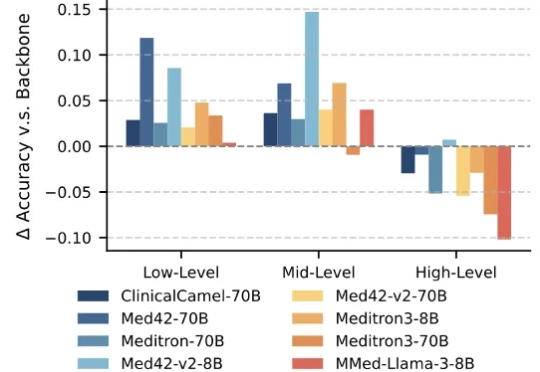
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。

你有没有过这样的瞬间:写不完的总结、画不完的PPT、改三遍还会出错的表单……不是太难,就是太烦,做完没成就感,做慢了还影响进度。
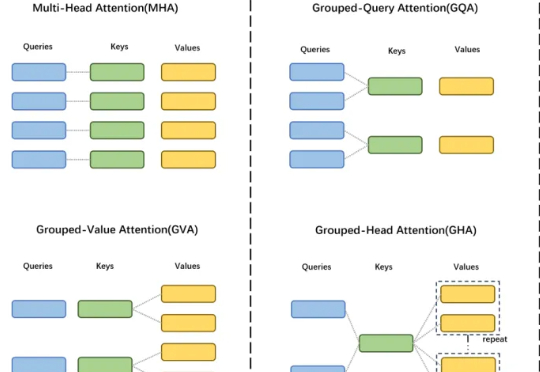
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。

AI创造力源于架构缺陷带来的约束(局部性与平移等变性),而非数据堆砌或“涌现”智能。这种约束类似人类“功能固着”的反面,迫使AI重组局部特征,从而创新。提升AI创新可主动设计约束架构、制造数据信息差、优化提示词。这挑战了追求AGI需模仿人脑的假设。

编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
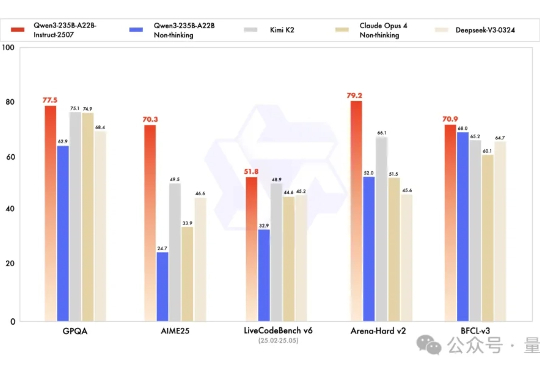
开源大模型正在进入中国时间。 Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。 基准测试性能上却超越了Kimi K2。