信息过载时代,如何真正「懂」LLM?从MIT分享的50个面试题开始
信息过载时代,如何真正「懂」LLM?从MIT分享的50个面试题开始人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。
来自主题: AI技术研报
10179 点击 2025-06-25 10:37
 搜索
搜索
人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。

AI正在彻底改变研发文明,突破传统创新瓶颈。它通过生成创新设计、加速验证评估和高效整合隐性知识,解决成本剧增问题。AI已应用在软件、生命科学等多元行业,打造研发飞轮式正反馈系统,推动人机协作和可扩展创新。
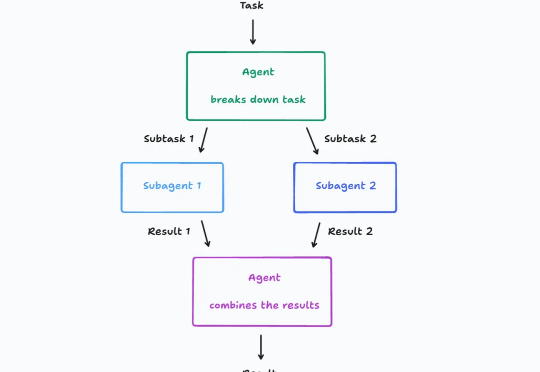
大模型驱动的 AI 智能体(Agent)架构最近讨论的很激烈,其中一个关键争议点在于: 多智能体到底该不该建?
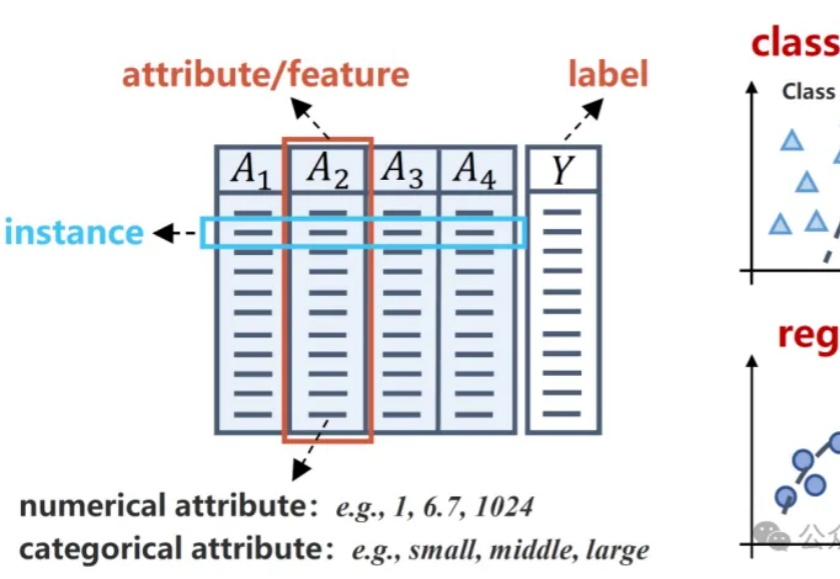
在AI应用中,表格数据的重要性愈发凸显,广泛应用于金融、医疗健康、教育、推荐系统及科学研究领域。
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。

6月23日,山西临汾市人民医院发布了《基于DeepSeek AI大模型的智慧医疗应用系统建设项目》,预算金额为1569.264万元,预计采购时间为2025年9月。临汾市人民医院拟采购基于DeepSeek的智慧医疗项目建设一套,其建设内容包含:

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。
由数据分析领域资深人士联合创立的初创公司 Typedef, 今日结束隐匿运营状态 ,宣布获得由 Pear VC 领投的 550 万美元种子轮融资。
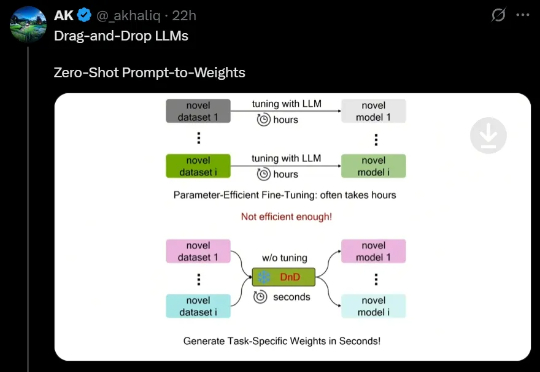
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

根据申妈朋友圈,字节跳动发布了新一期廉政通报,披露了一起涉及 Seed 团队高层的严重违规事件。据报道,Seed 大语言模型负责人乔木与其团队所配属的一名 HRBP 在未履行申报流程的情况下,发展成为亲密关系。